[PYTHON] 100 Language Processing Knock 2015 Chapter 5 Dependency Analysis (40-49)
I tried to solve "Chapter 5 Dependency Analysis (40-49)" of 100 knocks. This is a continuation of Chapter 4 Morphological Analysis (30-39).
environment
- OS X El Capitan Version 10.11.4
- Python 3.5.1
Referenced page
I was quite addicted to the introduction of CaboCha, pydot, and Graphviz and "49. Extraction of dependency paths between nouns", but I managed to solve it by referring to the following site.
-100 knocks of natural language processing Chapter 5 Dependency analysis (first half) -100 knocks of natural language processing Chapter 5 Dependency analysis (second half) -Language processing 100 knock 2015 version (46-49) -CaboCha official website -Dependency analysis starting with CaboCha -Summary of how to draw a graph in Graphviz and dot language -Draw a tree structure in Python3 using graphviz
- [AttributeError: module 'pydot' has no attribute 'graph_from_dot_data' in spyder] (http://stackoverflow.com/questions/35285142/attributeerror-module-pydot-has-no-attribute-graph-from-dot-data-in-spyder)
Preparation
Library to use
import CaboCha
import pydotplus
import subprocess
Saving dependent parsed text
Use CaboCha to parse the text (neko.txt) of Natsume Soseki's novel "I am a cat" and save the result in a file called neko.txt.cabocha. Use this file to implement a program that addresses the following questions.
def make_analyzed_file(input_file_name: str, output_file_name: str) -> None:
"""
Parse a plain Japanese sentence file, parse it, and save it in a file.
(Remove whitespace.)
:param input_file_name Plain Japanese sentence file name
:param output_file_name Dependent parsed text file name
"""
c = CaboCha.Parser()
with open(input_file_name, encoding='utf-8') as input_file:
with open(output_file_name, mode='w', encoding='utf-8') as output_file:
for line in input_file:
tree = c.parse(line.lstrip())
output_file.write(tree.toString(CaboCha.FORMAT_LATTICE))
make_analyzed_file('neko.txt', 'neko.txt.cabocha')
40. Reading the dependency analysis result (morpheme)
Implement the class Morph that represents morphemes. This class has surface form (surface), uninflected word (base), part of speech (pos), and part of speech subclassification 1 (pos1) as member variables. Furthermore, read the analysis result of CaboCha (neko.txt.cabocha), express each sentence as a list of Morph objects, and display the morpheme string of the third sentence.
class Morph:
"""
A class that represents one morpheme
"""
def __init__(self, surface, base, pos, pos1):
"""
It has surface form (surface), uninflected word (base), part of speech (pos), and part of speech subclassification 1 (pos1) as member variables..
"""
self.surface = surface
self.base = base
self.pos = pos
self.pos1 = pos1
def is_end_of_sentence(self) -> bool: return self.pos1 == 'Kuten'
def __str__(self) -> str: return 'surface: {}, base: {}, pos: {}, pos1: {}'.format(self.surface, self.base, self.pos, self.pos1)
def make_morph_list(analyzed_file_name: str) -> list:
"""
Read the dependent and parsed sentence file and express each sentence as a list of Morph objects
:param analyzed_file_name Dependent parsed text file name
:return list A list of one sentence represented as a list of Morph objects
"""
sentences = []
sentence = []
with open(analyzed_file_name, encoding='utf-8') as input_file:
for line in input_file:
line_list = line.split()
if (line_list[0] == '*') | (line_list[0] == 'EOS'):
pass
else:
line_list = line_list[0].split(',') + line_list[1].split(',')
#Line at this point_list looks like this
# ['start', 'noun', 'Adverbs possible', '*', '*', '*', '*', 'start', 'Hajime', 'Hajime']
_morph = Morph(surface=line_list[0], base=line_list[7], pos=line_list[1], pos1=line_list[2])
sentence.append(_morph)
if _morph.is_end_of_sentence():
sentences.append(sentence)
sentence = []
return sentences
morphed_sentences = make_morph_list('neko.txt.cabocha')
#Display the morpheme string of the third sentence
for morph in morphed_sentences[2]:
print(str(morph))
41. Reading the dependency analysis result (phrase / dependency)
In addition to> 40, implement the clause class Chunk.
This class has a list of morphemes (Morph objects) (morphs), a list of related clause index numbers (dst), and a list of related original clause index numbers (srcs) as member variables. Furthermore, read the analysis result of CaboCha of the input text, express one sentence as a list of Chunk objects, and display the character string and the contact of the phrase of the eighth sentence. For the rest of the problems in Chapter 5, use the program created here.
There are many methods in the Chunk class, but all you need here is __init__ and __str__. Other methods were added each time the subsequent questions were solved.
class Chunk:
def __init__(self, morphs: list, dst: str, srcs: str) -> None:
"""
It has a list of morphemes (Morph objects) (morphs), a list of related clause index numbers (dst), and a list of related original clause index numbers (srcs) as member variables.
"""
self.morphs = morphs
self.dst = int(dst.strip("D"))
self.srcs = int(srcs)
#Below are the methods we will use later.
def join_morphs(self) -> str:
return ''.join([_morph.surface for _morph in self.morphs if _morph.pos != 'symbol'])
def has_noun(self) -> bool:
return any([_morph.pos == 'noun' for _morph in self.morphs])
def has_verb(self) -> bool:
return any([_morph.pos == 'verb' for _morph in self.morphs])
def has_particle(self) -> bool:
return any([_morph.pos == 'Particle' for _morph in self.morphs])
def has_sahen_connection_noun_plus_wo(self) -> bool:
"""
"Sahen connection noun+Returns whether or not it contains "(particle)".
"""
for idx, _morph in enumerate(self.morphs):
if _morph.pos == 'noun' and _morph.pos1 == 'Change connection' and len(self.morphs[idx:]) > 1 and \
self.morphs[idx + 1].pos == 'Particle' and self.morphs[idx + 1].base == 'To':
return True
return False
def first_verb(self) -> Morph:
return [_morph for _morph in self.morphs if _morph.pos == 'verb'][0]
def last_particle(self) -> list:
return [_morph for _morph in self.morphs if _morph.pos == 'Particle'][-1]
def pair(self, sentence: list) -> str:
return self.join_morphs() + '\t' + sentence[self.dst].join_morphs()
def replace_noun(self, alt: str) -> None:
"""
Replace the representation of a noun.
"""
for _morph in self.morphs:
if _morph.pos == 'noun':
_morph.surface = alt
def __str__(self) -> str:
return 'srcs: {}, dst: {}, morphs: ({})'.format(self.srcs, self.dst, ' / '.join([str(_morph) for _morph in self.morphs]))
def make_chunk_list(analyzed_file_name: str) -> list:
"""
Read the dependent and parsed sentence file and express each sentence as a list of Chunk objects
:param analyzed_file_name Dependent parsed text file name
:return list A list of one sentence expressed as a list of Chunk objects.
"""
sentences = []
sentence = []
_chunk = None
with open(analyzed_file_name, encoding='utf-8') as input_file:
for line in input_file:
line_list = line.split()
if line_list[0] == '*':
if _chunk is not None:
sentence.append(_chunk)
_chunk = Chunk(morphs=[], dst=line_list[2], srcs=line_list[1])
elif line_list[0] == 'EOS': # End of sentence
if _chunk is not None:
sentence.append(_chunk)
if len(sentence) > 0:
sentences.append(sentence)
_chunk = None
sentence = []
else:
line_list = line_list[0].split(',') + line_list[1].split(',')
#Line at this point_list looks like this
# ['start', 'noun', 'Adverbs possible', '*', '*', '*', '*', 'start', 'Hajime', 'Hajime']
_morph = Morph(surface=line_list[0], base=line_list[7], pos=line_list[1], pos1=line_list[2])
_chunk.morphs.append(_morph)
return sentences
chunked_sentences = make_chunk_list('neko.txt.cabocha')
#Display the morpheme string of the third sentence
for chunk in chunked_sentences[2]:
print(str(chunk))
42. Display of the phrase of the person concerned and the person concerned
Extract all the text of the original clause and the relationed clause in tab-delimited format. However, do not output symbols such as punctuation marks.
I will summarize each sentence for ease of use in 44.
def is_valid_chunk(_chunk, sentence):
return _chunk.join_morphs() != '' and _chunk.dst > -1 and sentence[_chunk.dst].join_morphs() != ''
paired_sentences = [[chunk.pair(sentence) for chunk in sentence if is_valid_chunk(chunk, sentence)] for sentence in chunked_sentences if len(sentence) > 1]
print(paired_sentences[0:100])
43. Extract the clauses containing nouns related to the clauses containing verbs
When clauses containing nouns relate to clauses containing verbs, extract them in tab-delimited format. However, do not output symbols such as punctuation marks.
It's easy because various convenient methods are implemented in the Chunk class.
for sentence in chunked_sentences:
for chunk in sentence:
if chunk.has_noun() and chunk.dst > -1 and sentence[chunk.dst].has_verb():
print(chunk.pair(sentence))
44. Visualization of dependent trees
Visualize the dependency tree of a given sentence as a directed graph. For visualization, convert the dependency tree to DOT language and use Graphviz. Also, to visualize directed graphs directly from Python, use pydot.
def sentence_to_dot(idx: int, sentence: list) -> str:
head = "digraph sentence{} ".format(idx)
body_head = "{ graph [rankdir = LR]; "
body_list = ['"{}"->"{}"; '.format(*chunk_pair.split()) for chunk_pair in sentence]
return head + body_head + ''.join(body_list) + '}'
def sentences_to_dots(sentences: list) -> list:
_dots = []
for idx, sentence in enumerate(sentences):
_dots.append(sentence_to_dot(idx, sentence))
return _dots
def save_graph(dot: str, file_name: str) -> None:
g = pydotplus.graph_from_dot_data(dot)
g.write_jpeg(file_name, prog='dot')
dots = sentences_to_dots(paired_sentences)
for idx in range(101, 104):
save_graph(dots[idx], 'graph{}.jpg'.format(idx))
[Sample] Dependent tree for the 101st sentence

[Sample] Dependent tree for the 102nd sentence

[Sample] Dependent tree for the 103rd sentence
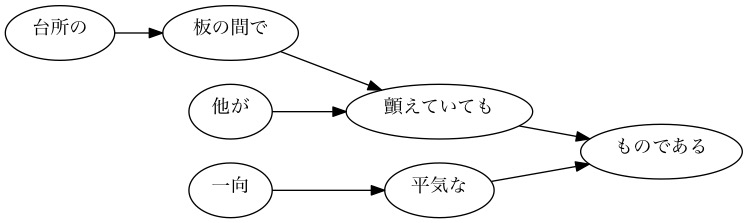
- By the way, it seems that "to sway" is read as "to shake".
45. Extraction of verb case patterns
I would like to consider the sentence used this time as a corpus and investigate the cases that Japanese predicates can take. Consider a verb as a predicate and a particle of a phrase related to a verb as a case, and output the predicate and case in a tab-delimited format. However, make sure that the output meets the following specifications.
--In a clause containing a verb, the uninflected word of the leftmost verb is used as a predicate. --The case is a particle related to a predicate --If there are multiple particles (phrases) related to the predicate, arrange all the particles in lexicographic order separated by spaces.
Consider the example sentence (8th sentence of neko.txt.cabocha) that "I saw a human being for the first time here". This sentence contains two verbs, "begin" and "see", and the phrase related to "begin" was analyzed as "here", and the phrase related to "see" was analyzed as "I am" and "thing". In that case, the output should look like this:
At the beginning To see
Save the output of this program to a file and check the following items using UNIX commands.
--Combination of predicates and case patterns that occur frequently in the corpus --The case pattern of the verbs "do", "see", and "give" (arrange in order of frequency of appearance in the corpus)
def case_patterns(_chunked_sentences: list) -> list:
"""
Verb case pattern(Combination of verbs and particles)Returns a list of.("Case" is in English"Case"It seems that.)
:param _chunked_sentences A list of chunked morphemes listed by sentence
:return case pattern(For example['give', ['To', 'To']])List of
"""
_case_pattern = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
if len(particles) > 0:
_case_pattern.append([_chunk.first_verb().base, sorted(particles)])
return _case_pattern
def save_case_patterns(_case_patterns: list, file_name: str) -> None:
"""
Verb case pattern(Combination of verbs and particles)Save the list to a file.
:param _case_patterns case pattern(For example['give', ['To', 'To']])List of
:param file_name Save destination file name
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for _case in _case_patterns:
output_file.write('{}\t{}\n'.format(_case[0], ' '.join(_case[1])))
save_case_patterns(case_patterns(chunked_sentences), 'case_patterns.txt')
def print_case_pattern_ranking(_grep_str: str) -> None:
"""
Corpus(case_pattern.txt)Use UNIX commands to display the top 20 items in descending order of frequency of occurrence..
`cat case_patterns.txt | grep '^To do\t' | sort | uniq -c | sort -r | head -20`Is printing by executing a Unix command like.
The grep part is an argument`_grep_str`Is added according to.
:param _grep_str Search condition verb
"""
_grep_str = '' if _grep_str == '' else '| grep \'^{}\t\''.format(_grep_str)
print(subprocess.run('cat case_patterns.txt {} | sort | uniq -c | sort -r | head -10'.format(_grep_str), shell=True))
#Combinations of predicates and case patterns that frequently appear in the corpus (top 10)
#Case patterns of the verbs "do", "see", and "give" (top 10 in order of appearance frequency in the corpus)
for grep_str in ['', 'To do', 'to see', 'give']:
print_case_pattern_ranking(grep_str)
46. Extraction of verb case frame information
Modify the program> 45 and output the predicate and case pattern followed by the term (the clause itself related to the predicate) in tab-delimited format. In addition to the> 45 specification, meet the following specifications.
--The term should be a word string of the clause related to the predicate (there is no need to remove the trailing particle) --If there are multiple clauses related to the predicate, arrange them in the same standard and order as the particles, separated by spaces.
Consider the example sentence (8th sentence of neko.txt.cabocha) that "I saw a human being for the first time here". This sentence contains two verbs, "begin" and "see", and the phrase "begin" was analyzed as "here" and the phrase "see" was analyzed as "I am" and "thing". In that case, the output should look like this:
Get started here See what I see
def sorted_double_list(key_list: list, value_list: list) -> tuple:
"""
Takes two lists as arguments, dicts one list as a key and the other list as a value, sorts by key, then decomposes into two lists and returns as a tuple..
:param key_list A key list for sorting
:param value_List sorted according to list key
:return key_Tuples of two lists sorted by list
"""
double_list = list(zip(key_list, value_list))
double_list = dict(double_list)
double_list = sorted(double_list.items())
return [pair[0] for pair in double_list], [pair[1] for pair in double_list]
def case_frame_patterns(_chunked_sentences: list) -> list:
"""
Verb case frame pattern(Combination of verbs and particles)Returns a list of.
:param _chunked_sentences A list of chunked morphemes listed by sentence
:return case pattern(For example['To do', ['hand', 'Is'], ['泣いhand', 'いた事だけIs']])List of
"""
_case_frame_patterns = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
clauses = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and c.has_particle()]
if len(particles) > 0:
_case_frame_patterns.append([_chunk.first_verb().base, *sorted_double_list(particles, clauses)])
return _case_frame_patterns
def save_case_frame_patterns(_case_frame_patterns: list, file_name: str) -> None:
"""
Verb case pattern(Combination of verbs and particles)Save the list to a file.
:param _case_frame_patterns case frame(For example['To do', ['hand', 'Is'], ['泣いhand', 'いた事だけIs']])List of
:param file_name Save destination file name
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for case in _case_frame_patterns:
output_file.write('{}\t{}\t{}\n'.format(case[0], ' '.join(case[1]), ' '.join(case[2])))
save_case_frame_patterns(case_frame_patterns(chunked_sentences), 'case_frame_patterns.txt')
47. Functional verb syntax mining
I would like to pay attention only when the verb wo case contains a s-irregular noun. Modify 46 programs to meet the following specifications.
--Only when the phrase consisting of "Sahen connection noun + (particle)" is related to the verb --The predicate is "Sahen connection noun + is the basic form of + verb", and if there are multiple verbs in the phrase, the leftmost verb is used --If there are multiple particles (phrases) related to the predicate, arrange all the particles in lexicographic order separated by spaces. --If there are multiple clauses related to the predicate, arrange all the terms separated by spaces (align with the order of particles).
For example, the following output should be obtained from the sentence, "The master will reply to the letter, even if it comes to another place."
When I reply to the letter, my husband
Save the output of this program to a file and check the following items using UNIX commands.
--Predicates that frequently appear in the corpus (sa-variant noun + + verb) --Predicates and particles that frequently appear in the corpus
def sahen_case_frame_patterns(_chunked_sentences: list) -> list:
"""
Verb case frame pattern(Combination of verbs and particles)Returns a list of.
:param _chunked_sentences A list of chunked morphemes listed by sentence
:return case pattern(For example['To do', ['hand', 'Is'], ['泣いhand', 'いた事だけIs']])List of
"""
_sahen_case_frame_patterns = []
for sentence in _chunked_sentences:
for _chunk in sentence:
if not _chunk.has_verb():
continue
sahen_connection_noun = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and c.has_sahen_connection_noun_plus_wo()]
clauses = [c.join_morphs() for c in sentence if c.dst == _chunk.srcs and not c.has_sahen_connection_noun_plus_wo() and c.has_particle()]
particles = [c.last_particle().base for c in sentence if c.dst == _chunk.srcs and not c.has_sahen_connection_noun_plus_wo() and c.has_particle()]
if len(sahen_connection_noun) > 0 and len(particles) > 0:
_sahen_case_frame_patterns.append([sahen_connection_noun[0] + _chunk.first_verb().base, *sorted_double_list(particles, clauses)])
return _sahen_case_frame_patterns
def save_sahen_case_frame_patterns(_sahen_case_frame_patterns: list, file_name: str) -> None:
"""
Verb case pattern(Combination of verbs and particles)Save the list to a file.
:param _sahen_case_frame_patterns case frame(For example['To do', ['hand', 'Is'], ['泣いhand', 'いた事だけIs']])List of
:param file_name Save destination file name
"""
with open(file_name, mode='w', encoding='utf-8') as output_file:
for case in _sahen_case_frame_patterns:
output_file.write('{}\t{}\t{}\n'.format(case[0], ' '.join(case[1]), ' '.join(case[2])))
save_sahen_case_frame_patterns(sahen_case_frame_patterns(chunked_sentences), 'sahen_case_frame_patterns.txt')
#Predicates that frequently appear in the corpus+To+動詞)ToUNIXコマンドTo用いて確認
print(subprocess.run('cat sahen_case_frame_patterns.txt | cut -f 1 | sort | uniq -c | sort -r | head -10', shell=True))
#Use UNIX commands to check predicates and particle patterns that frequently appear in the corpus
print(subprocess.run('cat sahen_case_frame_patterns.txt | cut -f 1,2 | sort | uniq -c | sort -r | head -10', shell=True))
48. Extracting paths from nouns to roots
For a clause containing all nouns in the sentence, extract the path from that clause to the root of the syntax tree. However, the path on the syntax tree shall satisfy the following specifications.
--Each clause is represented by a (superficial) morpheme sequence --Concatenate the expressions of each clause with "->" from the start clause to the end clause of the path.
From the sentence "I saw a human being for the first time here" (8th sentence of neko.txt.cabocha), the following output should be obtained.
I am->saw here->Start with->Human->Things->saw Human->Things->saw Things->saw
You can write clearly by calling the function recursively.
def path_to_root(_chunk: Chunk, _sentence: list) -> list:
"""
Clause given as an argument(`_chunk`)If is root, returns that clause.
Clause given as an argument(`_chunk`)If is not root, returns the clause and the path from the clause to which it belongs to root as a list..
:param _The clause that is the starting point for chunk root
:param _sentence The sentence to be analyzed
:return list _Path from chunk to root
"""
if _chunk.dst == -1:
return [_chunk]
else:
return [_chunk] + path_to_root(_sentence[_chunk.dst], _sentence)
def join_chunks_by_arrow(_chunks: list) -> str:
return ' -> '.join([c.join_morphs() for c in _chunks])
#Output only the first 10 sentences and check the operation
for sentence in chunked_sentences[0:10]:
for chunk in sentence:
if chunk.has_noun():
print(join_chunks_by_arrow(path_to_root(chunk, sentence)))
49. Extraction of dependency paths between nouns
Extract the shortest dependency path that connects all noun phrase pairs in a sentence. However, when the phrase number of the noun phrase pair is i and j (i <j), the dependency path shall satisfy the following specifications.
--Similar to Problem 48, the path is expressed by concatenating the expressions (surface morpheme strings) of each phrase from the start clause to the end clause with "->". --Replace noun phrases in clauses i and j with X and Y, respectively.
In addition, the shape of the dependency path can be considered in the following two ways.
--If clause j exists on the path from clause i to the root of the syntax tree: Show the path from clause i to clause j --Other than the above, when clause i and clause j intersect at a common clause k on the path from clause j to the root of the syntax tree: the path immediately before clause i to clause k and the path immediately before clause j to clause k, Display the contents of clause k by concatenating them with "|"
For example, from the sentence "I saw a human being for the first time here" (8th sentence of neko.txt.cabocha), the following output should be obtained.
X is|In Y->Start with->Human->Things|saw X is|Called Y->Things|saw X is|Y|saw In X->Start with-> Y In X->Start with->Human-> Y Called X-> Y
I didn't understand what I wanted to do by reading the problem statement, but 100 natural language processing knocks Chapter 5 Dependency analysis (second half) and [Language] Processing 100 knocks 2015 version (46-49)](http://kenichia.hatenablog.com/entry/2016/02/11/221513) I read and understood that this is the case.
If you start writing the code while breaking down the problem without knowing it, you will gradually understand it. Explain how you broken down the problem by writing a little more comments in the code below. I hope it will be helpful.
def noun_pairs(_sentence: list):
"""
Returns a list of all pairs that can be made from all the noun clauses of the sentence passed as an argument.
"""
from itertools import combinations
_noun_chunks = [_chunk for _chunk in _sentence if _chunk.has_noun()]
return list(combinations(_noun_chunks, 2))
def common_chunk(path_i: list, path_j: list) -> Chunk:
"""
If clause i and clause j intersect at a common clause k on the path to the root of the syntax tree, then clause k is returned..
"""
_chunk_k = None
path_i = list(reversed(path_i))
path_j = list(reversed(path_j))
for idx, (c_i, c_j) in enumerate(zip(path_i, path_j)):
if c_i.srcs != c_j.srcs:
_chunk_k = path_i[idx - 1]
break
return _chunk_k
for sentence in chunked_sentences:
#List of noun phrase pairs
n_pairs = noun_pairs(sentence)
if len(n_pairs) == 0:
continue
for n_pair in n_pairs:
chunk_i, chunk_j = n_pair
#Replace noun phrases in clauses i and j with X and Y, respectively.
chunk_i.replace_noun('X')
chunk_j.replace_noun('Y')
#Path from clauses i and j to root(Chunk type list)
path_chunk_i_to_root = path_to_root(chunk_i, sentence)
path_chunk_j_to_root = path_to_root(chunk_j, sentence)
if chunk_j in path_chunk_i_to_root:
#When clause j exists on the path from clause i to the root of the syntax tree
#Index on the path from clause i of clause j to the root of the syntax tree
idx_j = path_chunk_i_to_root.index(chunk_j)
#Show the path from clause i to clause j
print(join_chunks_by_arrow(path_chunk_i_to_root[0: idx_j + 1]))
else:
#Other than the above, when clause i and clause j intersect at a common clause k on the route from the root of the syntax tree
#Get clause k
chunk_k = common_chunk(path_chunk_i_to_root, path_chunk_j_to_root)
if chunk_k is None:
continue
#Index on the path from clause i of clause k to the root of the syntax tree
idx_k_i = path_chunk_i_to_root.index(chunk_k)
#Index on the path from clause j of clause k to the root of the syntax tree
idx_k_j = path_chunk_j_to_root.index(chunk_k)
#The path immediately before the passage i to the clause k, the path immediately before the passage j to the clause k, and the contents of the clause k"|"Display by connecting with
print(' | '.join([join_chunks_by_arrow(path_chunk_i_to_root[0: idx_k_i]),
join_chunks_by_arrow(path_chunk_j_to_root[0: idx_k_j]),
chunk_k.join_morphs()]))
Recommended Posts