[PYTHON] [Übersetzung] scikit-learn 0.18 Einführung in maschinelles Lernen durch Tutorial scikit-learn
google übersetzte http://scikit-learn.org/stable/tutorial/basic/tutorial.html. scikit-learn 0.18 Tutorial Inhaltsverzeichnis
Abschnitt Inhalt
In diesem Abschnitt werden die beim Scikit-Lernen verwendeten Begriffe für maschinelles Lernen vorgestellt und Beispiele für einfaches Lernen gegeben.
Maschinelles Lernen: Problemstellung
Im Allgemeinen berücksichtigt das Lernproblem einen Satz von n Datenproben und versucht, die Eigenschaften unbekannter Daten vorherzusagen. Wenn jede Stichprobe größer als eine einzelne Zahl ist oder wenn es sich um ein mehrdimensionales Element handelt (auch als multivariate bezeichnet), wird von mehreren Attributen oder Merkmalen gesprochen.
Lernprobleme können in mehrere Kategorien unterteilt werden:
- In Teached Learning werden die Attribute, die Sie vorhersagen möchten, zu den Trainingsdaten hinzugefügt (Klicken Sie hier. nazoking @ github / items / 267f2371757516f8c168 # 1-% E6% 95% 99% E5% B8% AB% E4% BB% 98% E3% 81% 8D% E5% AD% A6% E7% BF% 92) und Scikit -Lernen Besuchen Sie die Seite für betreutes Lernen. Dieses Problem kann eines der folgenden sein:
- Klassifizierung: Stichproben gehören zu mehr als einer Klasse und wie die Klasse unbeschrifteter Daten aus bereits beschrifteten Daten vorhergesagt werden kann Ich will lernen. Ein Beispiel für ein Klassifizierungsproblem ist die handschriftliche Nummernerkennung, deren Zweck darin besteht, jeden Eingabevektor einer endlichen Anzahl diskreter Kategorien zuzuordnen. Eine andere Möglichkeit, sich eine Klassifizierung vorzustellen, besteht darin, eine begrenzte Anzahl von Kategorien zu haben und zu versuchen, jede der n Stichproben, die mit der richtigen Kategorie oder Klasse versehen sind, eigenständig (nicht kontinuierlich) zu kennzeichnen. ) Kontinuierliches Lernen mit Lehrern. -Regression (https://en.wikipedia.org/wiki/Regression_analysis): Wenn die gewünschte Ausgabe aus einer oder mehreren kontinuierlichen Variablen besteht, wird die Aufgabe als Regression bezeichnet. Ein Beispiel für ein Regressionsproblem ist die Vorhersage der Lachslänge als Funktion von Alter und Gewicht.
- In Unüberwachtes Lernen sind die Trainingsdaten ein Satz von Eingabevektoren x ohne entsprechenden Zielwert. Ziel solcher Probleme ist es, eine Gruppe ähnlicher Beispiele in den Daten zu finden, die als Clustering bezeichnet werden (https://en.wikipedia.org/wiki/Cluster_analysis), oder die Dichte zu schätzen (https: //). Gehen Sie zur unbeaufsichtigten Lernseite von Scikit-Learn, um die Verteilung der Daten im Eingabebereich (en.wikipedia.org/wiki/Density_estimation) oder zum Zweck der hochdimensionalen Visualisierung zu bestimmen. Klicken Sie hier (http://qiita.com/nazoking@github/items/267f2371757516f8c168#2-%E6%95%99%E5%B8%AB%E3%81%AA%E3%81%97] % E5% AD% A6% E7% BF% 92) Bitte.
** Trainingsset und Testset ** Der Zweck des maschinellen Lernens besteht darin, einige Eigenschaften eines Datensatzes zu lernen und sie auf neue Daten anzuwenden. Eine übliche Methode zur Bewertung eines Algorithmus beim maschinellen Lernen besteht darin, die vorliegenden Daten in zwei Sätze aufzuteilen. Einer wird als ** Trainingssatz ** zum Lernen von Dateneigenschaften und der andere als ** Testsatz ** zum Testen der Eigenschaften bezeichnet.
Beispieldatensatz laden
scikit-learn enthält Iris und Ziffern zur Klassifizierung. -Basierter + Erkennung + von + handgeschriebenen + Ziffern) Datensatz, Boston Home Price Datensatz für Regression usw. Kommt mit mehreren Standarddatensätzen. Im Folgenden wird der Python-Interpreter über die Shell gestartet und die Datensätze "Iris" und "Ziffern" geladen. In unserer Notation steht "$" für eine Shell-Eingabeaufforderung und "> >>" für eine Python-Interpreter-Eingabeaufforderung.
$ python
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
>>> digits = datasets.load_digits()
Ein Dataset ist ein wörterbuchähnliches Objekt, das alle Daten und einige Metadaten zu diesen Daten enthält. Diese Daten werden im .data-Member gespeichert. Dies ist ein Array von "n_samples, n_features". Bei einem Lehrer werden eine oder mehrere Antwortvariablen im Element ".target" gespeichert. Weitere Informationen zu verschiedenen Datensätzen finden Sie im Abschnitt "Dediziert" (http://scikit-learn.org/0.18/datasets/index.html#datasets).
Für das Ziffern-Dataset greift digits.data beispielsweise auf die Funktionen zu, mit denen die numerischen Stichproben klassifiziert werden können.
>>> print(digits.data)
[[ 0. 0. 5. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 10. 0. 0.]
[ 0. 0. 0. ..., 16. 9. 0.]
...,
[ 0. 0. 1. ..., 6. 0. 0.]
[ 0. 0. 2. ..., 12. 0. 0.]
[ 0. 0. 10. ..., 12. 1. 0.]]
digits.target gibt den Wahrheitswert zurück, auf dem das Digits-Dataset basiert. Dies ist die Zahl, die dem Bild jeder Zahl entspricht, die Sie lernen möchten.
>>> digits.target
array([0, 1, 2, ..., 8, 9, 8])
** Datenarrayform ** Die Daten sind immer ein zweidimensionales Array, Form `(n_samples, n_features), auch wenn die Form der Originaldaten unterschiedlich ist. Bei Zahlen ist jedes Originalmuster ein Formbild (8,8) und kann wie folgt aufgerufen werden:
>>> digits.images[0]
array([[ 0., 0., 5., 13., 9., 1., 0., 0.],
[ 0., 0., 13., 15., 10., 15., 5., 0.],
[ 0., 3., 15., 2., 0., 11., 8., 0.],
[ 0., 4., 12., 0., 0., 8., 8., 0.],
[ 0., 5., 8., 0., 0., 9., 8., 0.],
[ 0., 4., 11., 0., 1., 12., 7., 0.],
[ 0., 2., 14., 5., 10., 12., 0., 0.],
[ 0., 0., 6., 13., 10., 0., 0., 0.]])
Dieses einfache Beispiel eines Datensatzes ist Es zeigt, wie Sie mit dem ursprünglichen Problem beginnen und die Daten, die Sie mit scicit-learn verbrauchen, formen können.
** Laden aus einem externen Datensatz **
Informationen zum Laden aus einem externen Dataset finden Sie unter Laden eines externen Datasets (http://scikit-learn.org/0.18/datasets/index.html#external-datasets).
Lernen und Vorhersagen
Bei Ziffern-Datensätzen besteht die Aufgabe darin, vorherzusagen, welche Zahlen ein bestimmtes Bild darstellen wird. Der Schätzer (https://en.wikipedia.org/wiki/Estimator) erhält eine Stichprobe von 10 möglichen Klassen (Zahlen von Null bis 9), damit die Klasse, zu der die unbekannte Stichprobe gehört, vorhergesagt werden kann. Kann gemacht werden. Beim Scikit-Lernen ist der Schätzer für die Klassifizierung ein Python-Objekt, das die Methoden "fit (X, y)" und "vorhersagen (T)" implementiert. Ein Beispielschätzer ist die Klasse "sklearn.svm.SVC", die die Unterstützung von Vektorklassifizierungen implementiert. Der Schätzerkonstruktor verwendet Modellparameter als Argumente, betrachtet den Schätzer jedoch vorerst als Black Box:
>>> from sklearn import svm
>>> clf = svm.SVC(gamma=0.001, C=100.)
** Auswahl der Modellparameter ** Stellen Sie in diesem Beispiel den Wert von
gammamanuell ein. Grid Search und Cross Validation usw. Mit den Tools in können Sie automatisch die entsprechenden Werte für Ihre Parameter finden.
Ich habe die Schätzerinstanz "clf" genannt, weil sie ein Klassifikator ist. Sie müssen das Modell "fit" machen. Das heißt, Sie müssen aus dem Modell lernen. Dies erfolgt durch Übergeben des Trainingssatzes an die "Fit" -Methode. Verwenden Sie als Trainingssatz alle Bilder in Ihrem Datensatz mit Ausnahme des letzten. Wählen Sie diesen Trainingssatz mit der Python-Syntax [: -1] aus. Dadurch wird ein neues Array generiert, das alles außer dem letzten Eintrag in "digits.data" enthält.
>>> clf.fit(digits.data[:-1], digits.target[:-1])
SVC(C=100.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=0.001, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
Sie können jetzt neue Werte vorhersagen. Welche Zahl ist das letzte Bild im Ziffern-Datensatz, das Sie nicht zum Trainieren des Klassifikators verwendet haben?
>>> clf.predict(digits.data[-1:])
array([8])
Die entsprechenden Bilder sind:
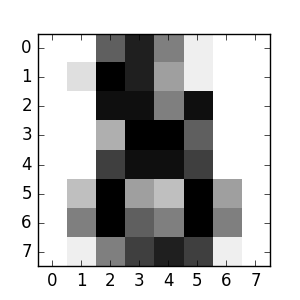
Wie Sie sehen, ist dies eine schwierige Aufgabe. Die Bildauflösung ist niedrig. Stimmen Sie dem Klassifikator zu? Ein vollständiges Beispiel für dieses Klassifizierungsproblem ist als Beispiel verfügbar, das Sie ausführen und lernen können. Erkennen handgeschriebener Zahlen
Modellpersistenz
Es ist möglich, Scicit-Modelle mit dem in Python integrierten Persistenzmodul pickle zu speichern:
>>> from sklearn import svm
>>> from sklearn import datasets
>>> clf = svm.SVC()
>>> iris = datasets.load_iris()
>>> X, y = iris.data, iris.target
>>> clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> import pickle
>>> s = pickle.dumps(clf)
>>> clf2 = pickle.loads(s)
>>> clf2.predict(X[0:1])
array([0])
>>> y[0]
0
In bestimmten Fällen von Scikit ist es möglicherweise besser, den Ersatz für joblib pickle (joblib.dump und joblib.load) zu verwenden. Es ist effizienter für große Datenmengen, kann jedoch nur auf der Festplatte gespeichert werden.
>>> from sklearn.externals import joblib
>>> joblib.dump(clf, 'filename.pkl')
Sie können das eingelegte Modell später laden (möglicherweise in einem anderen Python-Prozess):
>>> clf = joblib.load('filename.pkl')
Hinweis Die Funktionen
joblib.dumpundjoblib.loadakzeptieren auch ein dateiähnliches Objekt anstelle eines Dateinamens. Weitere Informationen zur Datenpersistenz in Joblib finden Sie hier (https://pythonhosted.org/joblib/persistence.html).
Beachten Sie, dass Pickle einige Sicherheits- und Wartbarkeitsprobleme aufweist. Weitere Informationen zur Modellpersistenz mit scikit-learn finden Sie unter Modellpersistenz.
Bedingungen
Der Scikit-Learn-Schätzer folgt bestimmten Regeln, um sein Verhalten prädiktiver zu gestalten.
Typ gegossen
Sofern nicht anders angegeben, wird die Eingabe in "float64" umgewandelt:
>>> import numpy as np
>>> from sklearn import random_projection
>>> rng = np.random.RandomState(0)
>>> X = rng.rand(10, 2000)
>>> X = np.array(X, dtype='float32')
>>> X.dtype
dtype('float32')
>>> transformer = random_projection.GaussianRandomProjection()
>>> X_new = transformer.fit_transform(X)
>>> X_new.dtype
dtype('float64')
In diesem Beispiel ist "X" "float32" und wird von "fit_transform (X)" in "float64" umgewandelt. Das Regressionsziel wird auf "float64" gesetzt und das Klassifizierungsziel wird beibehalten.
>>> from sklearn import datasets
>>> from sklearn.svm import SVC
>>> iris = datasets.load_iris()
>>> clf = SVC()
>>> clf.fit(iris.data, iris.target)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> list(clf.predict(iris.data[:3]))
[0, 0, 0]
>>> clf.fit(iris.data, iris.target_names[iris.target])
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> list(clf.predict(iris.data[:3]))
['setosa', 'setosa', 'setosa']
Hier gibt die erste "Vorhersage ()" ein ganzzahliges Array zurück, da "iris.target" (ganzzahliges Array) in "fit" verwendet wurde. Das zweite pred () gibt ein String-Array zurück. Weil "iris.target_names" zum Anpassen war.
Parameteraktualisierungen und Aktualisierungen
Die Hyperparameter des Schätzers sind die Methode sklearn.pipeline.Pipeline.set_params. Kann nach dem Erstellen mit aktualisiert werden. Durch mehrmaliges Aufrufen von "fit ()" wird überschrieben, was durch das vorherige "fit ()" gelernt wurde:
>>> from sklearn.svm import SVC
>>> rng = np.random.RandomState(0)
>>> X = rng.rand(100, 10)
>>> y = rng.binomial(1, 0.5, 100)
>>> X_test = rng.rand(5, 10)
>>> clf = SVC()
>>> clf.set_params(kernel='linear').fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='linear',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> clf.predict(X_test)
array([1, 0, 1, 1, 0])
>>> clf.set_params(kernel='rbf').fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> clf.predict(X_test)
array([0, 0, 0, 1, 0])
Hier wird der Standardkernel "rbf" zuerst linear modifiziert, nachdem der Schätzer über "SVC ()" erstellt wurde, und dann zurück zu "rbf", um den Schätzer neu zu konfigurieren und eine zweite Vorhersage zu treffen. Machen.
Mehrklassen- und Mehretikettenbeschlag
Bei Verwendung des Multiclass Classifier (http://scikit-learn.org/0.18/modules/classes.html#module-sklearn.multiclass) werden die durchgeführten Trainings- und Vorhersageaufgaben im Format der Zieldaten ausgeführt. Hängt davon ab.
>>> from sklearn.svm import SVC
>>> from sklearn.multiclass import OneVsRestClassifier
>>> from sklearn.preprocessing import LabelBinarizer
>>> X = [[1, 2], [2, 4], [4, 5], [3, 2], [3, 1]]
>>> y = [0, 0, 1, 1, 2]
>>> classif = OneVsRestClassifier(estimator=SVC(random_state=0))
>>> classif.fit(X, y).predict(X)
array([0, 0, 1, 1, 2])
In dem obigen Fall passt der Klassifizierer in ein mehrfach beschriftetes eindimensionales Array, so dass die "Predict ()" - Methode die entsprechende Mehrklassenvorhersage liefert. Es ist auch möglich, in ein zweidimensionales Array von binären Label-Indikatoren zu passen:
>>> y = LabelBinarizer().fit_transform(y)
>>> classif.fit(X, y).predict(X)
array([[1, 0, 0],
[1, 0, 0],
[0, 1, 0],
[0, 0, 0],
[0, 0, 0]])
Hier verwendet der Klassifizierer LabelBinarizer, um die beiden Dimensionen von "y" zu erstellen. Fit () zur binären Etikettendarstellung. In diesem Fall gibt "pred ()" ein zweidimensionales Array zurück, das die entsprechende Vorhersage mit mehreren Markierungen darstellt.
Die 4. und 5. Instanz geben alle 0 zurück, was darauf hinweist, dass keine der 3 Bezeichnungen "passt". Bei der Ausgabe mit mehreren Labels ist es auch möglich, einer Instanz mehrere Labels zuzuweisen.
>> from sklearn.preprocessing import MultiLabelBinarizer
>> y = [[0, 1], [0, 2], [1, 3], [0, 2, 3], [2, 4]]
>> y = preprocessing.MultiLabelBinarizer().fit_transform(y)
>> classif.fit(X, y).predict(X)
array([[1, 1, 0, 0, 0],
[1, 0, 1, 0, 0],
[0, 1, 0, 1, 0],
[1, 0, 1, 1, 0],
[0, 0, 1, 0, 1]])
In diesem Fall passt der Klassifizierer in eine Instanz, der jeweils mehrere Beschriftungen zugewiesen sind. MultiLabelBinarizer wird verwendet, um ein mehrfach gekennzeichnetes zweidimensionales Array zu entwickeln. Ich werde. Infolgedessen gibt "pred ()" ein zweidimensionales Array mit mehreren prädiktiven Beschriftungen pro Instanz zurück.
© 2010 - 2016, Entwickler von Scikit-Learn (BSD-Lizenz).
Recommended Posts