[PYTHON] Paralleles Lernen von Deep Learning durch Keras und Kubernetes
Paralleles Lernen von Deep Learning durch Keras und Kubernetes
Ich habe vorhin geschrieben, dass Keras CNTK unterstützt.
Führen Sie Keras mit CNTK-Backend unter CentOS aus
Keras kann jetzt Theano, TensorFlow und CNTK als Backends verwenden, um verschiedene Frameworks im selben Programm zu verwenden. Ich denke, der Vorteil der Erweiterung des Backends von Keras besteht darin, dass Sie das Framework ändern und lernen können, indem Sie einfach die Umgebungsvariablen ändern. Durch Ändern des Frameworks wird (wahrscheinlich) das neuronale Netzwerkmodell selbst nicht geändert, wenn das Programm identisch ist, aber die Genauigkeit und Geschwindigkeit ändern sich geringfügig. Alternativ können Sie die in jedem Framework trainierten Modelle zusammenstellen und ableiten. Ich habe mir ein Ensemble aus mehreren Frameworks ausgedacht, also habe ich es tatsächlich versucht.
Das Programm und yml von Kubernetes finden Sie unten. https://github.com/shibuiwilliam/keras_multibackend
Lernen Sie mehrere Keras-Backends parallel
Es ist langweilig, mehrere Deep-Learning-Frameworks nacheinander von Keras mit demselben Programm auszuprobieren. Deshalb habe ich versucht, jedes Framework mithilfe von Kubernetes parallel zu trainieren. Das Bild ist wie folgt.
Es ist langweilig, nur nacheinander zu lernen.

Lass uns parallel lernen.
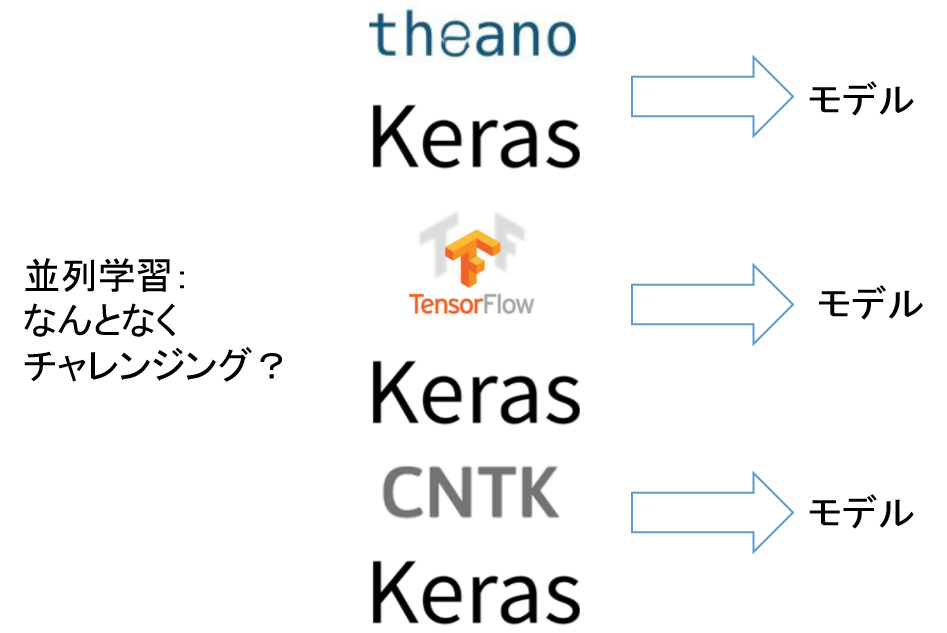
Gesamtbild
Lernen Sie parallel in einem Docker-Container mit Kubernetes Deep Learning. Das Gesamtbild ist wie folgt.

Es sind sowohl Plattform- als auch Programmkonfigurationen erforderlich.
Plattform
Bereiten Sie drei virtuelle Maschinen vor. Diesmal ist es CentOS 7.3. Machen Sie VM1 zu einem NFS-Server und stellen Sie das freigegebene Verzeichnis auf VM2 und VM3 bereit. Platzieren Sie die Keras-Lern- und Inferenzprogramme im freigegebenen Verzeichnis. Die VMs 1, 2 und 3 können alle auf Keras-Lern- und Inferenzprogramme zugreifen.
Bilden Sie mit VM1,2,3 einen Kubernetes-Cluster. Erstellen Sie VM1,2,3 mit Keras, Theano, TensorFlow, CNTK und anderen installierten Docker-Images.
Die diesmal verwendete Docker-Datei ist unten aufgeführt.
https://github.com/shibuiwilliam/keras_multibackend
Kubernetes führt Cifar 10 CNN-Schulungen für jedes Framework als Job durch. Wir werden 3 Arten von yml für Job vorbereiten. Definieren Sie die Werte jeder Umgebungsvariablen KERAS_BACKEND als Theano, TensorFlow und CNTK.
Die Jobdefinition yml von Kubernetes lautet wie folgt. Zuallererst ist es zum Lernen. Obwohl CNTK dargestellt ist, ändern Tensorflow und Theano nur den Wert von Keras_Backend.
apiVersion: batch/v1
kind: Job
metadata:
name: kerascntk
spec:
template:
spec:
restartPolicy: Never
volumes:
- name: nfstest
nfs:
server: 10.249.20.65
path: "/tmp/nfstest/"
containers:
- name: kerascntk
image: jupyter:1.52
volumeMounts:
- name: nfstest
mountPath: "/tmp/nfstest/"
env:
- name: KERAS_BACKEND
value: "cntk"
command: ["python"]
args: ["/tmp/nfstest/cifar_train.py"]
Zur Schlussfolgerung. Inferenz wird mit 3 Backend-Inferenzen in Python summiert, sodass Sie unten nur eine benötigen.
apiVersion: batch/v1
kind: Job
metadata:
name: pred
spec:
template:
spec:
restartPolicy: Never
volumes:
- name: nfstest
nfs:
server: 10.249.20.65
path: "/tmp/nfstest/"
containers:
- name: pred
image: jupyter:1.52
volumeMounts:
- name: nfstest
mountPath: "/tmp/nfstest/"
command: ["python"]
args: ["/tmp/nfstest/cifar_pred.py"]
Programm
Bereiten Sie ein Keras-Lernprogramm und ein Inferenzprogramm vor. Es ist nicht erforderlich, jedes Framework separat zu erstellen. Da die Umgebungsvariable KERAS_BACKEND in yml von Kubernetes Job definiert und unterteilt ist, gibt es ein Lernprogramm und ein Inferenzprogramm.
Jedes Programm ist wie folgt. Zuallererst ist es zum Lernen. Ich habe keine besonderen Anstrengungen unternommen. Es ist ein gewöhnliches VGG-ähnliches CNN. Die Anzahl der Epochen beträgt 50, aber da auch das frühe Stoppen festgelegt ist, soll es in etwa 20 Epochen enden. Außerdem werden 100 Bilder von Testdaten zur Verwendung als Inferenz von der Bewertung ausgeschlossen.
#Zum Lernen
# see its environment variable
import os
kerasBKED = os.environ["KERAS_BACKEND"]
print(kerasBKED)
# imports
import keras
from keras.models import load_model
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.callbacks import EarlyStopping, ModelCheckpoint
import pickle
import numpy as np
# variables
batch_size = 32
num_classes = 10
epochs = 50
# loading and reshaping cifar10 data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
# leave out 100 images for prediction
x_test1 = x_test[100:,:]
x_test2 = x_test[:100,:]
y_test1 = y_test[100:,:]
y_test2 = y_test[:100,:]
print(x_test1.shape, x_test2.shape, y_test1.shape, y_test2.shape)
# only test1 data is used for validation
# VGG-like neural network model
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
opt = keras.optimizers.adam()
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
# Add checkpoint and earlystopping
chkpt = '/tmp/nfstest/cifar_weights/' + kerasBKED + '_weights.{epoch:02d}-{loss:.2f}-{val_loss:.2f}.hdf5'
cp_cb = ModelCheckpoint(filepath = chkpt, monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
es_cb = EarlyStopping(monitor='val_loss', patience=1, verbose=1, mode='auto')
# fit the model
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test1, y_test1),
callbacks=[cp_cb, es_cb],
shuffle=True)
# score and save the model
score = model.evaluate(x_test1, y_test1, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
saveDir = "/tmp/nfstest/cifar_model/"
if not os.path.isdir(saveDir):
os.makedirs(saveDir)
modelName = "{0}_{1}_model.hdf5".format(kerasBKED, score[1])
model_path = os.path.join(saveDir, modelName)
model.save(model_path)
Speichern Sie das Modell am Ende des Trainings im NFS-Verzeichnis. Infolgedessen werden drei Arten von Modellen im NFS-Verzeichnis gespeichert. Inference verwendet diese drei Modelle. Verwenden Sie zur Schlussfolgerung 100 Bilder, die aus den Testdaten extrahiert wurden. Schliessen Sie, indem Sie die drei Arten von Modelldateien (Theano, Tensorflow, CNTK) aufrufen, die durch Lernen erstellt wurden. Da es in jedem Modell einen Unterschied in der Genauigkeit des Trainings gibt, wird die Inferenz mit der Genauigkeit multipliziert und schließlich durch die Summe der Genauigkeit geteilt. Es sieht aus wie ein Ensemblemodell, hat aber keinen theoretischen Hintergrund.
#Zum Nachdenken
# import
import keras
from keras.models import load_model
from keras.datasets import cifar10
import os
# variables
batch_size = 32
num_classes = 10
# load and reshape data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
x_test1 = x_test[100:,:]
x_test2 = x_test[:100,:]
y_test1 = y_test[100:,:]
y_test2 = y_test[:100,:]
# test2 data is used for prediction
# get a list of model files
backList = ["cntk", "tensorflow", "theano"]
saveDir = "/tmp/nfstest/cifar_model/"
files = os.listdir(saveDir)
filesList = [f for f in files if os.path.isfile(os.path.join(saveDir, f))]
filesList
# predict using each model
prediction = 0
sumAcc = 0
for bk in backList:
os.environ["KERAS_BACKEND"] = bk
kerasBKED = os.environ["KERAS_BACKEND"]
modelName = [m for m in filesList if bk in m][0]
modelAcc = float(modelName.split("_")[1])
print("MODELNAME {0} \t for BACKEND {1} \t with ACCURACY {2}".format(modelName, kerasBKED, modelAcc))
model = load_model(os.path.join(saveDir, modelName))
prediction += model.predict(x_test2, batch_size=batch_size, verbose=0) * modelAcc
sumAcc += modelAcc
prediction = prediction / sumAcc
print(prediction)
# output predictions to csv
import csv
with open("/tmp/nfstest/cifar_model/preds.csv", 'w') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerows(prediction)
predlist = []
for i in prediction:
pred = max(enumerate(i), key=lambda x: x[1])[0]
predlist.append([pred, i[pred]])
print(predlist)
# output overall summary to csv
import csv
with open("/tmp/nfstest/cifar_model/pred.csv", 'w') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(predlist)
Das Ergebnis des Versuchs
Beim Lernen haben sich alle drei Frameworks auf fast die gleiche Genauigkeit festgelegt.
| Backend | Accuracy | Loss |
|---|---|---|
| Theano | 0.785 | 0.62 |
| TensorFlow | 0.772 | 0.63 |
| CNTK | 0.771 | 0.67 |
Es ist natürlich, weil wir mit demselben neuronalen Netzwerk lernen.
Wenn es um Argumentation geht, gibt es jedoch einen kleinen Unterschied im Backend. Unten finden Sie eine Liste von 10 Testdaten, die von jedem Backend abgeleitet wurden.
Für die ersten Bilddaten ergibt CNTK 4 49,498%, während Tensorflow und Theano 3 auf 55,225% bzw. 67,820% schließen. Multipliziert man die Inferenz und Genauigkeit jedes Backends und dividiert sie durch die Gesamtsumme der Genauigkeit, so ergibt sich eine Schlussfolgerung von 3 zu 57,855%. Die richtige Antwort für jede Bilddaten wird als Antwort links vom Ensemble aufgeführt.
\frac{0.49498 * 0.771 + 0.55225 * 0.772 + 0.67820 * 0.785}{0.771 + 0.772 + 0.785} \\
= 0.57855
Die zweiten Bilddaten sind 8 für CNTK, Tensorflow und Theano. In den dritten Daten beträgt CNTK jedoch 0 bei 41,421%, Tensorflow 8 bei 72,917% und Theano 1 bei 52,288%.
| data | backends | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | cntk | 0.039% | 0.053% | 2.518% | 11.623% | 49.498% | 6.068% | 4.404% | 2.736% | 0.075% | 0.108% |
| tensorflow | 0.049% | 0.002% | 0.289% | 55.225% | 0.055% | 20.520% | 0.399% | 0.143% | 0.495% | 0.015% | |
| theano | 0.002% | 0.005% | 0.028% | 67.820% | 0.068% | 3.543% | 6.598% | 0.017% | 0.027% | 0.347% | |
| answer:3 | ensemble | 0.039% | 0.026% | 1.218% | 57.855% | 21.318% | 12.945% | 4.898% | 1.244% | 0.257% | 0.202% |
| 2 | cntk | 19.015% | 6.447% | 0.027% | 0.125% | 0.007% | 0.001% | 0.001% | 0.004% | 51.443% | 0.052% |
| tensorflow | 0.000% | 0.019% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 77.173% | 0.000% | |
| theano | 0.045% | 2.147% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 76.233% | 0.030% | |
| answer:8 | ensemble | 8.188% | 3.700% | 0.012% | 0.053% | 0.003% | 0.000% | 0.000% | 0.002% | 88.006% | 0.035% |
| 3 | cntk | 41.421% | 2.234% | 0.902% | 0.223% | 1.573% | 0.006% | 0.062% | 0.070% | 21.528% | 9.104% |
| tensorflow | 1.056% | 3.040% | 0.000% | 0.028% | 0.000% | 0.000% | 0.002% | 0.000% | 72.917% | 0.147% | |
| theano | 0.356% | 52.288% | 0.012% | 0.305% | 0.005% | 0.000% | 0.001% | 0.001% | 23.977% | 1.508% | |
| answer:8 | ensemble | 18.402% | 24.729% | 0.393% | 0.239% | 0.678% | 0.003% | 0.028% | 0.031% | 50.876% | 4.622% |
| 4 | cntk | 44.158% | 6.019% | 1.613% | 4.033% | 1.339% | 0.091% | 0.133% | 0.150% | 11.250% | 8.334% |
| tensorflow | 68.420% | 0.740% | 0.175% | 0.296% | 0.010% | 0.004% | 0.029% | 0.006% | 6.932% | 0.580% | |
| theano | 37.302% | 2.057% | 0.594% | 2.029% | 0.348% | 0.086% | 0.043% | 0.029% | 33.511% | 2.455% | |
| answer:0 | ensemble | 64.391% | 3.788% | 1.023% | 2.731% | 0.729% | 0.078% | 0.088% | 0.079% | 22.208% | 4.884% |
| 5 | cntk | 0.005% | 0.001% | 27.413% | 1.284% | 8.657% | 0.023% | 39.720% | 0.001% | 0.017% | 0.001% |
| tensorflow | 0.000% | 0.000% | 0.020% | 0.884% | 71.491% | 0.001% | 4.796% | 0.000% | 0.000% | 0.000% | |
| theano | 0.000% | 0.000% | 2.550% | 0.190% | 1.722% | 0.000% | 73.993% | 0.000% | 0.000% | 0.000% | |
| answer:6 | ensemble | 0.002% | 0.000% | 12.881% | 1.013% | 35.172% | 0.011% | 50.913% | 0.000% | 0.007% | 0.000% |
| 6 | cntk | 0.001% | 0.000% | 3.774% | 23.424% | 8.258% | 0.708% | 40.913% | 0.036% | 0.001% | 0.005% |
| tensorflow | 0.002% | 0.000% | 0.401% | 41.210% | 1.115% | 4.864% | 29.589% | 0.006% | 0.004% | 0.001% | |
| theano | 0.000% | 0.000% | 0.009% | 0.263% | 0.005% | 0.072% | 78.107% | 0.000% | 0.000% | 0.000% | |
| answer:6 | ensemble | 0.001% | 0.000% | 1.797% | 27.881% | 4.029% | 2.425% | 63.844% | 0.018% | 0.002% | 0.003% |
| 7 | cntk | 3.350% | 0.113% | 14.258% | 12.193% | 0.190% | 4.802% | 0.295% | 41.802% | 0.021% | 0.097% |
| tensorflow | 0.048% | 41.460% | 0.462% | 9.073% | 0.000% | 0.737% | 0.079% | 0.602% | 0.044% | 24.686% | |
| theano | 0.008% | 49.193% | 0.053% | 2.381% | 0.001% | 0.065% | 0.183% | 0.015% | 0.024% | 26.531% | |
| answer:1 | ensemble | 1.463% | 38.994% | 6.347% | 10.159% | 0.082% | 2.408% | 0.240% | 18.224% | 0.038% | 22.045% |
| 8 | cntk | 0.014% | 0.001% | 14.742% | 5.123% | 42.021% | 0.048% | 15.141% | 0.020% | 0.008% | 0.004% |
| tensorflow | 0.108% | 0.000% | 9.300% | 6.686% | 31.076% | 0.310% | 29.625% | 0.072% | 0.008% | 0.007% | |
| theano | 0.023% | 0.000% | 33.777% | 0.185% | 1.431% | 0.096% | 42.927% | 0.013% | 0.002% | 0.000% | |
| answer:6 | ensemble | 0.062% | 0.000% | 24.840% | 5.153% | 32.018% | 0.195% | 37.674% | 0.046% | 0.007% | 0.005% |
| 9 | cntk | 0.005% | 0.000% | 4.104% | 43.597% | 17.353% | 5.953% | 5.485% | 0.624% | 0.000% | 0.001% |
| tensorflow | 0.000% | 0.000% | 0.067% | 70.856% | 2.242% | 3.932% | 0.091% | 0.004% | 0.000% | 0.000% | |
| theano | 0.000% | 0.000% | 0.001% | 78.418% | 0.011% | 0.021% | 0.002% | 0.003% | 0.000% | 0.000% | |
| answer:3 | ensemble | 0.002% | 0.000% | 1.792% | 82.860% | 8.423% | 4.256% | 2.396% | 0.271% | 0.000% | 0.000% |
| 10 | cntk | 8.810% | 7.715% | 8.225% | 13.706% | 6.575% | 3.413% | 8.631% | 4.522% | 5.751% | 9.773% |
| tensorflow | 0.482% | 68.974% | 0.012% | 0.014% | 0.001% | 0.001% | 0.213% | 0.000% | 4.088% | 3.405% | |
| theano | 0.480% | 48.363% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 0.000% | 3.134% | 26.477% | |
| answer:1 | ensemble | 4.199% | 53.724% | 3.539% | 5.895% | 2.825% | 1.467% | 3.799% | 1.943% | 5.574% | 17.036% |
Interessant ist, dass das Ensemble auch dann korrekt ist, wenn die einzelnen Backends falsch sind. In Bild 3 ziehen CNTK, Tensorflow und Theano beispielsweise getrennte Schlussfolgerungen, aber Tensorflow leitet 8 mit der höchsten Wahrscheinlichkeit ab, sodass das Ensemble ebenfalls 8 ist.
Zusammenfassung
In der Lernphase waren beide Backends genauso genau. Wenn Sie jedoch versuchen zu schließen, kann jedes unterschiedliche Ergebnisse liefern. Ein weiteres Ensemble scheint die richtige Antwort mit höherer Genauigkeit zu geben, als mit einem Backend zu schließen.
Es ist uns gelungen, parallel mit Kubernetes zu lernen. Kubernetes Job führt das angegebene Programm im Cluster aus, was sehr praktisch ist. Kubernetes hat auch einen Cron-Job, der Jobs zeitgesteuert ausführen zu können scheint. Wenn ich eine Deep-Learning-Studie plane, finde ich es nützlich, sie mit Cron Job von Kubernetes zu automatisieren. Daher werde ich beim nächsten Mal die automatische Ausführung des Deep-Learning-Lernens durch Kubernetes Cron Job überprüfen.
Recommended Posts