[PYTHON] 100 Language Processing Knock 2020 Chapter 5: Dependency Analysis
The other day, 100 Language Processing Knock 2020 was released. I myself have only been in natural language processing for a year, and I don't know the details, but I will solve all the problems and publish them in order to improve my technical skills.
All shall be executed on jupyter notebook, and the restrictions of the problem statement may be broken conveniently. The source code is also on github. Yes.
Chapter 4 is here.
The environment is Python 3.8.2 and Ubuntu 18.04.
Chapter 5: Dependency Analysis
Use CaboCha to parse the text (neko.txt) of Natsume Soseki's novel "I am a cat" and save the result in a file called neko.txt.cabocha. Use this file to implement a program that addresses the following questions.
Please download the required dataset from here.
The downloaded file shall be placed under data.
Dependency analysis using CaboCha
code
cat data/neko.txt | cabocha -f3 > data/neko.txt.cabocha
You can output in various formats by specifying the f option, but this time I chose XML format.
40. Reading the dependency analysis result (morpheme)
Implement the class Morph that represents morphemes. This class has surface, uninflected, part of speech (pos), and part of speech subclassification 1 (pos1) as member variables. In addition, read the analysis result of CaboCha (neko.txt.cabocha), express each sentence as a list of Morph objects, and display the morpheme string of the third sentence.
An implementation of the class Morph that represents morphemes.
code
class Morph:
def __init__(self, token):
self.surface = token.text
feature = token.attrib['feature'].split(',')
self.base = feature[6]
self.pos = feature[0]
self.pos1 = feature[1]
def __repr__(self):
return self.surface
Read the XML.
code
import xml.etree.ElementTree as ET
with open("neko.txt.cabocha") as f:
root = ET.fromstring("<sentences>" + f.read() + "</sentences>")
Create a list of Morph for each sentence and store it in the neko list.
code
neko = []
for sent in root:
sent = [chunk for chunk in sent]
sent = [Morph(token) for chunk in sent for token in chunk]
neko.append(sent)
The third morpheme sequence from the front of neko is shown.
code
for x in neko[2]:
print(x)
When you print an object of the Morph class, __repr__ is called and the surface shape is displayed.
output
I
Is
Cat
so
is there
。
41. Reading the dependency analysis result (phrase / dependency)
In addition to> 40, implement the clause class Chunk. This class has a list of morphemes (Morph objects) (morphs), a list of related clause index numbers (dst), and a list of related original clause index numbers (srcs) as member variables. In addition, read the analysis result of CaboCha of the input text, express one sentence as a list of Chunk objects, and display the character string and the contact of the phrase of the eighth sentence. For the rest of the problems in Chapter 5, use the program created here.
Create a chunk class and a sentence class. Chunk contacts are not created when you create a chunk object, but are created when you create a statement object.
Chunks and sentences inherit the list type and can be treated as a list of morphemes and chunks, respectively.
code
import re
class Chunk(list):
def __init__(self, chunk):
self.morphs = [Morph(morph) for morph in chunk]
super().__init__(self.morphs)
self.dst = int(chunk.attrib['link'])
self.srcs = []
def __repr__(self): #Used in Q42
return re.sub(r'[、。]', '', ''.join(map(str, self)))
Chunks are converted to a string that connects each morpheme with __repr__.
At this time, the punctuation marks are removed according to the constraint of problem 42.
code
class Sentence(list):
def __init__(self, sent):
self.chunks = [Chunk(chunk) for chunk in sent]
super().__init__(self.chunks)
for i, chunk in enumerate(self.chunks):
if chunk.dst != -1:
self.chunks[chunk.dst].srcs.append(i)
code
neko = [Sentence(sent) for sent in root]
Now you can store the analysis results for each sentence in the list.
code
from tabulate import tabulate
Use tabulate.tabulate to display it for easy viewing.
code
table = [
[''.join([morph.surface for morph in chunk]), chunk.dst]
for chunk in neko[7]
]
tabulate(table, tablefmt = 'html', headers = ['number', 'Phrase', 'Contact'], showindex = 'always')
output
Number clause
------ ---------- --------
0 I am 5
1 here 2
2 for the first time 3
3 human 4
4 things 5
5 saw.-1
42. Display of the phrase of the person concerned and the person concerned
Extract all the text of the original clause and the relationed clause in tab-delimited format. However, do not output symbols such as punctuation marks.
code
sent = neko[7]
for chunk in sent:
if chunk.dst != -1:
src = chunk
dst = sent[chunk.dst]
print(f'{src}\t{dst}')
All you have to do is display the chunks and the chunks to which they are associated as strings for each chunk.
output
I saw
For the first time here
For the first time called human
Human beings
I saw something
43. Extract the clauses containing nouns related to the clauses containing verbs
When clauses containing nouns relate to clauses containing verbs, extract them in tab-delimited format. However, do not output symbols such as punctuation marks.
code
def has_noun(chunk):
return any(morph.pos == 'noun' for morph in chunk)
def has_verb(chunk):
return any(morph.pos == 'verb' for morph in chunk)
code
sent = neko[7]
for chunk in sent:
if chunk.dst != -1 and has_noun(chunk) and has_verb(sent[chunk.dst]):
src = chunk
dst = sent[chunk.dst]
print(f'{src}\t{dst}')
Create a function to determine whether a chunk contains nouns and verbs, and display only those that match the conditions.
output
I saw
For the first time here
I saw something
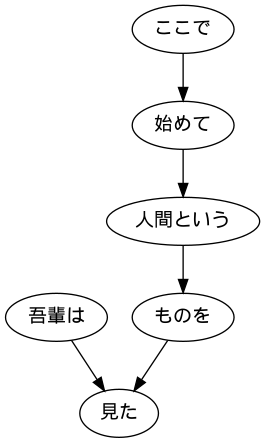
44. Visualization of dependent trees
Visualize the dependency tree of a given sentence as a directed graph. For visualization, convert the dependency tree to DOT language and use Graphviz. Also, to visualize directed graphs directly from Python, use pydot.
code
from pydot import Dot, Edge, Node
from PIL import Image
code
sent = neko[7]
graph = Dot(graph_type = 'digraph')
#Make a knot
for i, chunk in enumerate(sent):
node = Node(i, label = chunk)
graph.add_node(node)
#Make a branch
for i, chunk in enumerate(sent):
if chunk.dst != -1:
edge = Edge(i, chunk.dst)
graph.add_edge(edge)
graph.write_png('sent.png')
Image.open('sent.png')
45. Extraction of verb case patterns
I would like to consider the sentence used this time as a corpus and investigate the cases that Japanese predicates can take. Think of the verb as a predicate and the particle of the phrase related to the verb as a case, and output the predicate and case in tab-delimited format. However, make sure that the output meets the following specifications.
・ In a phrase containing a verb, the uninflected word of the leftmost verb is used as a predicate. ・ Cases are particles related to predicates ・ If there are multiple particles (phrases) related to the predicate, arrange all the particles in lexicographic order separated by spaces. Consider the example sentence (8th sentence of neko.txt.cabocha) that "I saw a human being for the first time here". This sentence contained two verbs, "begin" and "see", and the phrase "begin" was analyzed as "here", and the phrase as> "see" was analyzed as "I am" and "thing". In that case, the output should look like this:
Start See Save the output of this program to a file and check the following items using UNIX commands.
・ Combination of predicates and case patterns that frequently appear in the corpus ・ Case patterns of the verbs "do", "see", and "give" (arrange in order of frequency of appearance in the corpus)
code
def get_first_verb(chunk):
for morph in chunk:
if morph.pos == 'verb':
return morph.base
def get_last_case(chunk):
for morph in chunk[::-1]:
if morph.pos == 'Particle':
return morph.surface
def extract_cases(srcs):
xs = [get_last_case(src) for src in srcs]
xs = [x for x in xs if x]
xs.sort()
return xs
Determine if the chunk starts with a verb and extract the particle of the original chunk.
code
with open('result/case_pattern.txt', 'w') as f:
for sent in neko:
for chunk in sent:
if verb := get_first_verb(chunk): #Start with a verb
srcs = [sent[src] for src in chunk.srcs]
if cases := extract_cases(srcs): #There is a particle
line = '{}\t{}'.format(verb, ' '.join(cases))
print(line, file=f)
code
cat result/case_pattern.txt | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
output
2645
1559 Tsukuka
840
553
380 grab
364 I think
334 to see
257
253
Until there are 205
code
cat result/case_pattern.txt | grep 'To do' | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
output
1239
806
313
140
Until 102
84 What is
59
32
32
24 as
code
cat result/case_pattern.txt | grep 'to see' | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
output
334 to see
121 See
40 to see
25
23 from seeing
12 Seeing
8 to see
7 Because I see
3 Just looking
3 Looking at it
code
cat result/case_pattern.txt | grep 'give' | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
output
7 to give
4 to give
3 What to give
Give 1 but give
1 As to give
1 to give
1 to give
46. Extraction of verb case frame information
Modify the program> 45 and output the predicate and case pattern followed by the term (the phrase itself related to the predicate) in tab-delimited format. In addition to the 45 specifications, meet the following specifications.
・ The term is a word string of the phrase related to the predicate (it is not necessary to remove the particle at the end) ・ If there are multiple phrases related to the predicate, arrange them in the same standard and order as the particles, separated by spaces. Consider the example sentence (8th sentence of neko.txt.cabocha) that "I saw a human being for the first time here". This sentence contains two verbs, "begin" and "see", when the phrase "begin" is analyzed as "here" and the phrase as "see" is analyzed as "I am" and "thing". Should produce the following output.
Start here See what I see
code
def extract_args(srcs):
xs = [src for src in srcs if get_last_case(src)]
xs.sort(key = lambda src : get_last_case(src))
xs = [str(src) for src in xs]
return xs
Modify the code in question 45 to display the original chunk as well.
code
for sent in neko[:10]:
for chunk in sent:
if verb := get_first_verb(chunk): #Starts with a verb
srcs = [sent[src] for src in chunk.srcs]
if cases := extract_cases(srcs): #There is a particle
args = extract_args(srcs)
line = '{}\t{}\t{}'.format(verb, ' '.join(cases), ' '.join(args))
print(line)
output
Where to be born
I have no idea if it was born
Where to cry
The only thing I was crying
Get started here
See what I see
Listen later
Catch us
Boil and catch
Eat and boil
47. Functional verb syntax mining
I would like to pay attention only when the verb wo case contains a s-irregular noun. Modify 46 programs to meet the following specifications.
・ Only when the phrase consisting of "Sahen connecting noun + (particle)" is related to a verb ・ The predicate is "Sahen connection noun + is the basic form of + verb", and if there are multiple verbs in the phrase, the leftmost verb is used. ・ If there are multiple particles (phrases) related to the predicate, arrange all the particles in lexicographic order separated by spaces. ・ If there are multiple clauses related to the predicate, arrange all the terms separated by spaces (align with the order of particles). ・ For example, the following output should be obtained from the sentence, "The master will reply to the letter, even if it comes to another place."
When replying, the owner said to the letter Save the output of this program to a file and check the following items using UNIX commands.
・ Predicates that frequently appear in the corpus (sa-hen connection noun + + verb) ・ Predicates and particles that frequently appear in the corpus
code
def is_sahen(chunk):
return len(chunk) == 2 and chunk[0].pos1 == 'Change connection' and chunk[1].surface == 'To'
def split_sahen(srcs):
for i in range(len(srcs)):
if is_sahen(srcs[i]):
return str(srcs[i]), srcs[:i] + srcs[i+1:]
return None, srcs
With split_sahen, the chunk in the form of" sa-variable connection verb + ~ "is extracted from the original chunk of the chunk containing the verb.
code
with open('result/sahen_pattern.txt', 'w') as f:
for sent in neko:
for chunk in sent:
if verb := get_first_verb(chunk):
srcs = [sent[src] for src in chunk.srcs]
sahen, rest = split_sahen(srcs)
if sahen and (cases := extract_cases(rest)):
args = extract_args(rest)
line = '{}\t{}\t{}'.format(sahen + verb, ' '.join(cases), ' '.join(args))
print(line, file=f)
code
cat result/sahen_pattern.txt | cut -f 1 | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
output
25 reply
19 Say hello
11 talk
9 Ask a question
7 imitate
7 quarrel
5 Ask a question
5 Consult
5 Take a nap
4 give a speech
code
cat result/sahen_pattern.txt | cut -f 1,2 | sort | uniq -c | sort -nr 2> /dev/null | head -n 10
output
10 When you reply
7 What is a reply?
7 Say hello
5 To ask a question
5 In a quarrel
4 Ask a question
4 to talk
4 I'll say hello
3 Because I will reply
3 Listen to the discourse
48. Extracting paths from nouns to roots
For a clause containing all nouns in the sentence, extract the path from that clause to the root of the syntax tree. However, the path on the syntax tree shall satisfy the following specifications.
・ Each clause is represented by a (surface) morpheme sequence ・ From the start clause to the end clause of the path, connect the expressions of each clause with "->" From the sentence "I saw a human being for the first time here" (8th sentence of neko.txt.cabocha), the following output should be obtained.
I saw-> Here-> for the first time-> human-> I saw something-> I saw a human-> thing-> I saw something->
code
def trace(n, sent):
path = []
while n != -1:
path.append(n)
n = sent[n].dst
return path
code
sent = neko[7]
heads = [n for n in range(len(sent)) if has_noun(sent[n])]
for head in heads:
path = trace(head, sent)
path = ' -> '.join([str(sent[n]) for n in path])
print(path)
Find all the chunk numbers that have nouns and get the path as a list of chunk numbers while tracing each contact. Finally, the chunks should be displayed in the order of the paths.
output
I am->saw
here->Start with->Human->Things->saw
Human->Things->saw
Things->saw
49. Extraction of dependency paths between nouns
Extract the shortest dependency path that connects all noun phrase pairs in a sentence. However, when the phrase number of the noun phrase pair is i and j (i <j), the dependency path shall satisfy the following specifications.
・ Similar to Problem 48, the path expresses the expression (surface morpheme string) of each phrase from the start clause to the end clause by connecting them with "->". ・ Replace the noun phrases contained in the clauses i and j with X and Y, respectively. In addition, the shape of the dependency path can be considered in the following two ways.
・ When clause j exists on the route from clause i to the root of the syntax tree: Display the path from clause i to clause j ・ Other than the above, when clause i and clause j intersect at a common clause k on the path from clause j to the root of the syntax tree: the path immediately before clause i to clause k and the path immediately before clause j to clause k, Display the contents of clause k by concatenating them with "|" For example, from the sentence "I saw a human being for the first time here" (8th sentence of neko.txt.cabocha), the following output should be obtained.
X is|In Y->Start with->Human->Things|saw X is|Called Y->Things|saw X is|Y|saw With X-> For the first time-> Y With X-> For the first time-> Human-> Y X-> Y
code
def extract_path(x, y, sent):
xs = []
ys = []
while x != y:
if x < y:
xs.append(x)
x = sent[x].dst
else:
ys.append(y)
y = sent[y].dst
return xs, ys, x
def remove_initial_nouns(chunk):
for i, morph in enumerate(chunk):
if morph.pos != 'noun':
break
return ''.join([str(morph) for morph in chunk[i:]]).strip()
def path_to_str(xs, ys, last, sent):
xs = [sent[x] for x in xs]
ys = [sent[y] for y in ys]
last = sent[last]
if xs and ys:
xs = ['X' + remove_initial_nouns(xs[0])] + [str(x) for x in xs[1:]]
ys = ['Y' + remove_initial_nouns(ys[0])] + [str(y) for y in ys[1:]]
last = str(last)
return ' -> '.join(xs) + ' | ' + ' -> '.join(ys) + ' | ' + last
else:
xs = xs + ys
xs = ['X' + remove_initial_nouns(xs[0])] + [str(x) for x in xs[1:]]
last = 'Y' + remove_initial_nouns(last)
return ' -> '.join(xs + [last])
code
sent = neko[7]
heads = [n for n in range(len(sent)) if has_noun(sent[n])]
print('The beginning of the path:', heads)
pairs = [
(heads[n], second)
for n in range(len(heads))
for second in heads[n + 1:]
]
print('First pair of paths: ', pairs)
print('Dependency pass:')
for x, y in pairs:
x_path, y_path, last = extract_path(x, y, sent)
path = path_to_str(x_path, y_path, last, sent)
print(path)
First we get a list of chunk numbers with nouns.
Then you get all the pairs of that chunk.
Then, for each pair, the path is calculated until the same chunk is reached, and it is specified by path_to_str based on each pathx_path, y_path and the last common chunk last. Converted to format.
output
The beginning of the path: [0, 1, 3, 4]
First pair of paths: [(0, 1), (0, 3), (0, 4), (1, 3), (1, 4), (3, 4)]
Dependency pass:
X is|In Y->Start with->Human->Things|saw
X is|Called Y->Things|saw
X is|Y|saw
In X->Start with->Called Y
In X->Start with->Human->Y
Called X->Y
Next is Chapter 6
Language processing 100 knocks 2020 Chapter 6: Machine learning
Recommended Posts