[PYTHON] Démarrez avec l'apprentissage automatique avec SageMaker
introduction
Créez et déployez un modèle d'apprentissage automatique selon le document officiel AWS Comment démarrer avec Amazon SageMaker J'ai décidé de pratiquer le flow jusqu'à.
Je publierai cet article comme mon propre mémo d'apprentissage pratique.
table des matières
- [Qu'est-ce que l'apprentissage automatique](#Qu'est-ce que l'apprentissage automatique)
- [Présentation de SageMaker](# Présentation de SageMaker)
- Tutoriel
- Conclusion
Qu'est-ce que l'apprentissage automatique?
Omis ici. Voir ci-dessous pour un aperçu.
Apprentissage automatique à partir de zéro (présentation de l'apprentissage automatique)
Présentation de SageMaker
Pour plus d'informations, consultez la [documentation Amazon SageMaker] officielle d'AWS (https://docs.aws.amazon.com/sagemaker/index.html).
Amazon SageMaker est un service d'apprentissage automatique entièrement géré. Amazon SageMaker permet aux spécialistes des données et aux développeurs de créer et de former rapidement et facilement des modèles d'apprentissage automatique et de les déployer directement dans un environnement hébergé prêt à l'emploi. Accédez facilement aux sources de données pour la recherche et l'analyse à partir d'une instance de bloc-notes de création Jupyter intégrée, éliminant ainsi le besoin de gérer un serveur. Vous pouvez également utiliser des algorithmes d'apprentissage automatique courants. Ces algorithmes sont optimisés pour fonctionner efficacement même sur des volumes de données extrêmement importants dans des environnements distribués. Avec la prise en charge native de vos propres algorithmes et frameworks, Amazon SageMaker propose également une formation flexible et distribuée qui peut être adaptée à votre flux de travail spécifique. Lancez votre modèle dans un environnement sécurisé et évolutif en un seul clic depuis Amazon SageMaker Studio ou la console Amazon SageMaker. La formation et l'hébergement sont facturés minute par minute. Il n'y a pas de frais minimum ni d'obligation de paiement anticipé.
(Extrait de https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/whatis.html)
Comme vous pouvez le voir sur l'illustration de SageMaker, il existe plusieurs instances, mais quels sont leurs rôles? → Les documents publiés par le responsable AWS étaient faciles à comprendre, ils sont donc décrits ci-dessous.
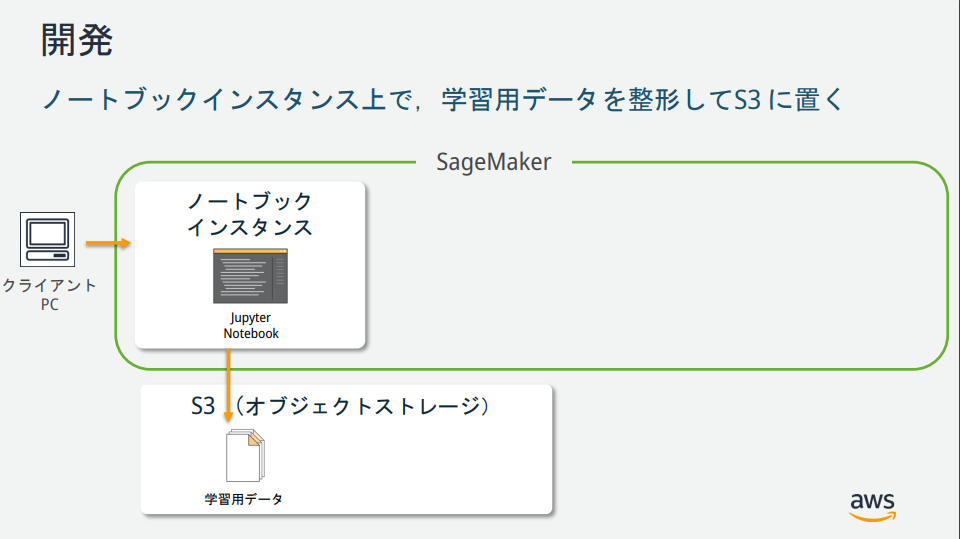
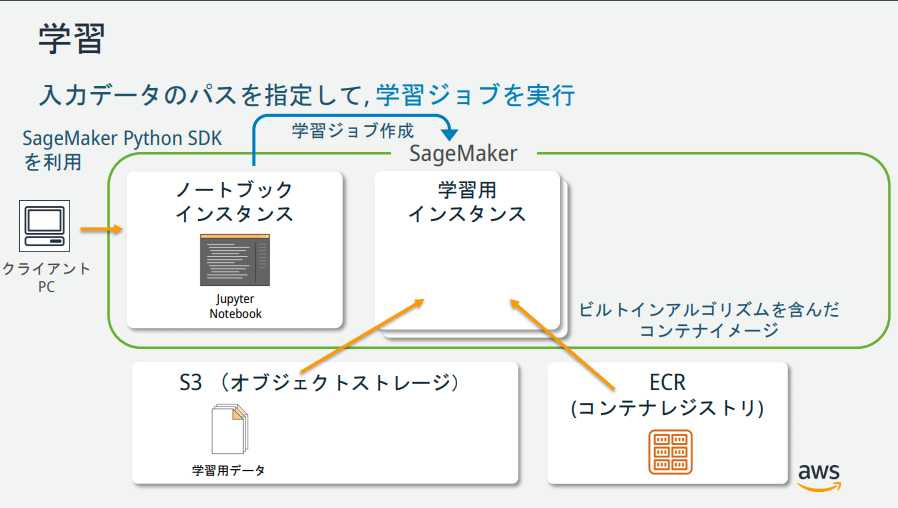
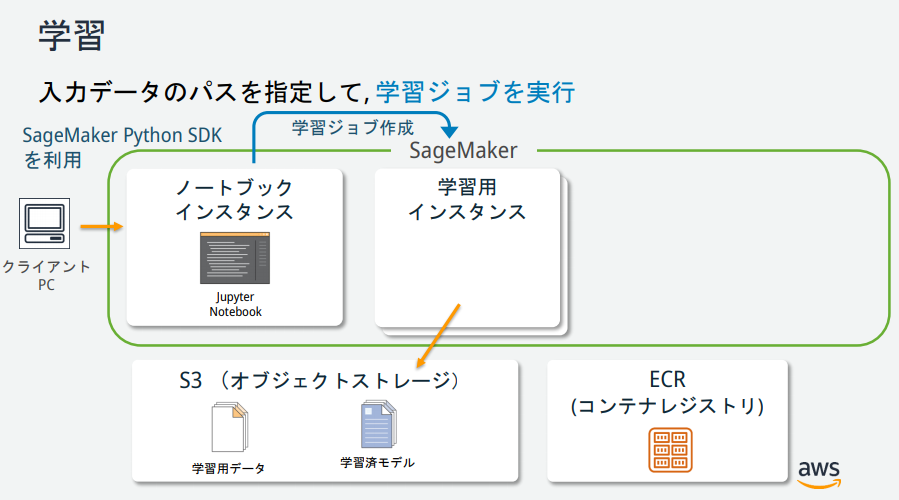
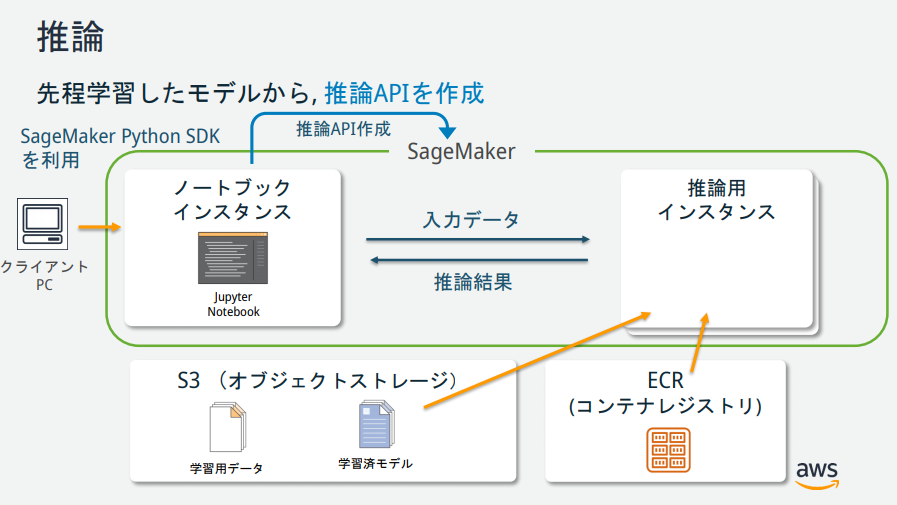
(Extrait de https://pages.awscloud.com/event_JAPAN_hands-on-ml_ondemand_confirmation.html)
Didacticiel
Implémentation du [Tutoriel] officiel d'AWS (https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/gs.html).
Créer un compartiment Amazon S3
Créez un espace (compartiment) pour stocker les données utilisées pour l'apprentissage automatique et le résultat de la formation (modèle).
Création d'une instance de notebook Amazon SageMaker
Une instance de notebook Amazon SageMaker est une instance de calcul EC2 de machine learning entièrement gérée sur laquelle Jupyter Notebook est installé.
Créer un notebook Jupyter
Qu'est-ce qu'un notebook Jupyter?
Un outil open source qui vise à gérer de manière centralisée la création de programmes, les résultats d'exécution, les graphiques, les notes de travail et les documents associés dans un format de fichier appelé notebook. Ceci est particulièrement utile lorsque vous souhaitez exécuter un programme de manière interactive et effectuer le travail suivant tout en vous référant au résultat, ou lorsque vous souhaitez enregistrer le résultat de sortie et le conserver sous forme d'enregistrement de travail avec un mémo, comme dans le cadre d'un travail d'analyse de données. Est.
(Extrait de https://www.seplus.jp/dokushuzemi/blog/2020/04/tech_words_jupyter_notebook.html)
Sélectionnez "conda_python3" dans "Nouveau". Un nouveau bloc-notes est créé.

Écrivez du code pour spécifier S3 et le rôle.
from sagemaker import get_execution_role
role = get_execution_role()
bucket='0803-sagemaker-sample'
Téléchargez, examinez et convertissez des données
Téléchargez le jeu de données MNIST
Que sont les données MNIST?
MNIST (Mixed National Institute of Standards and Technology Database) est un ensemble de données d'images qui rassemble 60 000 images numériques manuscrites et 10 000 images de test. En outre, il s'agit également d'un ensemble de données dans lequel l'étiquette de réponse correcte est donnée aux nombres manuscrits «0 à 9», qui est un ensemble de données populaire pour les problèmes de classification d'images.
(Extrait de https://udemy.benesse.co.jp/ai/mnist.html)
Écrivez le code pour télécharger le jeu de données MNIST.
%%time
import pickle, gzip, numpy, urllib.request, json
# Load the dataset
urllib.request.urlretrieve("http://deeplearning.net/data/mnist/mnist.pkl.gz", "mnist.pkl.gz")
with gzip.open('mnist.pkl.gz', 'rb') as f:
train_set, valid_set, test_set = pickle.load(f, encoding='latin1')
Examiner l'ensemble de données d'entraînement
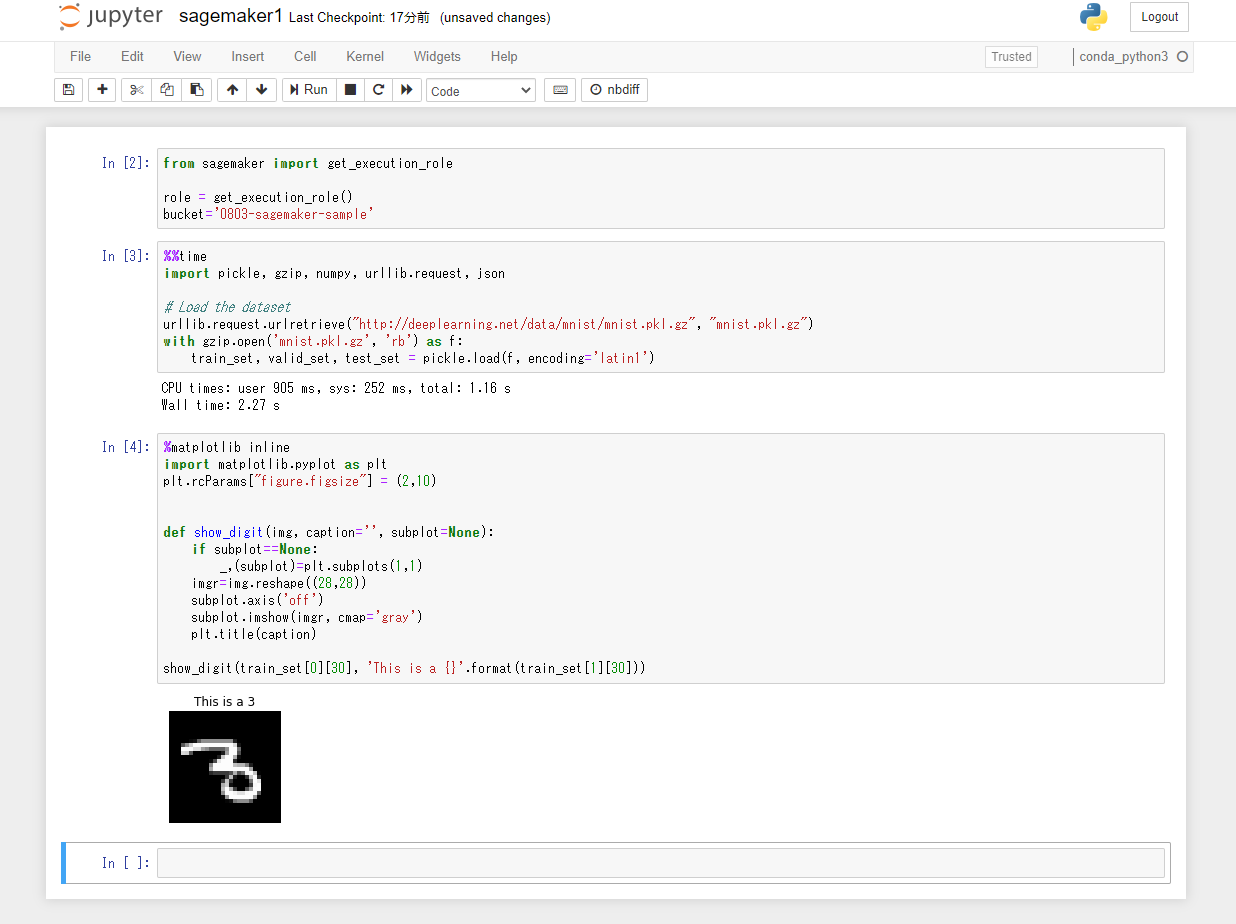
Collez le code Python suivant dans la troisième cellule et cliquez sur le bouton "Exécuter". Les 31e données d'image du jeu de données MNIST sont affichées avec le contenu de l'étiquette.
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (2,10)
def show_digit(img, caption='', subplot=None):
if subplot==None:
_,(subplot)=plt.subplots(1,1)
imgr=img.reshape((28,28))
subplot.axis('off')
subplot.imshow(imgr, cmap='gray')
plt.title(caption)
show_digit(train_set[0][30], 'This is a {}'.format(train_set[1][30]))
Former le modèle
Choisissez un algorithme d'entraînement
L'apprentissage automatique nécessite généralement un processus d'évaluation pour trouver un algorithme adapté au modèle. Cette fois, nous avons décidé d'utiliser k-means, qui est l'un des algorithmes intégrés de SageMaker, nous allons donc sauter le processus d'évaluation.
Qu'est-ce que k-signifie
La méthode K-means est l'un des algorithmes standard pour le clustering. Les détails sont omis ici.
Créer un emploi de formation
Collez le code Python suivant dans la 4ème cellule et cliquez sur le bouton "Exécuter".
from sagemaker import KMeans
data_location = 's3://{}/kmeans_highlevel_example/data'.format(bucket)
output_location = 's3://{}/kmeans_example/output'.format(bucket)
print('training data will be uploaded to: {}'.format(data_location))
print('training artifacts will be uploaded to: {}'.format(output_location))
kmeans = KMeans(role=role,
train_instance_count=2,
train_instance_type='ml.c4.8xlarge',
output_path=output_location,
k=10,
data_location=data_location)
Exécution de la formation
Effectuer une formation de modèle. Collez le code Python suivant dans la 5ème cellule et cliquez sur le bouton "Exécuter". La formation dure environ 10 minutes.
%%time
kmeans.fit(kmeans.record_set(train_set[0]))
Si vous vérifiez S3 une fois que le modèle a été formé, vous trouverez les données d'entraînement du modèle et les artefacts de modèle générés pendant l'apprentissage du modèle.
Déployer le modèle sur Amazon SageMaker
Pour déployer le modèle sur SageMaker, vous devez effectuer les trois étapes suivantes.
--Créer un modèle sur SageMaker --Création des paramètres de point de terminaison --Créer un point de terminaison
Vous pouvez faire ces choses avec une seule méthode appelée deploy. Collez le code Python suivant dans la 6ème cellule et cliquez sur le bouton "Exécuter".
%%time
kmeans_predictor = kmeans.deploy(initial_instance_count=1,
instance_type='ml.m4.xlarge')
Valider le modèle
Puisque le modèle a été déployé, vérifiez-le. Collez le code Python suivant dans la 7ème cellule et cliquez sur le bouton "Exécuter".
result = kmeans_predictor.predict(valid_set[0][28:29])
print(result)
Le résultat de l'inférence pour la 30e image de l'ensemble de données valid_set est obtenu. On peut voir que la 28e donnée de valid_set appartient au cluster 6.
[label {
key: "closest_cluster"
value {
float32_tensor {
values: 6.0
}
}
}
label {
key: "distance_to_cluster"
value {
float32_tensor {
values: 6.878328800201416
}
}
}
]
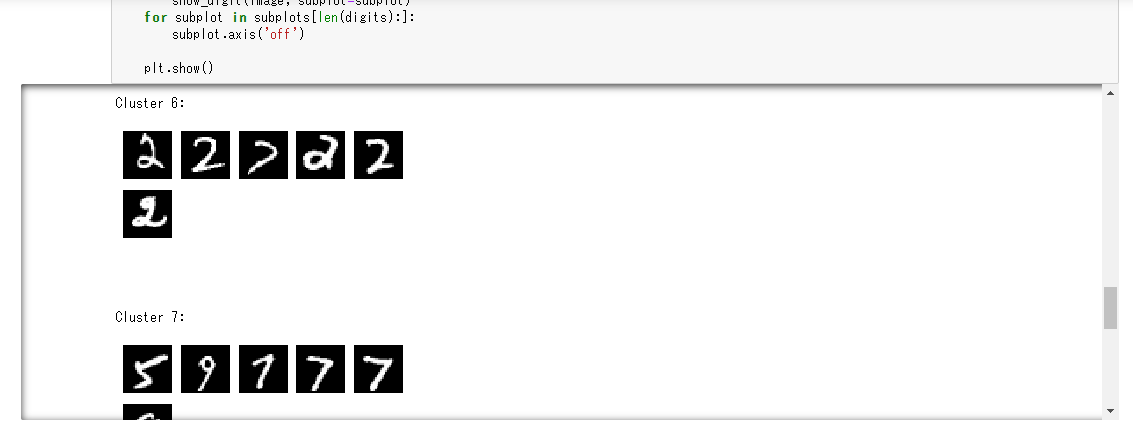
Ensuite, les résultats de l'inférence pour 100 pièces à partir du début de l'ensemble de données valid_set sont acquis. Collez le code Python suivant dans les 8ème et 9ème cellules et cliquez sur le bouton "Exécuter" dans l'ordre.
%%time
result = kmeans_predictor.predict(valid_set[0][0:100])
clusters = [r.label['closest_cluster'].float32_tensor.values[0] for r in result]
for cluster in range(10):
print('\n\n\nCluster {}:'.format(int(cluster)))
digits = [ img for l, img in zip(clusters, valid_set[0]) if int(l) == cluster ]
height = ((len(digits)-1)//5) + 1
width = 5
plt.rcParams["figure.figsize"] = (width,height)
_, subplots = plt.subplots(height, width)
subplots = numpy.ndarray.flatten(subplots)
for subplot, image in zip(subplots, digits):
show_digit(image, subplot=subplot)
for subplot in subplots[len(digits):]:
subplot.axis('off')
plt.show()
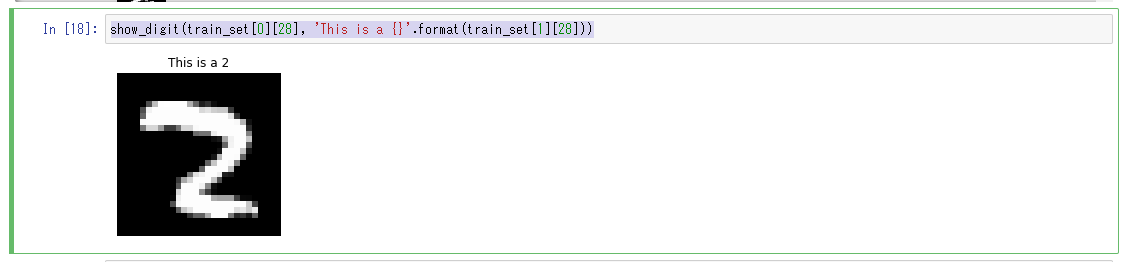
Affichez le 28e de l'ensemble de données valid_set à l'aide de la méthode show_digit utilisée dans «Examen de l'ensemble de données d'entraînement». Vous pouvez voir qu'il s'agit d'une image incluse dans le cluster 4.
show_digit(train_set[0][28], 'This is a {}'.format(train_set[1][28]))
Terminé car le modèle a été déployé et il a été vérifié qu'il fonctionnait.
Supprimer la ressource AWS que vous avez créée
Supprimé tranquillement. Il n'y a rien de spécial à mentionner.
en conclusion
Cette fois, j'ai utilisé SagrMaker et essayé le premier machine learning. L'apprentissage automatique avait une image de barrières élevées, mais il était plus facile à utiliser que je ne l'avais imaginé.
En regardant les annonces récentes de chaque cloud public, j'ai l'impression qu'ils essaient d'abaisser le seuil du machine learning. (Je pense que des compétences d'ingénieur spécialisé en apprentissage automatique sont nécessaires pour une analyse de haut niveau) Pour un certain niveau d'apprentissage automatique, même les non-ingénieurs spécialisés dans l'apprentissage automatique peuvent utiliser des services gérés et avoir un sens de la vitesse. Je pense que des compétences à développer seront nécessaires, alors j'aimerais continuer à apprendre sur l'apprentissage automatique.
Matériel de référence
Comment démarrer Amazon SageMaker [Pour les débutants] Apprentissage automatique à partir d'Amazon SageMaker #SageMaker Expérience pratique d'Amazon SageMaker pour les ingénieurs en apprentissage automatique
Recommended Posts