[PYTHON] Tischkratzen mit schöner Suppe
Einführung
HTML-Tabellen können mit pandas 'pd.read_html () in wenigen Zeilen gekratzt werden, aber dieses Mal möchte ich Ihnen zeigen, wie man ohne read_html () kratzt.
Vorbereitung
Installieren Sie schöne Suppe. (Dieses Mal verwenden wir auch Pandas, um einen Datenrahmen zu erstellen. Installieren Sie ihn daher entsprechend.)
$ pip install beautifulsoup4 # or conda install
Politik
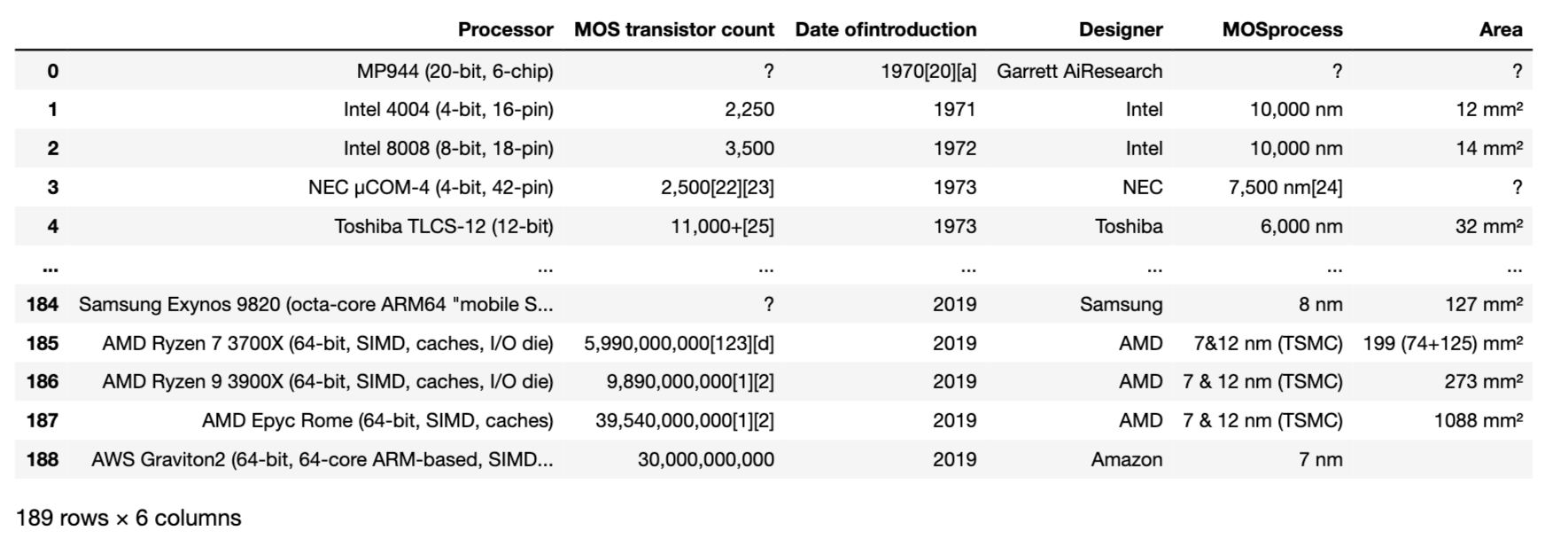
Als Beispiel erhalten wir dieses Mal die folgende Liste von CPUs von dieser Wikipedia-Seite.
Referenz
Als Referenz möchte ich hier die Methode zeigen, wenn die supereinfache Methode pd.read_html () verwendet wird.
import pandas as pd
url = 'https://en.wikipedia.org/wiki/Transistor_count' #URL der Zielwebseite
dfs = pd.read_html(url) #Wenn die Webseite mehrere Tabellen enthält, werden diese im Listenformat in dfs gespeichert
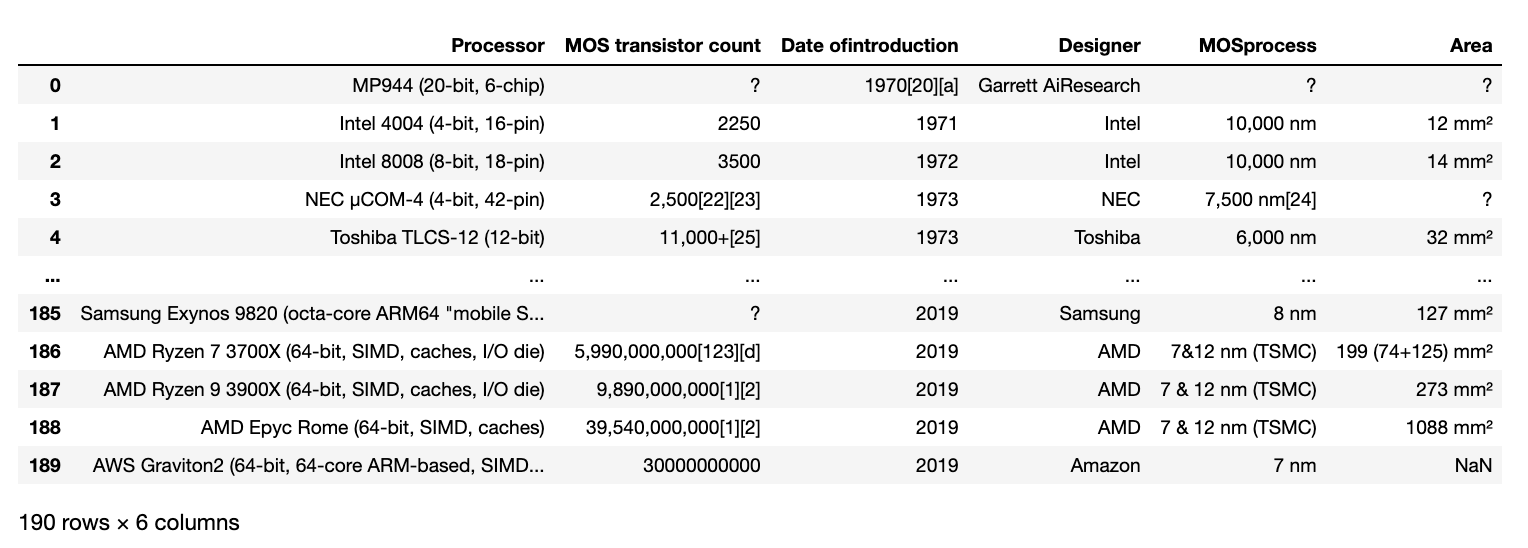
Dieses Mal scheint die Zieltabelle im ersten Index von dfs gespeichert zu sein. Geben wir also dfs [1] aus (dfs [0] speichert eine Tabelle einer anderen Klasse).
dfs[1]
Das Ausgabeergebnis sieht wie im Bild unten aus, und Sie können es sicher kratzen.
Überblick
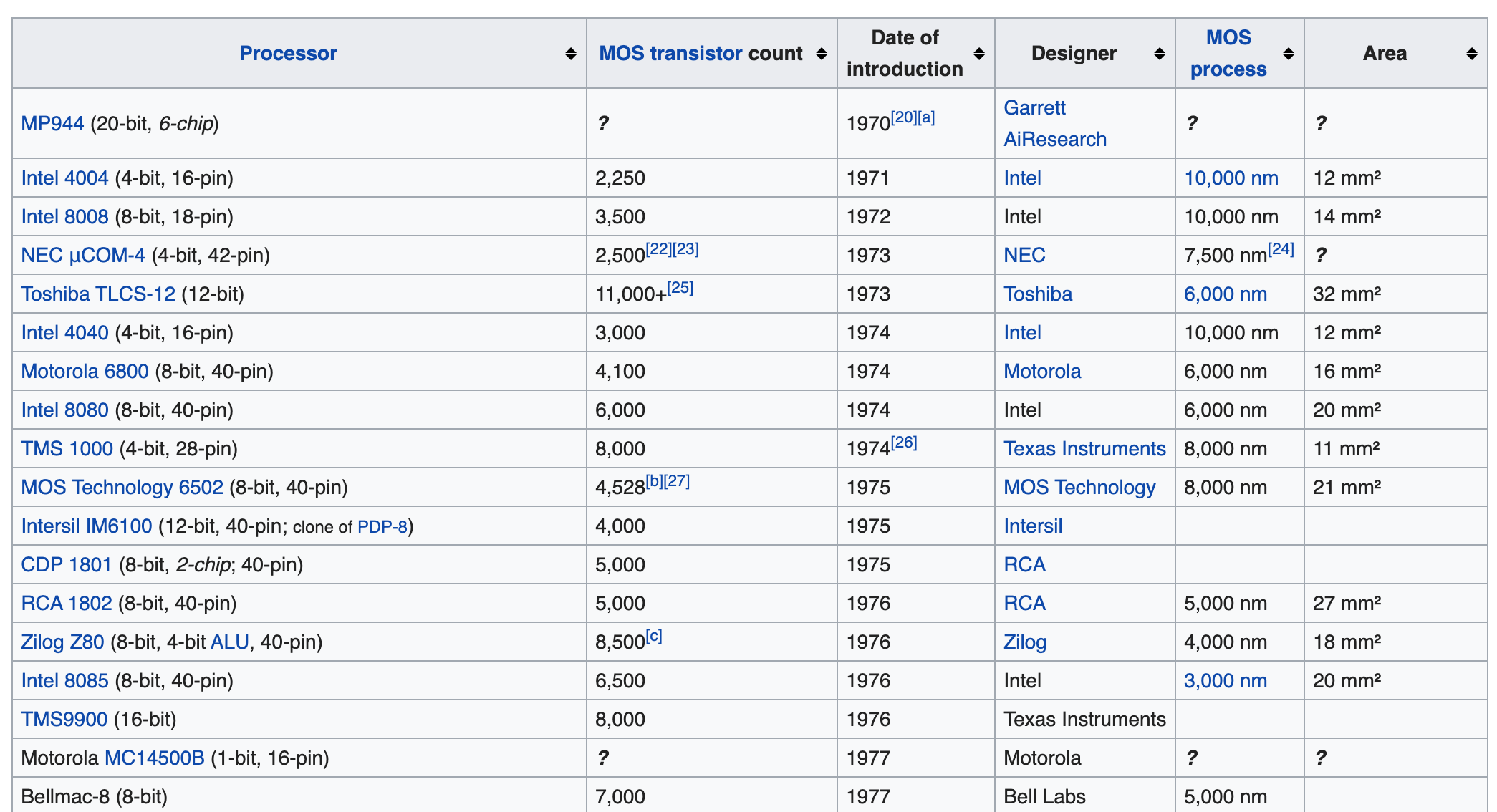
Bevor wir eine Tabelle mit BeautifulSoup kratzen, werfen wir einen Blick auf die Webseite, auf die sie geschabt wird. Lassen Sie uns über den zuvor gezeigten Link zur Wikipedia-Seite springen und die Entwicklertools öffnen (im Fall von Chrome können Sie sie anzeigen, indem Sie mit der rechten Maustaste auf die Tabelle klicken ⇒ inspizieren. Sie können auch Option + Befehl + I auswählen). Wenn Sie sich die HTML-Quelle der Seite mit den Entwicklertools ansehen, befindet sich die Zieltabelle unter dem Tag \
| (Tabellenzellendaten). Sie können sehen, dass es eine hierarchische Struktur hat (im Bild unten nicht sichtbar, aber es gibt ein \ | -Tag in der Hierarchie unter \ auf derselben Ebene wie das \ |
|---|
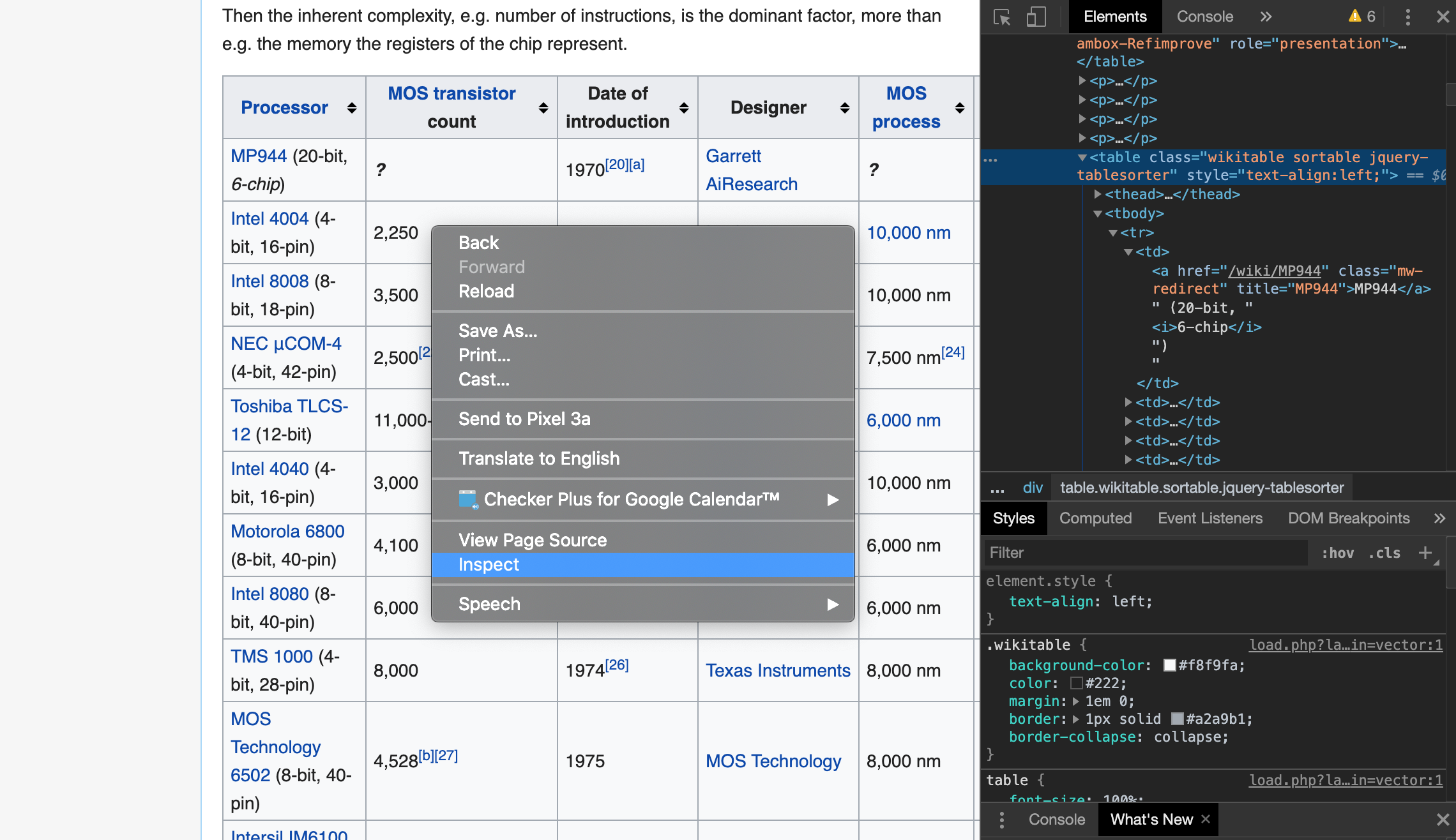
-Tags, und Sie können sehen, dass diese dem Header-Teil der Tabelle entsprechen.
| -Tags innerhalb des \ |
|---|---|
-Tags ab, die die Header-Komponenten aus der 0. Zeile der Tabelle sind, und extrahiert nur die Textkomponente (v.text).
Das Ergebnis ist wie folgt, aber \ n zeigt an, dass ein Zeilenumbruch ein Hindernis darstellt.
|