[PYTHON] Machine learning facile avec AutoAI (partie 4) Jupyter Notebook
introduction
Avec AutoAI, que nous avons déjà introduit, la fonction d'exportation du modèle créé vers Jupyter Notebook est enfin disponible. Dans cet article, en tant que quatrième opus de la série "Easy Machine Learning with AutoAI", nous allons essayer cette fonction.
Pour les articles précédents, veuillez vous référer aux liens ci-dessous.
Préparation à l'apprentissage automatique facile avec AutoAI (partie 1) Apprentissage automatique facile avec la construction de modèles AutoAI (partie 2) Apprentissage automatique facile avec les services Web AutoAI (partie 3)
supposition
Dans la procédure suivante, on suppose que vous avez terminé «Easy Machine Learning with AutoAI (Part 2) Model Construction» dans la série ci-dessus. (Partie 3) n'est pas obligatoire.
Exporter le bloc-notes
Lorsque la construction du modèle est terminée dans (Partie 2), l'écran tel que montré dans la figure ci-dessous s'affiche. (L'écran a changé d'avant en raison de la mise à niveau de la version)
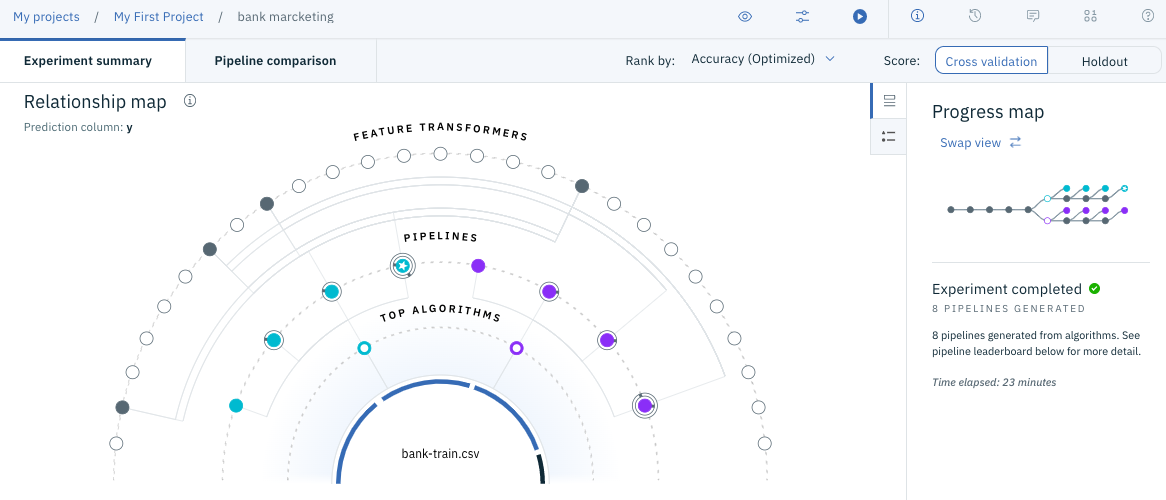
Faites défiler l'écran pour voir une liste des modèles créés, comme illustré dans la figure suivante.
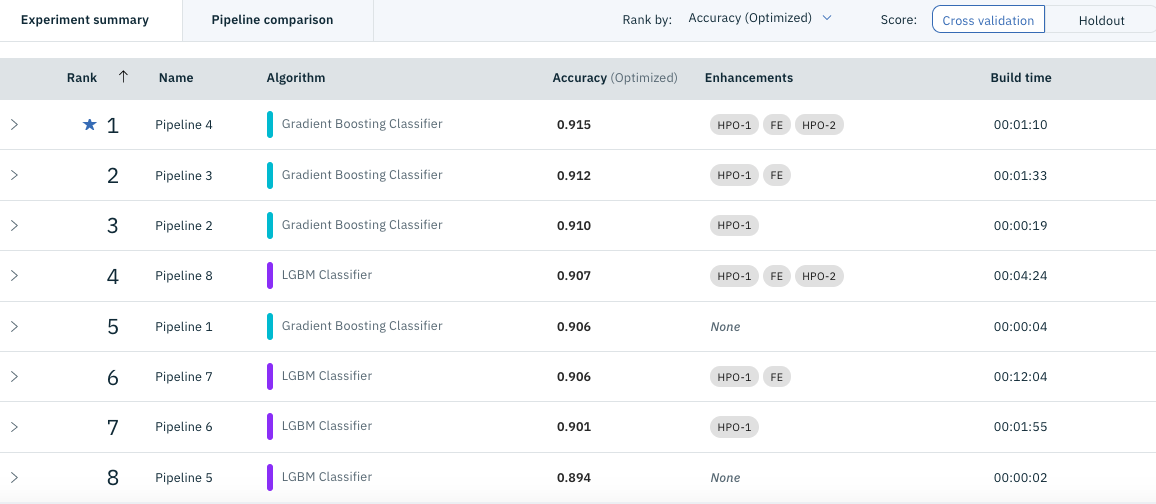
Ici, si vous déplacez le pointeur de la souris vers le côté droit du modèle que vous souhaitez exporter (généralement en haut), le menu "** Enregistrer sous **" sera affiché, alors cliquez dessus et il ressemblera à la figure ci-dessous. Je vais.
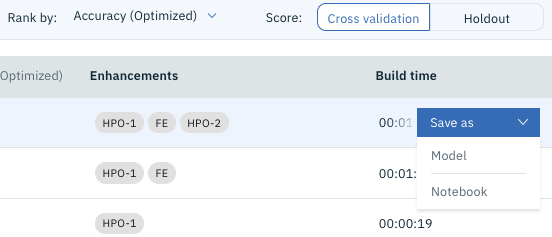
Ici, sélectionnez "Notebook" ci-dessous. Vous devriez voir un écran comme celui ci-dessous.
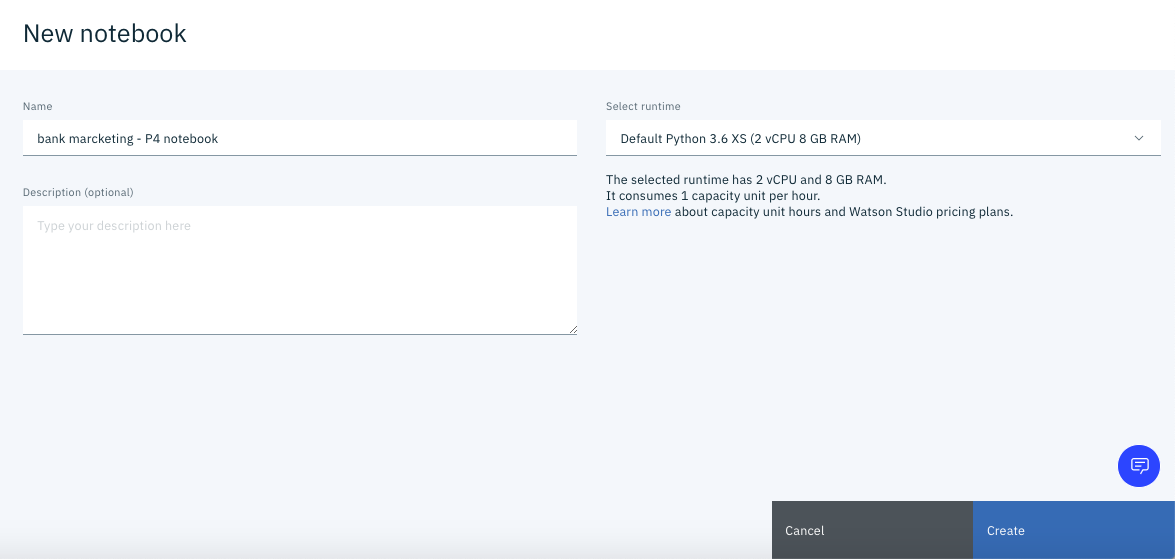
Cliquez sur «** Créer **» en bas à droite de l'écran.
Attendez un moment, et si l'écran ci-dessous apparaît, vous avez réussi l'exportation. (Remarque: à partir du 03/04/2020, il semble toujours instable et peut échouer en cours de route. Dans ce cas, veuillez réessayer.)
À ce stade, le bloc-notes est prêt à fonctionner comme code pour le bloc-notes Jupyter sur Watson Studio. Cependant, ce n'est pas très intéressant, donc j'aimerais l'exécuter en externe (Jupyter Notebook sur Mac PC). Pour ce faire, cliquez sur l'icône ** télécharger ** incluse dans le cadre rouge de la figure ci-dessous. Le téléchargement devrait démarrer automatiquement.
Pour référence, l'exemple du bloc-notes exporté est téléchargé ci-dessous. Lien vers le bloc-notes
Préparation du côté environnement du notebook Jupyter
Ensuite, préparez l'environnement côté PC. Dans mon cas, j'ai installé et utilisé anacoda (4.8.1) il y a quelque temps sur mon PC Mac. Je ne l'ai pas confirmé dans d'autres environnements, mais je pense que cela fonctionne dans presque la même procédure. Le modèle AutoAI est basé sur l'hypothèse qu'il existe une bibliothèque pour AutoAI au moment de l'exécution, mais le fait est que ** cette bibliothèque est ouverte au public sur le net et peut être installée normalement avec la commande pip **. Plus précisément, exécutez la commande suivante.
$ pip install autoai-libs -U
(Cette bibliothèque semble être mise à jour quotidiennement, et même si elle est déjà installée, il est préférable de la mettre à jour lorsque vous utilisez notebook. Je suis resté coincé avec cela.)
En plus de cela, dans l'environnement anaconda par défaut
$ pip install lightgbm
$ pip install xgboost
Je pense que j'en avais également besoin. (La mémoire est un peu vague) Il peut y avoir d'autres bibliothèques qui manquent au moment de l'exécution, mais l'important est que ** seules les bibliothèques publiées sur le net peuvent couvrir toutes les bibliothèques requises pour construire le modèle AutoAI **.
Exécution du modèle dans Jupyter Notebook
Maintenant, exécutons le modèle exporté dans l'environnement Jupyter sur le PC.
Maintenant, quand je regarde le code dans Notebook, si les trois bibliothèques ci-dessus ne sont pas dans la première cellule, elles sont automatiquement installées. Sinon, les étapes ci-dessus peuvent ne pas être nécessaires.
Pré-modification du cahier
Si vous souhaitez l'exécuter sur votre Jupyter local, veuillez modifier les deux parties suivantes du bloc-notes généré automatiquement.
Partie accès COS
Les cellules ci-dessous permettent de télécharger des fichiers CSV enregistrés dans COS (Cloud Object Storage) et ne sont pas nécessaires pour une utilisation locale. Je ne fais pas attention, je vais donc le supprimer.

Ajouter une définition de fichier local
Définissez le fichier CSV d'apprentissage dans la variable `` lisible '' dans la cellule ci-dessous. Copiez le fichier CSV dans le même répertoire que Notebook.

Courir
Après avoir terminé les deux préparations ci-dessus, vous devriez être en mesure de créer et d'évaluer le modèle en exécutant les cellules dans l'ordre du haut. J'ai joint un exemple d'image du résultat.
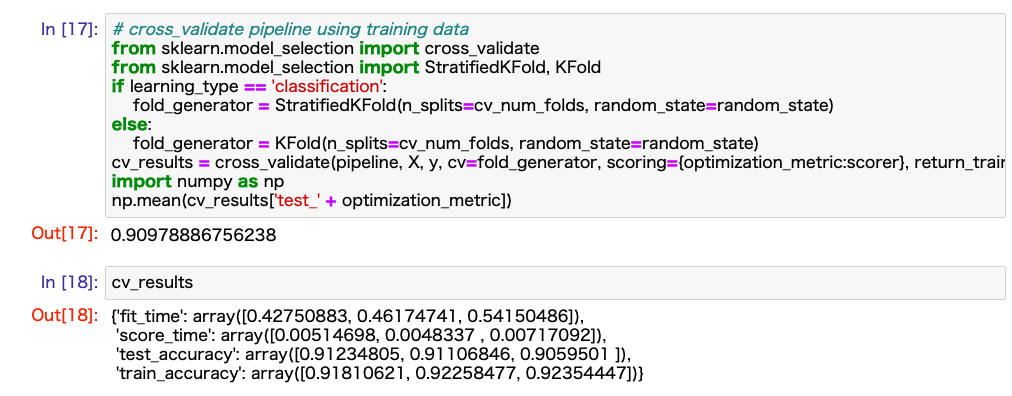
prime
Exécution des tests avec données de vérification
Copiez le code ci-dessous dans la cellule inférieure du bloc-notes ci-dessus. Avec les mêmes 40 000 données de vérification utilisées dans (3), vous pouvez appeler le modèle et vérifier le résultat de l'évaluation de la précision. Notez que les données d'entrée du modèle (Pipeline) doivent utiliser le résultat prétraité.
L'échantillon de résultat final est joint ci-dessous.
Le code ci-dessous a également été téléchargé sur github. Code d'ajout du carnet
#Vérification de l'exactitude avec 40000 données de vérification préparées à l'avance
%matplotlib inline
#Introduction des bibliothèques requises
!pip install japanize-matplotlib | tail -n 1
#Importation des bibliothèques requises
import matplotlib.pyplot as plt
#Localisation japonaise
import japanize_matplotlib #Localisation japonaise matplotlib
#Charger dans la trame de données
csv_url = 'https://raw.githubusercontent.com/makaishi2/sample-data/master/data/bank-test.csv'
df_bank_test = pd.read_csv(csv_url)
#Vérifiez le résultat
print('')
print('Données CSV pour vérification')
display(df_bank_test.head())
#Extraction des bonnes réponses correctes
correct = df_bank_test.y.values
#Création d'un tableau de données d'entrée
df_sub = df_bank_test.copy()
#Supprimer la colonne de variable d'objectif
df_sub = df_sub.drop('y', axis=1)
#Vérifiez le résultat
print('')
print('Données d'entrée du modèle')
display(df_sub.head())
#Mise en œuvre des prévisions
X_prep = preprocessing_pipeline.transform(df_sub.values)
predict = pipeline.predict(X_prep)
#Vérifiez le résultat
print('')
print('Résultat de la prédiction')
display(predict[:10])
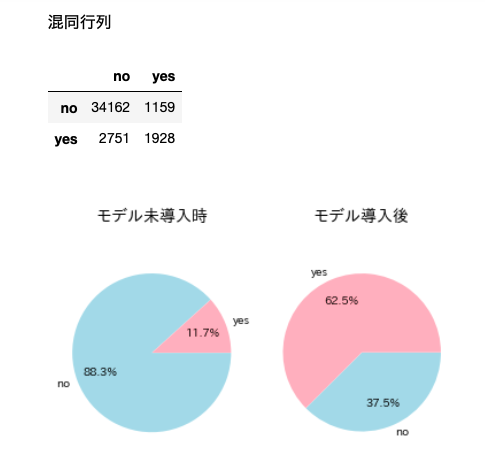
#Calcul de la matrice de confusion
from sklearn.metrics import confusion_matrix
matrix = confusion_matrix(correct, predict)
df_matrix = pd.DataFrame(matrix, columns=['no', 'yes'], index=['no', 'yes'])
###Affichage matriciel confus
print()
print('Matrice confuse')
display(df_matrix)
#Calcul du nombre de oui et de non dans les données de réponse correctes
y_count = np.count_nonzero(correct == 'yes')
n_count = np.count_nonzero(correct == 'no')
#Nombre de oui et de non dans les données de réponse correcte parmi ceux dont la valeur prédite était oui
yy_count = df_matrix.yes.yes
yn_count = df_matrix.yes.no
#Comparaison des taux de clôture avec et sans le modèle
print()
plt.subplot(1, 2, 1)
label = ['yes', 'no']
colors = ["lightpink", "lightblue"]
x = np.array([y_count, n_count])
plt.pie(x, labels=label, colors=colors,
autopct="%1.1f%%", pctdistance=0.7)
plt.title('Lorsque le modèle n'est pas présenté', fontsize=14)
plt.axis('equal')
plt.subplot(1, 2, 2)
label = ['yes', 'no']
colors = ["lightpink", "lightblue"]
x = np.array([yy_count, yn_count])
plt.pie(x, labels=label, colors=colors,
autopct="%1.1f%%", pctdistance=0.7)
plt.title('Après l'introduction du modèle', fontsize=14)
plt.axis('equal')
plt.show()
Recommended Posts