[PYTHON] 100 Language Processing Knock 2020 Chapter 10: Machine Translation (90-98)
The other day, 100 Language Processing Knock 2020 was released. I myself have only been in natural language processing for a year, and I don't know the details, but I will solve all the problems and publish them in order to improve my technical skills.
All shall be executed on jupyter notebook, and the restrictions of the problem statement may be broken conveniently.
The source code is also on github. Yes.
Chapter 9 is here.
I used Python 3.8.2. I used 4 Tesla V100 for GPU.
Chapter 10: Machine Translation
In this chapter, a neural machine translation model is constructed using the Kyoto Free Translation Task (KFTT), which is a Japanese-English translation corpus. To do. To build a neural machine translation model, fairseq, Hugging Face Transformers, [OpenNMT-py] Take advantage of existing tools such as (https://github.com/OpenNMT/OpenNMT-py).
Use fairseq for the library.
The final 99th question is the question of creating a web application. It is impossible to do it with jupyter notebook, so I will do it in another article.
90. Data preparation
Download the machine translation dataset. Format training data, development data, and evaluation data, and perform preprocessing such as tokenization as necessary. However, at this stage, use morphemes (Japanese) and words (English) as token units.
Download the KFTT data and unzip it.
tar zxvf kftt-data-1.0.tar.gz
Tokenize the data on the Japanese side with GiNZA.
cat kftt-data-1.0/data/orig/kyoto-train.ja | sed 's/\s+/ /g' | ginzame > train.ginza.ja
cat kftt-data-1.0/data/orig/kyoto-dev.ja | sed 's/\s+/ /g' | ginzame > dev.ginza.ja
cat kftt-data-1.0/data/orig/kyoto-test.ja | sed 's/\s+/ /g' | ginzame > test.ginza.ja
for src, dst in [
('train.ginza.ja', 'train.spacy.ja'),
('dev.ginza.ja', 'dev.spacy.ja'),
('test.ginza.ja', 'test.spacy.ja'),
]:
with open(src) as f:
lst = []
tmp = []
for x in f:
x = x.strip()
if x == 'EOS':
lst.append(' '.join(tmp))
tmp = []
elif x != '':
tmp.append(x.split('\t')[0])
with open(dst, 'w') as f:
for line in lst:
print(line, file=f)
It is a bad attitude to set the output file to "~ .spacy.ja", but I feel that it is okay because I did so. You can create data like this.
Sesshu (Sesshu, 1420 (Oei 27))-1506 (3rd year of Eisho)) is an issue, an ink painter and Zen priest who was active in the Muromachi period in the latter half of the 15th century, and is also called a painting sacred.
It changed the Japanese ink painting completely.
諱 was called "Toyo" or "Sesshu".
Born in Btsutyuu, he moved to Suo Province after entering Kyoto and Sokokuji Temple.
After that, he accompanied the envoy to Ming and went to China (Ming) to study Chinese ink painting.
There are many works, not only Chinese-style landscape paintings, but also portraits and bird-and-flower paintings.
The bold composition and powerful brush strokes create a very unique style of painting.
Six of the existing works have been designated as national treasures, and it can be said that they have received exceptional evaluation among Japanese-style painters.
For this reason, there are a large number of works that are referred to as "Sesshu-brush" in the bird-and-flower painting screen.
There are many disagreements among experts, whether they are autographs or not.
Tokenize the data on the English side with SpaCy.
import re
import spacy
nlp = spacy.load('en')
for src, dst in [
('kftt-data-1.0/data/orig/kyoto-train.en', 'train.spacy.en'),
('kftt-data-1.0/data/orig/kyoto-dev.en', 'dev.spacy.en'),
('kftt-data-1.0/data/orig/kyoto-test.en', 'test.spacy.en'),
]:
with open(src) as f, open(dst, 'w') as g:
for x in f:
x = x.strip()
x = re.sub(r'\s+', ' ', x)
x = nlp.make_doc(x)
x = ' '.join([doc.text for doc in x])
print(x, file=g)
It's like this.
Known as Sesshu ( 1420 - 1506 ) , he was an ink painter and Zen monk active in the Muromachi period in the latter half of the 15th century , and was called a master painter .
He revolutionized the Japanese ink painting .
He was given the posthumous name " Toyo " or " Sesshu (My sect) . "
Born in Bicchu Province , he moved to Suo Province after entering SShokoku - ji Temple in Kyoto .
Later he accompanied a mission to Ming Dynasty China and learned Chinese ink painting .
His works were many , including not only Chinese - style landscape paintings , but also portraits and pictures of flowers and birds .
His bold compositions and strong brush strokes constituted an extremely distinctive style .
6 of his extant works are designated national treasures . Indeed , he is considered to be extraordinary among Japanese painters .
For this reason , there are a great many artworks that are attributed to him , such as folding screens with pictures of flowers and that birds are painted on them .
There are many works that even experts can not agree if they are really his work or not .
91. Machine translation model training
Learn the model of neural machine translation using the data prepared in> 90 (the model of the neural network may be selected appropriately such as Transformer or LSTM).
Preprocess with fairseq-preprocess and then train with fairseq-train.
fairseq-preprocess -s ja -t en \
--trainpref train.spacy \
--validpref dev.spacy \
--destdir data91 \
--thresholdsrc 5 \
--thresholdtgt 5 \
--workers 20
output
Namespace(align_suffix=None, alignfile=None, bpe=None, cpu=False, criterion='cross_entropy', dataset_impl='mmap', destdir='data91', empty_cache_freq=0, fp16=False, fp16_init_scale=128, fp16_scale_tolerance=0.0, fp16_scale_window=None, joined_dictionary=False, log_format=None, log_interval=1000, lr_scheduler='fixed', memory_efficient_fp16=False, min_loss_scale=0.0001, no_progress_bar=False, nwordssrc=-1, nwordstgt=-1, only_source=False, optimizer='nag', padding_factor=8, seed=1, source_lang='ja', srcdict=None, target_lang='en', task='translation', tensorboard_logdir='', testpref=None, tgtdict=None, threshold_loss_scale=None, thresholdsrc=5, thresholdtgt=5, tokenizer=None, trainpref='train.spacy', user_dir=None, validpref='dev.spacy', workers=20)
| [ja] Dictionary: 60247 types
| [ja] train.spacy.ja: 440288 sents, 11298955 tokens, 1.41% replaced by <unk>
| [ja] Dictionary: 60247 types
| [ja] dev.spacy.ja: 1166 sents, 25550 tokens, 1.54% replaced by <unk>
| [en] Dictionary: 55495 types
| [en] train.spacy.en: 440288 sents, 12319171 tokens, 1.58% replaced by <unk>
| [en] Dictionary: 55495 types
| [en] dev.spacy.en: 1166 sents, 26091 tokens, 2.85% replaced by <unk>
| Wrote preprocessed data to data91
fairseq-train data91 \
--fp16 \
--save-dir save91 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--update-freq 1 \
--dropout 0.2 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 91.log
Changes in loss during learning are output to the log.
92. Applying a machine translation model
Implement a program that translates a given (arbitrary) Japanese sentence into English using the neural machine translation model learned in> 91.
Apply the translation model to the test data with fairseq-interactive.
fairseq-interactive --path save91/checkpoint10.pt data91 < test.spacy.ja | grep '^H' | cut -f3 > 92.out
93. Measuring BLEU score
To examine the quality of the neural machine translation model learned in> 91, measure the BLEU score in the evaluation data.
Use fairseq-score. There are various types of BLEU, so it may be better to specify sacrebleu. Machine translation I don't understand anything. I hope you read the fairseq documentation.
fairseq-score --sys 92.out --ref test.spacy.en
output
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='92.out')
BLEU4 = 22.71, 53.4/27.8/16.7/10.7 (BP=1.000, ratio=1.009, syslen=27864, reflen=27625)
94. Beam search
Introduce beam search when decoding the translated sentence with the neural machine translation model learned in> 91. Plot the change in BLEU score on the development set while appropriately changing the beam width from 1 to 100.
Change the beam width from 1 to 20. Isn't it too long to get up to 100?
for N in `seq 1 20` ; do
fairseq-interactive --path save91/checkpoint10.pt --beam $N data91 < test.spacy.ja | grep '^H' | cut -f3 > 94.$N.out
done
for N in `seq 1 20` ; do
fairseq-score --sys 94.$N.out --ref test.spacy.en > 94.$N.score
done
Read the score and make a graph.
import matplotlib.pyplot as plt
def read_score(filename):
with open(filename) as f:
x = f.readlines()[1]
x = re.search(r'(?<=BLEU4 = )\d*\.\d*(?=,)', x)
return float(x.group())
xs = range(1, 21)
ys = [read_score(f'94.{x}.score') for x in xs]
plt.plot(xs, ys)
plt.show()
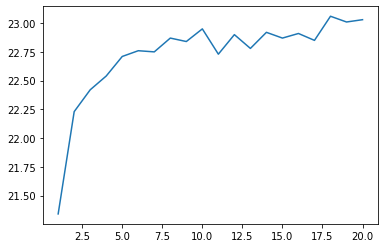
Beam search is important
95. Subwording
Change the token unit from a word or morpheme to a subword and repeat the experiment 91-94.
The Japanese side used sentencepiece.
import sentencepiece as spm
spm.SentencePieceTrainer.Train('--input=kftt-data-1.0/data/orig/kyoto-train.ja --model_prefix=kyoto_ja --vocab_size=16000 --character_coverage=1.0')
sp = spm.SentencePieceProcessor()
sp.Load('kyoto_ja.model')
for src, dst in [
('kftt-data-1.0/data/orig/kyoto-train.ja', 'train.sub.ja'),
('kftt-data-1.0/data/orig/kyoto-dev.ja', 'dev.sub.ja'),
('kftt-data-1.0/data/orig/kyoto-test.ja', 'test.sub.ja'),
]:
with open(src) as f, open(dst, 'w') as g:
for x in f:
x = x.strip()
x = re.sub(r'\s+', ' ', x)
x = sp.encode_as_pieces(x)
x = ' '.join(x)
print(x, file=g)
It's like this.
Snow boat(14 20 years(Oei 27 years)-150 6 years(Eisho 3 years) )In the issue, he was an ink painter and Zen priest who was active in the Muromachi period in the latter half of the 15th century, and is also called the Holy Painting.
It changed the Japanese ink painting.
諱 is "etc. Yang(Finally), Or "Sesshu(Sequel)".
Born in Bitchū, moved to Suo Province after entering Kyoto's Sokokuji Temple.
After that, he accompanied the envoy to China(Ming)I learned Chinese ink painting over the years.
There were many works, not only Chinese-style landscape paintings, but also portraits and bird-and-flower paintings.
The bold composition and powerful brush strokes create a very unique style.
Six of the existing works have been designated as national treasures, and it can be said that they have received exceptional evaluation among Japanese-style painters.
For this reason, there are a large number of works that have been "written by the snow boat" in the bird-and-flower painting screen.
There are many disagreements among experts, whether they are genuine or not.
The English side used subword-nmt.
subword-nmt learn-bpe -s 16000 < kftt-data-1.0/data/orig/kyoto-train.en > kyoto_en.codes
subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-train.en > train.sub.en
subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-dev.en > dev.sub.en
subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-test.en > test.sub.en
like this
K@@ n@@ own as Ses@@ shu (14@@ 20 - 150@@ 6@@ ), he was an ink painter and Zen monk active in the Muromachi period in the latter half of the 15th century, and was called a master pain@@ ter.
He revol@@ ut@@ ion@@ ized the Japanese ink paint@@ ing.
He was given the posthumous name "@@ Toyo@@ " or "S@@ es@@ shu (@@I@@So@@ )."
Born in Bicchu Province, he moved to Suo Province after entering S@@ Shokoku-ji Temple in Kyoto.
Later he accompanied a mission to Ming Dynasty China and learned Chinese ink paint@@ ing.
His works were man@@ y, including not only Chinese-style landscape paintings, but also portraits and pictures of flowers and bird@@ s.
His b@@ old compos@@ itions and strong brush st@@ rok@@ es const@@ ituted an extremely distinctive style.
6 of his ext@@ ant works are designated national treasu@@ res. In@@ de@@ ed, he is considered to be extraordinary among Japanese pain@@ ters.
For this reason, there are a great many art@@ works that are attributed to him, such as folding scre@@ ens with pictures of flowers and that birds are painted on them.
There are many works that even experts cannot ag@@ ree if they are really his work or not.
Pre-process
fairseq-preprocess -s ja -t en \
--trainpref train.sub \
--validpref dev.sub \
--destdir data95 \
--workers 20
Train
fairseq-train data95 \
--fp16 \
--save-dir save95 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--update-freq 1 \
--dropout 0.2 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 95.log
Generate
fairseq-interactive --path save95/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 95.out
Talkize to SpaCy
def spacy_tokenize(src, dst):
with open(src) as f, open(dst, 'w') as g:
for x in f:
x = x.strip()
x = ' '.join([doc.text for doc in nlp(x)])
print(x, file=g)
spacy_tokenize('95.out', '95.out.spacy')
Measure the score.
fairseq-score --sys 95.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='95.out.spacy')
BLEU4 = 20.36, 51.3/25.2/14.7/9.0 (BP=1.000, ratio=1.030, syslen=28463, reflen=27625)
lowered. I don't know.
Do a beam search.
for N in `seq 1 10` ; do
fairseq-interactive --path save95/checkpoint10.pt --beam $N data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 95.$N.out
done
for i in range(1, 11):
spacy_tokenize(f'95.{i}.out', f'95.{i}.out.spacy')
for N in `seq 1 10` ; do
fairseq-score --sys 95.$N.out.spacy --ref test.spacy.en > 95.$N.score
done
xs = range(1, 11)
ys = [read_score(f'95.{x}.score') for x in xs]
plt.plot(xs, ys)
plt.show()
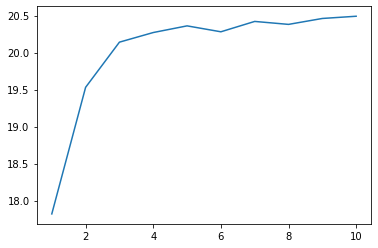
96. Visualization of learning process
Visualize the process of learning the neural machine translation model using tools such as Tensorboard. Use the loss function value and BLEU score in the training data, the loss function value and BLEU score in the development data, etc. as the items to be visualized.
You can specify --tensorboard-logdir (save path) for fairseq-train.
You can see it by doing pip install tensorborad tensorboardX, starting tensorboard, and opening localhost: 6666 (etc.).
fairseq-train data95 \
--fp16 \
--tensorboard-logdir log96 \
--save-dir save96 \
--max-epoch 5 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.2 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 96.log
I think it will be displayed like this.
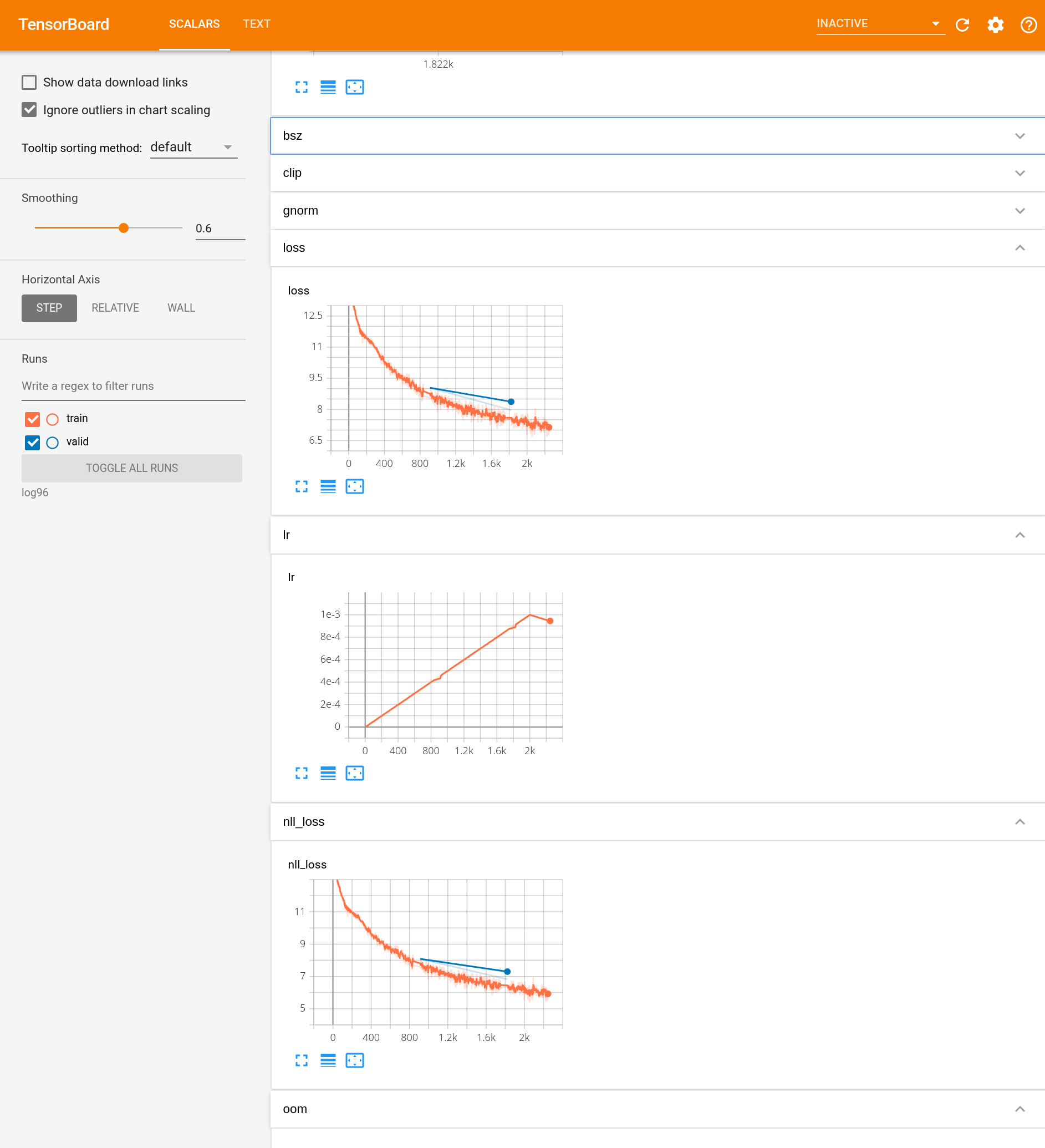
97. Hyperparameter adjustment
Find the model and hyperparameters that maximize the BLEU score in the development data while changing the neural network model and its hyperparameters.
Let's change the dropout and learning rate. I haven't done it very well. Also, I'm looking at the test data BLEU instead of the development data (not good).
fairseq-train data95 \
--fp16 \
--save-dir save97_1 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.1 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 97_1.log
fairseq-train data95 \
--fp16 \
--save-dir save97_3 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.3 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 97_3.log
fairseq-train data95 \
--fp16 \
--save-dir save97_5 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.5 --weight-decay 0.0001 \
--update-freq 1 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 97_5.log
fairseq-interactive --path save97_1/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_1.out
fairseq-interactive --path save97_3/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_3.out
fairseq-interactive --path save97_5/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_5.out
spacy_tokenize('97_1.out', '97_1.out.spacy')
spacy_tokenize('97_3.out', '97_3.out.spacy')
spacy_tokenize('97_5.out', '97_5.out.spacy')
fairseq-score --sys 97_1.out.spacy --ref test.spacy.en
fairseq-score --sys 97_3.out.spacy --ref test.spacy.en
fairseq-score --sys 97_5.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_1.out.spacy')
BLEU4 = 21.42, 51.7/26.3/15.7/9.9 (BP=1.000, ratio=1.055, syslen=29132, reflen=27625)
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_3.out.spacy')
BLEU4 = 12.99, 38.5/16.5/8.8/5.1 (BP=1.000, ratio=1.225, syslen=33832, reflen=27625)
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_5.out.spacy')
BLEU4 = 3.49, 21.8/4.9/1.8/0.8 (BP=1.000, ratio=1.122, syslen=31008, reflen=27625)
The higher the dropout rate, the lower the BLEU. Mystery
98. Domain adaptation
Japanese-English Subtitle Corpus (JESC) and JParaCrawl Try to improve the performance of KFTT test data by using translation data such as / lilg / jparacrawl /).
After learning with JParaCrawl, let's relearn with KFTT.
import tarfile
with tarfile.open('en-ja.tar.gz') as tar:
for f in tar.getmembers():
if f.name.endswith('txt'):
text = tar.extractfile(f).read().decode('utf-8')
break
data = text.splitlines()
data = [x.split('\t') for x in data]
data = [x for x in data if len(x) == 4]
data = [[x[3], x[2]] for x in data]
with open('jparacrawl.ja', 'w') as f, open('jparacrawl.en', 'w') as g:
for j, e in data:
print(j, file=f)
print(e, file=g)
Put the sentence piece on the Japanese side.
with open('jparacrawl.ja') as f, open('train.jparacrawl.ja', 'w') as g:
for x in f:
x = x.strip()
x = re.sub(r'\s+', ' ', x)
x = sp.encode_as_pieces(x)
x = ' '.join(x)
print(x, file=g)
Multiply subword-nmt on the English side.
subword-nmt apply-bpe -c kyoto_en.codes < jparacrawl.en > train.jparacrawl.en
Let me learn.
fairseq-preprocess -s ja -t en \
--trainpref train.jparacrawl \
--validpref dev.sub \
--destdir data98 \
--workers 20
fairseq-train data98 \
--fp16 \
--save-dir save98_1 \
--max-epoch 3 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-4 --lr-scheduler inverse_sqrt --warmup-updates 4000 \
--dropout 0.1 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 98_1.log
fairseq-interactive --path save98_1/checkpoint3.pt data98 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 98_1.out
spacy_tokenize('98_1.out', '98_1.out.spacy')
fairseq-score --sys 98_1.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='98_1.out.spacy')
BLEU4 = 8.80, 42.9/14.7/6.3/3.2 (BP=0.830, ratio=0.843, syslen=23286, reflen=27625)
Let's learn with KFTT.
fairseq-preprocess -s ja -t en \
--trainpref train.sub \
--validpref dev.sub \
--tgtdict data98/dict.en.txt \
--srcdict data98/dict.ja.txt \
--destdir data98_2 \
--workers 20
fairseq-train data98_2 \
--fp16 \
--restore-file save98_1/checkpoint3.pt \
--save-dir save98_2 \
--max-epoch 10 \
--arch transformer --share-decoder-input-output-embed \
--optimizer adam --clip-norm 1.0 \
--lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \
--dropout 0.1 --weight-decay 0.0001 \
--criterion label_smoothed_cross_entropy --label-smoothing 0.1 \
--max-tokens 8000 > 98_2.log
fairseq-interactive --path save98_2/checkpoint10.pt data98_2 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 98_2.out
spacy_tokenize('98_2.out', '98_2.out.spacy')
fairseq-score --sys 98_2.out.spacy --ref test.spacy.en
Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='98_2.out.spacy')
BLEU4 = 22.85, 54.9/28.0/16.7/10.7 (BP=0.998, ratio=0.998, syslen=27572, reflen=27625)
Your score has improved a little.
The 90th to 98th questions are skipping the search for hyperparameters as a whole, but if you find a better hyperparameter in Chapter 10 of 100 knocks, please make a Qiita article.
Next is "99. Construction of translation server"
Build a demo system where the user inputs the sentence he wants to translate and the translation result is displayed on the web browser.
No. 99, I will do it soon.
Recommended Posts