Generieren Sie gefälschte Tabellendaten mit GAN
Überblick
Probieren Sie CTGAN, eine der GANs für Tabellendaten, mit dem Census Income-Dataset aus, um gefälschte Tabellendaten zu generieren. Trainieren Sie XGBoost mit den generierten Daten und überprüfen Sie, wie genau diese mit den Originaldaten verglichen werden.
CTGAN GAN ist als Technologie bekannt, die realistische gefälschte Bilder erzeugen kann. Die Forschung zu GAN für Nicht-Bilddaten schreitet jedoch ebenfalls voran. Im Folgenden sind die in GAN veröffentlichten Codes aufgeführt, die Tabellendaten entsprechen.
- MedGAN [arXiv:1703.06490][GitHub]
- TableGAN [arXiv:1806.03384][GitHub]
- TGAN [arXiv:1811.11264][GitHub]
- CTGAN [arXiv:1907.00503][GitHub]
Wie der Name schon sagt, ist MedGAN ein Modell, das unter Berücksichtigung medizinischer Daten entwickelt wurde und nur Kategoriedaten unterstützt. (Es gibt auch ein Modell für gleichnamige medizinische Bilder.) TableGAN und TGAN sind Modelle, die gleichzeitig unabhängig voneinander entwickelt wurden. Beide Unterstützungstabellen enthalten sowohl Kategoriedaten als auch numerische Daten. In japanischen Artikeln
TGAN wird in eingeführt. Dieses Mal werde ich CTGAN (Conditional Tabular GAN) ausprobieren, eine aktualisierte Version von TGAN.
CTGAN ist einfach mit pip zu installieren.
pip install ctgan
Datenaufbereitung
Verwenden Sie als Tabellendaten einen Datensatz mit dem Namen Census Income. Mit diesem Datensatz können Sie vorhersagen, ob Ihr Jahreseinkommen aufgrund persönlicher Informationen wie Geschlecht, Alter, akademischem Hintergrund und Rasse 50.000 USD übersteigt. Die Daten können über den obigen Link heruntergeladen werden. Da sie jedoch als Demo-Daten in CTGAN enthalten sind, können sie wie folgt gelesen werden.
import numpy as np
import pandas as pd
from ctgan import load_demo
df0 = load_demo()
print(df0.shape)
# (32561, 15)
Aus irgendeinem Grund enthalten die auf diese Weise gelesenen Daten am Anfang des Kategorieelements ein Leerzeichen mit halber Breite. Es spielt keine Rolle, ob der an CTGAN und XGBoost zu sendende Betrag einen Speicherplatz mit halber Breite enthält, dies ist jedoch ein Hindernis bei der Analyse von Daten. Entfernen Sie ihn daher vorerst.
for col in df0.select_dtypes(exclude=np.number).columns:
df0[col] = df0[col].str.replace(' ', '')
Die ersten Zeilen werden wie folgt angezeigt.
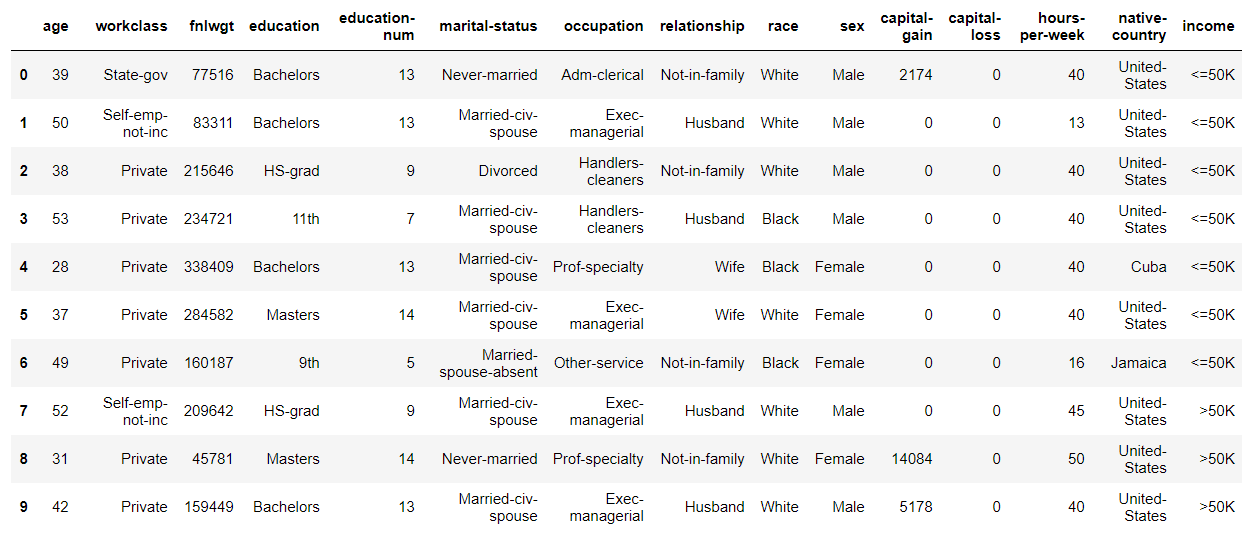 Sie können sehen, dass es aus einer kategorialen Variablenspalte und einer Ganzzahlspalte besteht.
Von diesen Spalten sind die folgenden ausgeschlossen.
'fnlwgt': Scheint wie eine ID-Nummer
'Bildungsnummer': Eins-zu-eins-Korrespondenz mit 'Bildung'
'Kapitalgewinn': Die meisten Zeilen enthalten 0
'Kapitalverlust': Wie oben
Sie können sehen, dass es aus einer kategorialen Variablenspalte und einer Ganzzahlspalte besteht.
Von diesen Spalten sind die folgenden ausgeschlossen.
'fnlwgt': Scheint wie eine ID-Nummer
'Bildungsnummer': Eins-zu-eins-Korrespondenz mit 'Bildung'
'Kapitalgewinn': Die meisten Zeilen enthalten 0
'Kapitalverlust': Wie oben
df0.drop(['fnlwgt', 'education-num', 'capital-gain', 'capital-loss'],
axis=1, inplace=True)
Übrigens enthält dieser Datensatz keine fehlenden Werte, und an der Stelle, an der ursprünglich ein Wert fehlte, befindet sich ein '?'. Lassen Sie dieses Mal das '?' Wie es ist und setzen Sie die Verarbeitung fort.
Teilen Sie dann den Datensatz in Training und Test auf. Die Trainingsdaten werden sowohl für das CTGAN-Training als auch für das XGBoost-Training verwendet.
df0_train, df_test = train_test_split(df0,
test_size=0.2,
random_state=0,
stratify=df0['income'])
print(len(df0_train)) # 26048
print(len(df_test)) # 6513
Bereiten Sie weitere kleine Trainingsdaten vor.
df1_train, _ = train_test_split(df0_train,
test_size=0.9,
random_state=0,
stratify=df0_train['income'])
print(len(df1_train)) # 2604
Datengenerierung
Lassen Sie uns zunächst CTGAN mit den größeren Trainingsdaten df0_train trainieren. Während des Trainings muss der Spaltenname der Kategorievariablen angegeben werden.
discrete_columns = [
'workclass',
'education',
'marital-status',
'occupation',
'relationship',
'race',
'sex',
'native-country',
'income'
]
Das Lernen kann wie folgt leicht durchgeführt werden. Die Eingabedaten entsprechen pandas.DataFrame und numpy.ndarray.
from ctgan import CTGANSynthesizer
ctgan0 = CTGANSynthesizer()
ctgan0.fit(df0_train, discrete_columns)
Das Lernen läuft 300 Epochen mit den Standardeinstellungen.
Generieren Sie Daten, wenn das Training abgeschlossen ist. Die generierten Daten haben dasselbe Format wie die Eingabedaten. In diesem Fall wird pandas.DataFrame zurückgegeben. Die Anzahl der Abtastwerte (Anzahl der Zeilen) der zu generierenden Daten kann frei eingestellt werden. Egal wie viel du machst, es ist kostenlos, also lass uns den Sprung wagen und 1 Million Zeilen machen.
n_samples = 1000000
df0_syn = ctgan0.sample(n_samples)
print(df0_syn.shape)
# (1000000, 11)
Die ersten Zeilen der generierten Daten sehen folgendermaßen aus:
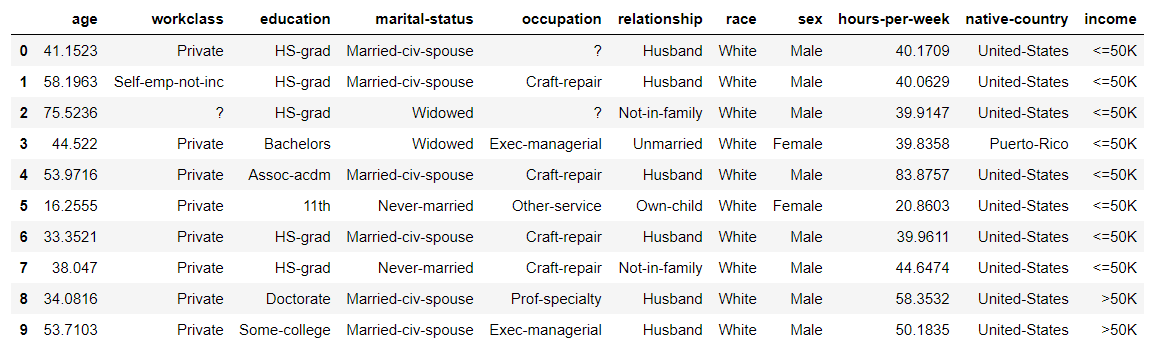 Numerische Daten werden ursprünglich als Gleitkomma betrachtet, auch wenn es sich um eine Ganzzahl handelt, und die Daten werden erstellt. Sie müssen sie daher nach der Generierung selbst in eine Ganzzahl konvertieren.
Numerische Daten werden ursprünglich als Gleitkomma betrachtet, auch wenn es sich um eine Ganzzahl handelt, und die Daten werden erstellt. Sie müssen sie daher nach der Generierung selbst in eine Ganzzahl konvertieren.
for col in ['age', 'hours-per-week']:
df0_syn[col] = df0_syn[col].astype(int)
Übrigens haben wir im Originalpapier von TGAN der alten Version von CTGAN die Korrelation zwischen Datenelementen berechnet und untersucht, wie ähnlich die generierten Daten den Originaldaten sind. Vergleichen wir jedoch einfach die Verteilung des Zielelements "Einkommen" mit den Originaldaten und den generierten Daten.
print("original data")
print(df0_train['income'].value_counts(normalize=True))
# <=50K 0.759175
# >50K 0.240825
print("synthetic data")
print(df0_syn['income'].value_counts(normalize=True))
# <=50K 0.822426
# >50K 0.177574
Ursprünglich waren es uneinheitliche Daten mit einem kleinen Anteil von über 50.000, aber in den generierten Daten ist der Anteil von über 50.000 noch kleiner geworden. Bedeutet das, dass die Verteilung der Originaldaten nicht so genau trainiert wurde? Lassen Sie uns die Qualität der generierten Daten überprüfen, indem Sie XGBoost trainieren.
XGBoost lernen ①
Lassen Sie uns bewerten, wie ähnlich die generierten Daten den Originaldaten sind, indem Sie XGBoost anhand der generierten Daten trainieren und mit dem Fall vergleichen, in dem die Originaldaten verwendet werden. Darüber hinaus werden wir versuchen, durch Mischen der generierten Daten mit den Originaldaten und Trainieren der Daten die Genauigkeit des Modells im Vergleich zum Fall der Originaldaten allein zu verbessern.
Führen Sie zunächst eine Datenvorverarbeitung durch. Dieses Mal konvertieren wir einfach die Kategorievariable in einen numerischen Wert (Beschriftungscodierung). Es kann seltene Variablen geben, die nach dem Teilen nicht in kleinen Datenrahmen wie "df_test" angezeigt werden. Verwenden Sie daher zuerst den ursprünglichen Datenrahmen "df0", um ein Wörterbuch zu erstellen, das eine Liste jeder Kategorievariablen enthält. Erstellen Sie es und wenden Sie es mit dem scikit-learn Label Encoder auf jeden Datenrahmen an.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
category_dict = {}
for col in discrete_columns:
category_dict[col] = df0[col].unique()
def preprocessing(df, category_dict):
df_ = df.copy()
for k, v in category_dict.items():
le.fit(v)
df_[k] = le.transform(df_[k])
y = df_['income']
X = df_.drop('income', axis=1)
return X, y
Wenden Sie die oben erstellte Funktion auf jeden Datenrahmen an.
X0_train, y0_train = preprocessing(df0_train, category_dict)
print(X0_train.shape, y0_train.shape)
# (26048, 10) (26048,)
X_test, y_test = preprocessing(df_test, category_dict)
print(X_test.shape, y_test.shape)
# (6513, 10) (6513,)
X0_syn, y0_syn = preprocessing(df0_syn, category_dict)
print(X0_syn.shape, y0_syn.shape)
# (1000000, 10) (1000000,)
Trainieren Sie XGBoost und bereiten Sie eine Funktion vor, um die Genauigkeitsbewertung für die Testdaten auszugeben. Die Hyperparameter von XGBoost werden durch Rastersuche unter Verwendung aller Daten "df0" bestimmt.
def learn_predict(X, y, X_test, y_test):
xgb = XGBClassifier(learning_rate=0.1, max_depth=7, min_child_weight=4)
xgb.fit(X, y)
predictions = xgb.predict_proba(X_test)
auc = roc_auc_score(y_test, predictions[:, 1])
bool_pediction = (predictions[:, 1] >= 0.5).astype(int)
acc = accuracy_score(y_test, bool_pediction)
precision = precision_score(y_test, bool_pediction)
recall = recall_score(y_test, bool_pediction)
f1 = f1_score(y_test, bool_pediction)
print("AUC: {:.3f}".format(auc))
print("Accuracy {:.3f}".format(acc))
print("Precision: {:.3f}".format(precision))
print("Recall: {:.3f}".format(recall))
print("f1: {:.3f}".format(f1))
print("Confusion matrix:")
print(confusion_matrix(y_test, bool_pediction))
return (auc, acc, precision, recall, f1)
Precision, Recall, f1 gelten für Ziele mit einem Einkommen von mehr als 50.000.
Schauen wir uns zunächst die Lernergebnisse mit den ursprünglichen Trainingsdaten an (26.048 Fälle). Bei der Genauigkeitsbewertung werden immer die ursprünglichen Testdaten (6.513 Fälle) verwendet, die zuerst geteilt wurden.
ac0 = learn_predict(X0_train, y0_train, X_test, y_test)
# AUC: 0.888
# Accuracy: 0.838
# Precision: 0.699
# Recall 0.578
# f1: 0.632
# Confusion matrix:
# [[4554 391]
# [ 662 906]]
Wir werden dieses Ergebnis mit dem Ergebnis vergleichen, indem wir die generierten Daten als Basis verwenden.
Lernen Sie bei Verwendung der generierten Daten, indem Sie die Anzahl der Proben ändern, und sehen Sie, wie sich die Genauigkeit in Abhängigkeit von der Anzahl der Proben ändert.
n_samples = [1000, 3000, 10000, 30000, 100000, 300000, 1000000]
auc_list0 = []
acc_list0 = []
precision_list0 = []
recall_list0 = []
f1_list0 = []
for n in n_samples:
print("==" * 12)
print(" # of samples: ", n)
print("==" * 12)
ac = learn_predict(X0_syn[:n], y0_syn[:n], X_test, y_test)
print()
auc_list0.append(ac[0])
acc_list0.append(ac[1])
precision_list0.append(ac[2])
recall_list0.append(ac[3])
f1_list0.append(ac[4])
Die folgende Tabelle zeigt die Ergebnisse.
| # of samples | 1K | 3K | 10K | 30K | 100K | 300K | 1M | Original |
|---|---|---|---|---|---|---|---|---|
| AUC | 0.825 | 0.858 | 0.857 | 0.868 | 0.873 | 0.875 | 0.876 | 0.888 |
| Accuracy | 0.795 | 0.816 | 0.816 | 0.822 | 0.821 | 0.823 | 0.822 | 0.838 |
| Precision | 0.650 | 0.682 | 0.703 | 0.729 | 0.720 | 0.723 | 0.717 | 0.699 |
| Recall | 0.327 | 0.440 | 0.407 | 0.417 | 0.423 | 0.430 | 0.429 | 0.578 |
| f1 | 0.435 | 0.539 | 0.515 | 0.531 | 0.533 | 0.540 | 0.537 | 0.632 |
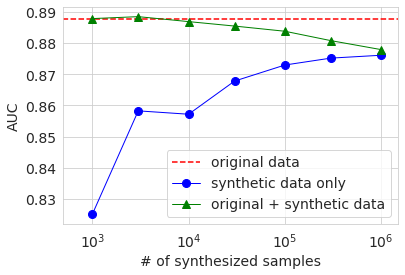
Obwohl das Verhalten nicht vollständig eintönig ist, neigt jeder Genauigkeitsindex dazu, mit zunehmender Anzahl von Proben an Genauigkeit zuzunehmen. Mit Ausnahme der Genauigkeit ist das Ergebnis der maximalen Anzahl von Proben jedoch auch niedriger als der Wert der Originaldaten. Da die Genauigkeitsbewertung an den Testdaten durchgeführt wird, die von den Originaldaten getrennt sind, deutet dieses Ergebnis darauf hin, dass die Verteilung der generierten Daten nicht vollständig mit den Originaldaten übereinstimmt. In Bezug auf die Genauigkeit ist die Genauigkeit umso besser als die Originaldaten, je größer die Anzahl der Abtastwerte der generierten Daten ist. Dies hängt jedoch damit zusammen, dass das Verhältnis der Anzahl der Abtastwerte über 50 KB kleiner ist als die Originaldaten in den generierten Daten. Ich glaube, es ist.
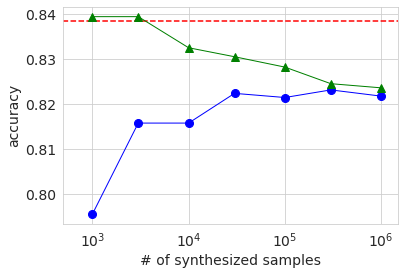
Die folgende Grafik zeigt die Ergebnisse von AUC, Genauigkeit und f1. Die horizontale Achse zeigt die Anzahl der Abtastwerte der generierten Daten als logarithmischen Wert. Die rot gepunktete Linie ist das Ergebnis der ursprünglichen Basisdaten, und der blaue Kreis ist das Ergebnis der generierten Daten. Das grüne Dreieck wird später beschrieben. Wenn man sich diese Diagramme ansieht, kann man sehen, dass die Genauigkeit tendenziell zunimmt, wenn die Anzahl der Abtastwerte der generierten Daten zunimmt, aber ein bestimmtes Niveau erreicht und nicht das Ergebnis der Originaldaten erreicht.
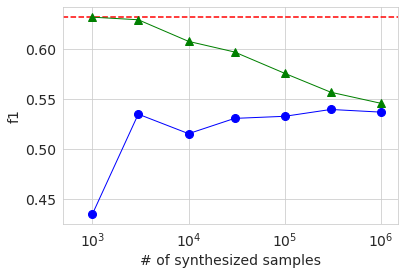
Als nächstes trainieren wir, indem wir die generierten Daten mit den Originaldaten mischen. Auch diesmal ändern wir die Anzahl der generierten Daten.
n_samples = [1000, 3000, 10000, 30000, 100000, 300000, 1000000]
auc_list0a = []
acc_list0a = []
precision_list0a = []
recall_list0a = []
f1_list0a = []
for n in n_samples:
X = pd.concat([X0_train, X0_syn[:n]])
y = pd.concat([y0_train, y0_syn[:n]])
print("==" * 12)
print(" # of samples: ", n)
print("==" * 12)
ac = learn_predict(X, y, X_test, y_test)
print()
auc_list0a.append(ac[0])
acc_list0a.append(ac[1])
precision_list0a.append(ac[2])
recall_list0a.append(ac[3])
f1_list0a.append(ac[4])
Die Ergebnisse sind in der obigen Grafik mit grünen Dreiecken dargestellt. Wenn die Anzahl der Stichproben generierter Daten mehrere Tausend beträgt, was ungefähr der Anzahl der Originaldaten entspricht, ist die Genauigkeit der verschiedenen ungefähr gleich oder geringfügig höher als die Basislinie der Originaldaten. Selbst wenn es überschreitet, ist der Unterschied sehr gering und es kann aus diesem Experiment nicht bestimmt werden, ob es sich um einen signifikanten Unterschied handelt. Wenn Sie die Anzahl der Stichproben generierter Daten erhöhen, verringert sich das Verhältnis der Originaldaten in den Daten, sodass die Genauigkeit abnimmt, und Sie können sehen, dass es sich allmählich der Genauigkeit nähert, wenn Sie nur mit den generierten Daten lernen.
XGBoost lernen ②
Übrigens denke ich, dass Sie in praktischen Situationen Daten mit gefälschten Daten aufblasen möchten, wenn die Anzahl der Daten, die zum Lernen verwendet werden können, gering ist. Unter der Annahme einer solchen Situation führen wir dieselbe Berechnung unter Verwendung der kleinen Trainingsdaten df1_train durch, die zuerst vorbereitet wurden. Die Anzahl der Zeilen in "df1_train" beträgt 2604, was 1/10 von "df0_train" entspricht.
Der Code ist der gleiche wie zuvor, daher werde ich ihn weglassen, aber ich habe CTGAN trainiert, 1 Million Datenzeilen df1_syn generiert und XGBoost trainiert.
Erstens sind die Ergebnisse des Lernens unter Verwendung von nur 2604 ursprünglichen Basisdaten wie folgt.
ac1 = learn_predict(X1_train, y1_train, X_test, y_test)
# AUC: 0.867
# Accuracy: 0.821
# Precision: 0.659
# Recall 0.534
# f1: 0.590
# [[4512 433]
# [ 730 838]]
Schließlich wird die Genauigkeit insgesamt verringert, da die Anzahl der Daten verringert wird.
Als nächstes wird das Ergebnis des Trainings unter Verwendung der generierten Daten in derselben Grafik wie zuvor angezeigt.
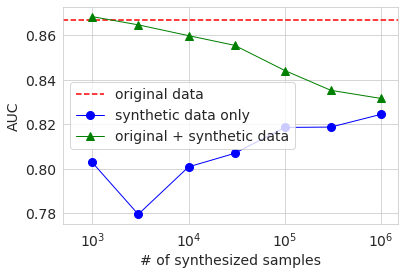
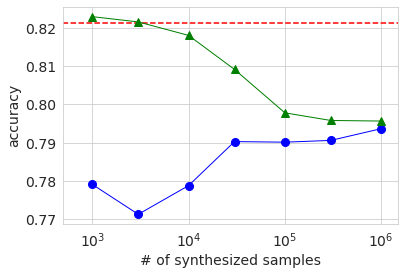
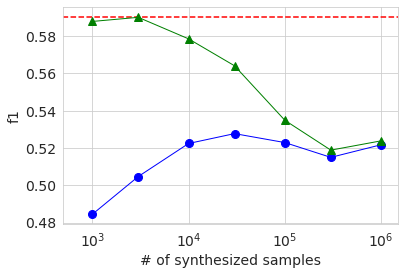
Die allgemeinen Verhaltenstrends sind dieselben wie bei großen Datenmengen. Der Grund, warum die AUC und Genauigkeit, wenn nur die generierten Daten verwendet werden (blauer Kreis), niedriger ist, wenn die Anzahl der Proben 3000 beträgt, als wenn sie 1000 beträgt, liegt wahrscheinlich darin, dass die Qualität der generierten Daten aufgrund der geringen Menge an Originaldaten stark variiert. Ich vermute. In jedem Fall wurde die Genauigkeit im Vergleich zur Verwendung nur der Originaldaten nicht wesentlich verbessert, selbst wenn die generierten Daten auf die gleiche Weise wie zuvor hinzugefügt und gelernt wurden.
abschließend
Ich hatte gehofft, dass GAN zum Aufblasen der Daten verwendet werden kann, um die Genauigkeit des Modells zu verbessern, aber dieses Experiment hat nicht funktioniert. Das Ergebnis der Verwendung nur der generierten Daten ist jedoch dem Fall der Verwendung nur der Originaldaten nicht so unterlegen. Wenn die Originaldaten aufgrund von Datenschutz- oder Informationssicherheitsproblemen nicht frei behandelt werden können, werden stattdessen gefälschte Daten generiert. Es kann Möglichkeiten geben, es zu verwenden, z. B. für.
Recommended Posts