[PYTHON] Chainer, RNN und maschinelle Übersetzung
Verarbeitung natürlicher Sprache und neuronales Netz
In den letzten Jahren sind neuronale Netze auch im Bereich der Verarbeitung natürlicher Sprache sehr beliebt geworden.
Bei der Verarbeitung natürlicher Sprache sind die zu analysierenden Hauptobjekte Wortsequenzen und Syntaxbäume sowie Modelle, die auf einem wiederkehrenden neuronalen Netzwerk [^ 1] und einem rekursiven neuronalen Netzwerk [^ 1] basieren, um diese enthaltenen Informationen auszudrücken. Wird häufig verwendet. Das größte Merkmal davon ist, dass ** das neuronale Netz eine Art Datenstruktur hat **, es gibt nicht so viele Knoten pro Schicht, aber die Netzwerkverbindung ist kompliziert und jede Dateneingabe Es hat die Eigenschaft, dass sich die Form des Netzwerks selbst ändert. Aus diesem Grund gab es das Problem, dass es schwierig war, mit einem Toolkit zu erstellen, das das traditionelle neuronale Feedforward-Netzwerk übernahm.
Chainer ist ein leistungsstarkes neuronales Netz-Framework, das solche Probleme im Allgemeinen löst. Es kann verwendet werden, wenn Sie die Python-Syntax und ein wenig NumPy kennen und die Berechnungsformel im Quellcode automatisch als Verbindungsinformation des neuronalen Netzes gespeichert wird. ** Wenn Sie die Eingabedaten analysieren, wird dies automatisch der Fall sein Es gibt eine ~~ Cheat-ähnliche ~~ Funktion namens **, die mit einem neuronalen Netz analysiert werden kann.
Die Chainer-Beispielsammlung, die ich kürzlich niedergeschrieben habe, implementiert auch Sprachmodelle, Wortteiler, Übersetzungsmodelle usw., aber alle sind grundlegende Teile (im Code). Die Vorwärtsfunktion kann in einem halben Tag oder in einer Stunde implementiert werden, wenn sie kurz ist. Wie Sie dem Beispiel entnehmen können, ist es eher so, als würden Sie den größten Teil Ihres Aufwands für Peripherie-Code aufwenden, der Ihre Daten organisiert.
In diesem Artikel erklären wir hauptsächlich, wie das wiederkehrende neuronale Netzwerk in Chainer und das Encoder-Decoder-Übersetzungsmodell implementiert werden, das eine Anwendung in der Verarbeitung natürlicher Sprache darstellt.
- Der Inhalt des Artikels basiert auf Chainer 1.4 oder früher. Wir werden die 1.5-Serie unterstützen, indem wir die Situation beobachten. * *
Recurrent Neural Network
Das grundlegendste wiederkehrende neuronale Netzwerk (RNN) ist ein orthodoxes dreischichtiges neuronales Netz mit versteckter Schichtrückkopplung, wie in der folgenden Abbildung gezeigt.
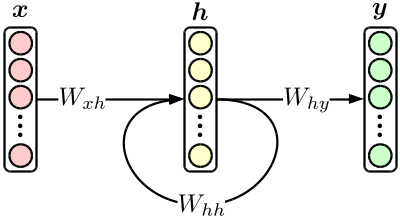
Obwohl es sich um ein einfaches Modell handelt, wird das später eingeführte Übersetzungsmodell durch Kombinieren von RNNs erstellt. Darüber hinaus ist RNN allein ein ausgezeichnetes Produkt, das das herkömmliche * N * -Gramm-Modell bei Verwendung in einem Sprachmodell leicht übertreffen kann. [^ 2]
Wenn Sie die obige Zahl in die Formel eintragen,
\begin{align}
{\bf h}_n & = \tanh \bigl( W_{xh} \cdot {\bf x}_n + W_{hh} \cdot {\bf h}_{n-1} \bigr), \\
{\bf y}_n & = {\rm softmax} \bigl( W_{hy} \cdot {\bf h}_n \bigr)
\end{align}
Und verwenden Sie dies als Berechnungsformel für Chainer.
Betrachten wir zunächst ein RNN-Sprachmodell, das "eine Wort-ID eingibt und die nächste Wort-ID vorhersagt". [^ 3]
Definieren Sie zunächst das ** Modell **. Ein Modell ist ein ** Satz trainierbarer Parameter **, und $ W_ {\ * \ *} $ in der obigen Abbildung entspricht diesem. In diesem Fall sind $ W_ {\ * \ *} $ alle linearen Aktionselemente (Matrix). Verwenden Sie daher "Linear" oder "EmbedID" in "chainer.functions". EmbedID ist Linear, wenn die Eingabeseite ein One-Hot-Vektor ist und Sie die ID des Zündelements anstelle des Vektors übergeben können.
from chainer import FunctionSet
from chainer.functions import *
model = FunctionSet(
w_xh = EmbedID(VOCAB_SIZE, HIDDEN_SIZE), #Eingabeebene(one-hot) ->Versteckte Ebene
w_hh = Linear(HIDDEN_SIZE, HIDDEN_SIZE), #Versteckte Ebene->Versteckte Ebene
w_hy = Linear(HIDDEN_SIZE, VOCAB_SIZE), #Versteckte Ebene->Ausgabeschicht
)
VOCAB_SIZE repräsentiert die Anzahl der Worttypen und HIDDEN_SIZE repräsentiert die Dimension der verborgenen Ebene.
Definieren Sie als Nächstes die Funktion "Weiterleiten", mit der die eigentliche Analyse durchgeführt wird. Hier wird im Wesentlichen die Netzwerkstruktur in der obigen Figur gemäß der Modelldefinition und den tatsächlichen Eingabedaten reproduziert und der endgültige gewünschte Wert berechnet. Im Fall des Sprachmodells wird die in der folgenden Formel ausgedrückte ** Satzkombinationswahrscheinlichkeit ** berechnet.
\begin{align}
\log {\rm Pr} \bigl( {\bf w} \bigr) & = \sum_{n=1}^{|{\bf w}|} \log {\rm Pr} \bigl( w_n \ \big| \ w_1, w_2, \cdots, w_{n-1} \bigr) \\
& = \sum_{n=1}^{|{\bf w}|} \log {\bf y}_n\big[ {\rm index} \bigl( w_n \bigr) \big]
\end{align}
Das Folgende ist ein Codebeispiel, aber da Chainer auf der Mini-Batch-Verarbeitung basiert, wird die Datendimension um eins erhöht (die Batch-Verarbeitung wird im Code nicht ausgeführt).
import math
import numpy as np
from chainer import Variable
from chainer.functions import *
def forward(sentence, model): #Satz ist ein Array von str. Angenommene Ausgabe wie MeCab.
sentence = [convert_to_your_word_id(word) for word in sentence] #Konvertieren Sie Wörter in IDs. Implementieren Sie es selbst.
h = Variable(np.zeros((1, HIDDEN_SIZE), dtype=np.float32)) #Anfangswert der verborgenen Ebene
log_joint_prob = float(0) #Satzverbindungswahrscheinlichkeit
for word in sentence:
x = Variable(np.array([[word]], dtype=np.int32)) #Nächste Eingabeebene
y = softmax(model.w_hy(h)) #Wahrscheinlichkeitsverteilung des nächsten Wortes
log_joint_prob += math.log(y.data[0][word]) #Aktualisierung der Verbindungswahrscheinlichkeit
h = tanh(model.w_xh(x) + model.w_hh(h)) #Versteckte Ebenenaktualisierung
return log_joint_prob #Gibt das Berechnungsergebnis der Verknüpfungswahrscheinlichkeit zurück
Jetzt können Sie die Wahrscheinlichkeit des Satzes finden. Das Obige beinhaltet jedoch nicht die Berechnung der Verlustfunktion zum Trainieren des Modells. Da die Softmax-Funktion dieses Mal in der Endphase verwendet wird, verwenden Sie chainer.functions.softmax_cross_entropy, um die Kreuzentropie mit der richtigen Antwort zu finden und als Verlustfunktion zu verwenden.
def forward(sentence, model):
...
accum_loss = Variable(np.zeros((), dtype=np.float32)) #Anfangswert des kumulierten Verlustes
...
for word in sentence:
x = Variable(np.array([[word]], dtype=np.int32)) #Nächste Eingabeebene(=Diese richtige Antwort)
u = model.w_hy(h)
accum_loss += softmax_cross_entropy(u, x) #Anhäufung von Verlusten
y = softmax(u)
...
return log_joint_prob, accum_loss #Der kumulierte Verlust wird ebenfalls zurückgegeben
Jetzt kannst du lernen.
from chainer.optimizers import *
...
def train(sentence_set, model):
opt = SGD() #Verwendet die probabilistische Gradientenmethode
opt.setup(model) #Initialisierung des Lernenden
for sentence in sentence_set:
opt.zero_grad(); #Gradienteninitialisierung
log_joint_prob, accum_loss = forward(sentence, model) #Verlustberechnung
accum_loss.backward() #Fehler bei der Weitergabe
opt.clip_grads(10) #Zu großen Farbverlauf unterdrücken
opt.update() #Parameteraktualisierung
Grundsätzlich ist dies die einzige Verarbeitung von Chainer. In der Vergangenheit habe ich ein Programm mit einer unangenehmen Anzahl von Zeilen für ein solches neuronales Netz geschrieben, aber Chainer hat fast alle lästigen Berechnungen in der Python-Syntax verborgen, daher ist eine so kurze Beschreibung Es wird möglich sein. Solange Sie sich an die Verwendung von Chainer erinnern, können Sie das kürzlich vorgeschlagene Modell oder das Originalmodell, das Sie gerade entwickelt haben, schnell schreiben und ausprobieren. [^ 4]
Encoder-Decoder-Übersetzungsmodell
Als etwas kompliziertes Beispiel für die Anwendung von RNN implementieren wir das ** Encoder-Decoder-Übersetzungsmodell **, eine maschinelle Übersetzungsmethode unter Verwendung eines neuronalen Netzes. Dies ist ein Übersetzungsmodell, bei dem der gesamte Prozess von der Eingabe bis zur Ausgabe durch ein neuronales Netz beschrieben wird. Trotz seiner Einfachheit erreicht es eine Genauigkeit, die mit der herkömmlicher Übersetzungsmodelle vergleichbar ist, und überraschte die Forscher zum Zeitpunkt der Präsentation. Wurde begrüßt.
Es gibt verschiedene Varianten des Encoder-Decoder-Übersetzungsmodells, aber hier werde ich das unten gezeigte Modell schreiben, das auch in meiner Beispielsammlung implementiert ist.
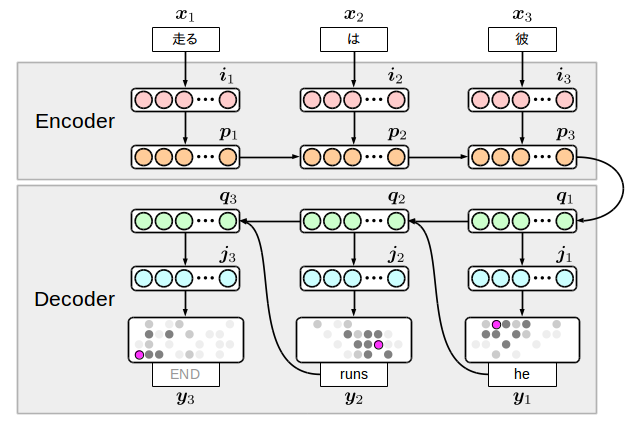
Die Idee ist einfach: Bereiten Sie zwei RNNs auf der Seite der Eingabesprache (Encoder) und der Seite der Ausgabesprache (Decoder) vor und verbinden Sie sie mit einem Zwischenknoten. Das Interessante an diesem Modell ist, dass die Ausgabeseite zusammen mit dem Wort einen Terminator generiert. ** Das Modell selbst entscheidet über das Ende der Übersetzung **. Um es anders herum auszudrücken: Wenn Sie dieses Terminalsymbol nicht lernen, werden Sie am Ende eine unendliche Anzahl von Wörtern generieren. Wenn Sie also tatsächlich eine angemessene Anzahl von Wörtern generieren, diese jedoch nicht endet, müssen Sie den Prozess stoppen. es gibt.
$ {\ bf i} $ und $ {\ bf j} $ werden als ** Einbettungsebenen ** bezeichnet und repräsentieren dimensional komprimierte Wortinformationen. Auch die Wortfolge der Eingabe ist invertiert, es wurde jedoch festgestellt, dass dies experimentell zu guten Übersetzungsergebnissen führt. Der Grund ist nicht sehr klar, wird aber manchmal so interpretiert, dass sich Codierer und Decodierer in einer Beziehung zwischen Umwandlung und Umkehrung befinden.
Ich werde den Code sofort schreiben, aber zuerst fügen wir ihn in die Berechnungsformel ein. Es sieht aus wie das:
\begin{align}
{\bf i}_n & = \tanh \bigl( W_{xi} \cdot {\bf x}_n \bigr), \\
{\bf p}_n & = {\rm LSTM} \bigl( W_{ip} \cdot {\bf i}_n + W_{pp} \cdot {\bf p}_{n-1} \bigr), \\
{\bf q}_1 & = {\rm LSTM} \bigl( W_{pq} \cdot {\bf p}_{|{\bf w}|} \bigr), \\
{\bf q}_m & = {\rm LSTM} \bigl( W_{yq} \cdot {\bf y}_{m-1} + W_{qq} \cdot {\bf q}_{m-1} \bigr), \\
{\bf j}_m & = \tanh \bigl( W_{qj} \cdot {\bf q}_m \bigr), \\
{\bf y}_m & = {\rm softmax} \bigl( W_{jy} \cdot {\bf j}_m \bigr).
\end{align}
Hier wird LSTM vollständig für den Übergang zwischen den verborgenen Ebenen $ {\ bf p} $ und $ {\ bf q} $ verwendet. [^ 5] kann anhand der Abbildung verstanden werden, aber da die Encoderseite mit einer normalen Aktivierungsfunktion ziemlich weit von der Position $ {\ bf y} $ entfernt ist, an der der Verlust tatsächlich berechnet wird Dies liegt daran, dass es ein Problem gibt, das nicht gut gelernt werden kann. Ein solches Modell erfordert das Vorlernen von Gewichten oder eines Elements, in dem Abhängigkeiten mit großer Reichweite wie LSTM gespeichert werden können.
Wenn Sie sich die obige Abbildung und Formel ansehen, sehen Sie übrigens, dass es 8 Arten von Übergängen gibt: $ W_ {\ * \ *} $. Dies sind die Parameter, die wir dieses Mal lernen werden, und wir werden sie in der Modelldefinition auflisten.
model = FunctionSet(
w_xi = EmbedID(SRC_VOCAB_SIZE, SRC_EMBED_SIZE), #Eingabeebene(one-hot) ->Eingebettete Ebene eingeben
w_ip = Linear(SRC_EMBED_SIZE, 4 * HIDDEN_SIZE), #Eingebettete Ebene eingeben->Versteckte Ebene eingeben
w_pp = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), #Versteckte Ebene eingeben->Versteckte Ebene eingeben
w_pq = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), #Versteckte Ebene eingeben->Versteckte Ebene ausgeben
w_yq = EmbedID(TRG_VOCAB_SIZE, 4 * HIDDEN_SIZE), #Ausgabeschicht(one-hot) ->Versteckte Ebene ausgeben
w_qq = Linear(HIDDEN_SIZE, 4 * HIDDEN_SIZE), #Versteckte Ebene ausgeben->Versteckte Ebene ausgeben
w_qj = Linear(HIDDEN_SIZE, TRG_EMBED_SIZE), #Versteckte Ebene ausgeben->Eingebettete Ebene ausgeben
w_jy = Linear(TRG_EMBED_SIZE, TRG_VOCAB_SIZE), #Versteckte Ebene ausgeben->Versteckte Ebene ausgeben
)
Es ist notwendig, auf die Parameter $ W_ {ip}, W_ {pp}, W_ {pq}, W_ {yq}, W_ {qq} $ zu achten, die in das LSTM eingegeben werden. Sie müssen die Dimensionen mit dem Faktor vier multiplizieren. Das von Chainer implementierte LSTM weist zusätzlich zum normalen Eingang drei Arten von Eingängen auf: Eingangsgatter, Ausgangsgatter und Vergessensgatter, und eine solche Implementierung ist erforderlich, da diese zu einem Vektor kombiniert werden. Ich bin. [^ 6]
Als nächstes schreiben Sie die Vorwärtsfunktion. Beachten Sie, dass LSTM einen internen Status hat, sodass wir bei der Berechnung von $ {\ bf p} $ und $ {\ bf q} $ eine weitere Variable benötigen.
# src_sentence:Wortzeichenfolge, die Sie übersetzen möchten e.g. ['er', 'Ist', 'Lauf']
# trg_sentence:Wortfolge, die die Übersetzung der richtigen Antwort darstellt e.g. ['he', 'runs']
# training:Lernen oder Vorhersage? Beeinflusst das Verhalten des Decoders.
def forward(src_sentence, trg_sentence, model, training):
#Konvertierung in Wort-ID (entsprechend selbst implementieren)
#Fügen Sie der korrekten Übersetzung einen Terminator hinzu.
src_sentence = [convert_to_your_src_id(word) for word in src_sentence]
trg_sentence = [convert_to_your_trg_id(word) for wprd in trg_sentence] + [END_OF_SENTENCE]
#Anfangswert des internen LSTM-Zustands
c = Variable(np.zeros((1, HIDDEN_SIZE), dtype=np.float32))
#Encoder
for word in reversed(src_sentence):
x = Variable(np.array([[word]], dtype=np.int32))
i = tanh(model.w_xi(x))
c, p = lstm(c, model.w_ip(i) + model.w_pp(p))
#Encoder->Decoder
c, q = lstm(c, model.w_pq(p))
#Decoder
if training:
#Verwenden Sie beim Lernen die richtige Übersetzung als y und geben Sie den kumulierten Verlust als Ergebnis der Weiterleitung zurück.
accum_loss = np.zeros((), dtype=np.float32)
for word in trg_sentence:
j = tanh(model.w_qj(q))
y = model.w_jy(j)
t = Variable(np.array([[word]], dtype=np.int32))
accum_loss += softmax_cross_entropy(y, t)
c, q = lstm(c, model.w_yq(t), model.w_qq(q))
return accum_loss
else:
#Zum Zeitpunkt der Vorhersage wird das vom Übersetzer erzeugte y für die nächste Eingabe verwendet, und die als Ergebnis der Weiterleitung erzeugte Wortfolge wird zurückgegeben.
#Wählen Sie das Wort mit der höchsten Wahrscheinlichkeit in y aus, aber Sie müssen kein Softmax nehmen.
hyp_sentence = []
while len(hyp_sentence) < 100: #Generieren Sie nicht mehr als 100 Wörter
j = tanh(model.w_qj(q))
y = model.w_jy(j)
word = y.data.argmax(1)[0]
if word == END_OF_SENTENCE:
break #Beenden, weil das Beendigungssymbol generiert wurde
hyp_sentence.append(convert_to_your_trg_str(word))
c, q = lstm(c, model.w_yq(y), model.w_qq(q))
return hyp_sentence
Es ist etwas lang, aber wenn Sie es sorgfältig lesen, werden Sie feststellen, dass die Pfeile in der obigen Abbildung jedem Teil des Codes entsprechen. Wenn Sie danach einen RNN-ähnlichen Lernenden außerhalb dieses Codes hinzufügen, ist dies in Ordnung und Sie können Ihre eigenen Übersetzungsdaten lernen.
Wie dieses Modell lernt, lernen wir anhand der Beispieldaten der japanisch-englischen Übersetzung in hier. Wenn Sie ungefähr 10.000 Sätze mit 2000 Vokabeln, 100 eingebetteten Schichten und 100 versteckten Schichten studieren, erhalten Sie die folgenden Übersetzungsergebnisse für jede Generation (ich habe das Programm der Beispielsammlung zum Lernen verwendet). 21.07.2017: Die Verknüpfung der Beispieldaten wurde erneut verknüpft. </ font>
Eingang:Wie war dein Urlaub?
Ausgabe:
1: the is is a of of <unk> .
2: the 't is a <unk> of <unk> .
3: it is a good of the <unk> .
4: how is the <unk> to be ?
5: how do you have a <unk> ?
6: how do you have a <unk> ?
7: how did you like the <unk> ?
8: how did you like the weather ?
9: how did you like the weather ?
10: how did you like your work ?
11: how did you like your vacation ?
12: how did you like your vacation ?
13: how did you the weather to drink ?
14: how did you like your vacation ?
15: how did you like your vacation ?
16: how did you like your vacation ?
17: how did you like your vacation ?
18: how did you like your vacation ?
19: how did you enjoy your vacation ?
20: how did you enjoy your vacation now ?
21: how did you enjoy your vacation for you ?
22: how did you enjoy your vacation ?
Eingang:Sie sieht glücklich aus.
Ausgabe:
1: she is a of of of .
2: she is a good of of .
3: she is a good of <unk> .
4: she is a good of <unk> .
5: she is a good of <unk> .
6: she is a good of his morning .
7: she is a good of his morning .
8: she is a good of his morning .
9: she is a good of his morning .
11: she is a good of his morning .
12: she is a good of his morning .
13: she is a good of his morning .
14: she is a good of his morning .
15: she is a good at tennis .
16: she is a good at tennis .
17: she is a good at tennis .
18: she is a good of the time .
19: she seems to be very very happy .
20: she is going to be a student .
21: she seems to be very very happy .
22: she seems to be very very happy .
23: she seems to be very happy .
Eingang:Mir ist heute Morgen kalt.
Ausgabe:
1: i 'm a of of of .
2: i 'm a <unk> of the <unk> .
3: it is a good of <unk> .
4: it is a good of <unk> .
5: it is a good of <unk> .
6: it is a good of the day .
7: it 's a good of <unk> .
8: it 's a good of <unk> .
9: it 's a good of <unk> .
10: it 's a good of <unk> today .
11: i 'm a good <unk> of time .
12: i 'm a good <unk> of time .
13: i 'm a good <unk> of time .
14: i 'm very busy this <unk> today .
15: i 'm very busy this morning time .
16: i 'm very busy this morning time .
17: i 'm very busy this time .
18: i 'm very busy this time .
19: i have a lot of cold here .
20: i have a lot of <unk> here .
21: i have a lot of <unk> time .
22: i 'm very busy this morning time .
23: i have a lot of cold here .
24: i have a lot of cold here .
25: i have a lot of that morning .
26: i have a lot of cold here .
27: i have a lot of cold here .
28: i have a cold , will do .
29: i feel cold this morning this morning .
Was Sie aus den Ergebnissen ersehen können, ist, dass Sie zuerst lernen, grobe Grammatik und breit sitzende Wörter zu generieren, und sich dann schrittweise anpassen, um sich auf bestimmte Wörter zu verlassen. Es kann angenommen werden, dass dies daran liegt, dass es mit fortschreitender Konvergenz des neuronalen Netzes möglich wird, den Unterschied in der Bedeutung zwischen Wörtern klar zu erfassen. Das letzte Beispiel war interessant, und es scheint, dass er fälschlicherweise "sich heute Morgen kalt fühlen" und "sich erkälten" bis zum Ende der Studie. Solche semantischen Fehler treten nur bei neuronalen Netzen auf und treten bei herkömmlichen maschinellen Übersetzungstechniken wahrscheinlich nicht auf. Die Tatsache, dass diese unterschiedlichen Eigenschaften auch als einer der Gründe angesehen werden, warum neuronale Netze bei der Verarbeitung natürlicher Sprache Aufmerksamkeit erregen.
[^ 1]: Beide werden als RNN abgekürzt, daher ist es verwirrend. Es gibt auch Modelle wie R2NN (rekursives wiederkehrendes neuronales Netzwerk), die die Verwirrung möglicherweise in die falsche Richtung gelenkt haben.
[^ 2]: Im Gegensatz zum * N * -Gramm-Modell ist es jedoch nicht möglich, nur einen Teil des Satzes zu extrahieren und die Punktzahl zu berechnen, also in Feldern wie der maschinellen Übersetzung, in denen die Analyse vorangetrieben wird, während die Punktzahl schrittweise berechnet wird. Es gibt auch das Problem, dass die Verwendung begrenzt ist.
[^ 3]: Es gibt verschiedene Möglichkeiten, ein Wort in eine Wort-ID umzuwandeln, und die verwendete Methode wirkt sich direkt auf die Genauigkeit des Modells aus. Die bisherige Erklärung weicht vom Zweck des Artikels ab, daher werde ich sie hier nicht erläutern.
[^ 4]: Die Lernzeit ist ein Engpass. Wenn Sie also wirklich eine Try-and-Error-Entwicklung durchführen möchten, sollten Sie eine GPU haben.
[^ 5]: Der Einfachheit halber ignoriert die Formel den internen Zustand des LSTM.
[^ 6]: Eine neuere Implementierung, chainer.links, hat eine Version von LSTM, die die Implementierung hier verbirgt.
Recommended Posts