[PYTHON] Ich möchte japanische Bestandsdaten erfassen und auflisten, ohne sie zu kratzen
Ich möchte mit großen Datenmengen umgehen!
Die Analyse der Aktienkurse sieht interessant aus!
Als ich nachgeschlagen habe, habe ich festgestellt, dass Aktien aus Übersee mit dem DataReader von Pandas leicht als Daten abgerufen werden können. (Zum Beispiel Google Finanzen und FRED) Japanische Aktienkurse können nicht als unerwartete Daten gefunden werden.
Sie müssen es nur von Yahoo! Finance abrufen! Es gibt viele Artikel, Yahoo! Finance [Verbietet das Scraping](https://www.yahoo-help.jp/app/answers/detail/p/546/a_id/93575/~/yahoo%21%E3%83%95%E3% 82% A1% E3% 82% A4% E3% 83% 8A% E3% 83% B3% E3% 82% B9% E6% 8E% B2% E8% BC% 89% E6% 83% 85% E5% A0% B1% E3% 81% AE% E8% 87% AA% E5% 8B% 95% E5% 8F% 96% E5% BE% 97% EF% BC% 88% E3% 82% B9% E3% 82% AF% E3% 83% AC% E3% 82% A4% E3% 83% 94% E3% 83% B3% E3% 82% B0% EF% BC% 89% E3% 81% AF% E7% A6% 81% E6% AD% A2% E3% 81% 97% E3% 81% A6% E3% 81% 84% E3% 81% BE% E3% 81% 99), also kann ich es nicht von hier ziehen.
Sie könnten argumentieren, dass Sie das Modul jsm verwenden können, aber dieses verwendet auch Scraping.
Der Zweck dieses Artikels ist es, ** Daten ohne Scraping abzurufen und in eine einzige Liste zu verwandeln **.

Code für ungeduldige Menschen
Bitte erzähl mir nur die Schlussfolgerung! Ich werde den Code (ich habe mein Bestes gegeben) für die Leute behalten. Bitte korrigieren Sie die Angaben selbst.
Code 1
import os
import pandas as pd
import matplotlib.pyplot as plt
os.chdir("C:\\Users\\Kuma_T\\stock") #Geben Sie den Speicherort der Datei an und stellen Sie die Daten an die erste Stelle
plt.rcParams['figure.figsize'] = [10, 5]
plt.rcParams['xtick.direction'] = 'in'#x-Achsen-Skalierungslinie nach innen('in')Oder nach außen('out')Oder bidirektional('inout')
plt.rcParams['ytick.direction'] = 'in'#Die Skalierungslinie der y-Achse zeigt nach innen('in')Oder nach außen('out')Oder bidirektional('inout')
plt.rcParams['xtick.major.width'] = 1.0 #Linienbreite der x-Achsen-Hauptskalenlinie
plt.rcParams['ytick.major.width'] = 1.0 #Linienbreite der Hauptskalenlinie der y-Achse
plt.rcParams['font.size'] = 12 #Schriftgröße
plt.rcParams['axes.linewidth'] = 1.0 #Achsenlinienbreite Kantenlinienbreite. Gehäusedicke
plt.rcParams['font.family'] = 'Times New Roman' #Zu verwendender Schriftname
Code 2
code = 3672 #Orthoplus
start = 2015
end = 2017
x = []
y = []
for n in range (start, end+1):
file_name = 'stocks_'+str(code)+'-T_1d_%d.csv' %n #Geben Sie den Dateinamen an
data = pd.read_csv(file_name, header=0, encoding='cp932') #Ich kann kein Japanisch lesen, geben Sie also die Codierung an
a =list(pd.to_datetime(data.iloc[:,0], format='%Y-%m-%d')) #Wenn Sie es so lesen, wie es ist, kann das Datum nicht erkannt werden. Verwenden Sie daher datetime
x += a[::-1] #Um die Reihenfolge in der Liste umzukehren[::-1]Und zur Liste von x hinzufügen
b = list(data.iloc[:,4])
y += b[::-1]
z = pd.DataFrame(y)#In DataFrame konvertieren
sma75 = pd.DataFrame.rolling(z, window=75,center=False).mean()
sma25 = pd.DataFrame.rolling(z, window=25,center=False).mean()
plt.plot(x, y, color="blue", linewidth=1, linestyle="-")
plt.plot(x, sma25, color="g", linewidth=1, linestyle="-", label="SMA25")
plt.plot(x, sma75, color="r", linewidth=1, linestyle="-", label="SMA75")
plt.title("Alt Plus ("+str(code)+")", fontsize=16, fontname='Times New Roman')
plt.xlabel("Year-Month", fontsize=14, fontname='Times New Roman') #Titel der x-Achse
plt.ylabel("Stock price", fontsize=14, fontname='Times New Roman') #Titel der y-Achse
plt.legend(loc="best")
plt.show()
Datenaufbereitung
Individuelle Aktienkursdaten http://k-db.com/stocks/
Wenn Sie hier zugreifen, können Sie die Daten japanischer Aktien als CSV-Datei abrufen.
Wenn Sie sich Ortho Plus (3672) als Testversion ansehen,
Die CSV-Datei befindet sich hier. Laden Sie sie in einen bestimmten Ordner herunter. Diese Daten haben übrigens ein neues Datum auf der Oberseite. Dieses Mal habe ich die Daten von 2015-2017 heruntergeladen.
Daten lesen
Geben Sie zunächst den heruntergeladenen Ordner an.
Code 1
import os
import pandas as pd
import matplotlib.pyplot as plt
os.chdir("C:\\Users\\Kuma_T\\stock") #Geben Sie den Speicherort der Datei an und stellen Sie die Daten an die erste Stelle
Laden Sie als Nächstes die gespeicherte CSV-Datei.

stocks_3672-T_1d_2015 stocks_3672-T_1d_2016 stocks_3672-T_1d_2017 Weil wir eine Datei namens vorbereitet haben Markencode 3672 Laden Sie ab 2015 Das Ende der Lektüre ist 2017.
Als nächstes machen Sie eine leere Liste.
Code 2
code = 3672 #Orthoplus
start = 2015
end = 2017
x = []
y = []
Ich werde in die Schleifenfunktion schreiben.
Geben Sie den zu lesenden Dateinamen an und lesen Sie ihn mit Pandas read_csv (die Codierung wird angegeben, da auf Japanisch ein Fehler auftritt). Lesen Sie die Datumsdaten in der ersten Datenspalte als Datum mit iloc [:, 0] und pd.to_datetime und erstellen Sie eine Liste. Wie oben erwähnt, hat die CSV-Datei oben ein neueres Datum. Fügen Sie es daher in umgekehrter Reihenfolge mit dem ältesten Datum oben zur leeren Liste hinzu.
Fügen Sie in ähnlicher Weise den Schlusskurs in der 4. Spalte zur leeren Liste hinzu.
Code 2
for n in range (start, end+1):
file_name = 'stocks_'+str(code)+'-T_1d_%d.csv' %n #Geben Sie den Dateinamen an
data = pd.read_csv(file_name, header=0, encoding='cp932') #Ich kann kein Japanisch lesen, geben Sie also die Codierung an
a =list(pd.to_datetime(data.iloc[:,0], format='%Y-%m-%d')) #Wenn Sie es so lesen, wie es ist, kann das Datum nicht erkannt werden. Verwenden Sie daher datetime
x += a[::-1] #Um die Reihenfolge in der Liste umzukehren[::-1]Und zur Liste von x hinzufügen
b = list(data.iloc[:,4])
y += b[::-1]
Damit konnten wir die angestrebten Aktienkursdaten in einem Listentyp erhalten.
Überprüfen Sie dies durch grafische Darstellung
Wenn Sie diesen Punkt erreicht haben, erstellen Sie ein Diagramm und überprüfen Sie es.
Code 2
plt.plot(x, y, color="blue", linewidth=1, linestyle="-")
plt.show()
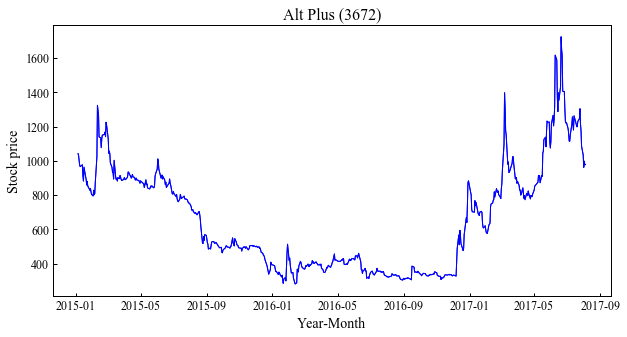
Das Diagramm wird sicher erstellt.
Wenn Sie nicht in umgekehrter Reihenfolge lesen, ist dies eine Einschränkung.

Gleitenden Durchschnitt hinzufügen
Fügen wir als Bonus einen gleitenden Durchschnitt hinzu.
Der gleitende Durchschnitt kann einfach mithilfe von DataFrame.rolling von Pandas berechnet werden. Wie der Name schon sagt, wird DataFrame.rolling im DataFrame-Format verwendet, sodass List konvertiert wird.
Code 2
z = pd.DataFrame(y)#In DataFrame konvertieren
sma75 = pd.DataFrame.rolling(z, window=75,center=False).mean()
sma25 = pd.DataFrame.rolling(z, window=25,center=False).mean()
plt.plot(x, y, color="blue", linewidth=1, linestyle="-")
plt.plot(x, sma25, color="g", linewidth=1, linestyle="-", label="SMA25")
plt.plot(x, sma75, color="r", linewidth=1, linestyle="-", label="SMA75")
Dieses Mal haben wir einen gleitenden 25-Tage-Durchschnitt und einen gleitenden 75-Tage-Durchschnitt hinzugefügt.
Schließlich
** Ich konnte eine Liste japanischer Aktien erhalten ** ohne zu kratzen. Diesmal habe ich versucht, Ortho Plus (3672) zu verwenden, aber bitte versuchen Sie es mit einzelnen Marken. Nächstes Mal möchte ich anhand dieser Daten analysieren.
Last but not least bin ich noch ein Anfänger in Aktien und Programmierung. Bitte kommentieren Sie, wenn Sie welche haben.
Einführung von Artikeln usw., auf die unten Bezug genommen wird
Schreiben Sie Code für die Aktienkursvorhersage mithilfe von maschinellem Lernen in Python http://www.stockdog.work/entry/2017/02/09/211119
[Python / jsm] Erhalten Sie für jede Ausgabe Aktienkursdaten japanischer Unternehmen https://algorithm.joho.info/programming/python/jsm-get-japan-stock/
Abrufen von Zeitreihendaten zum Aktienkurs (Originalserie) mit dem jsm-Modul von Python, Anhängen des Diagramms für die Ausgabe-Faltlinie an Google Mail und Zustellung per E-Mail http://qiita.com/HirofumiYashima/items/471a2126595d705e58b8
Holen Sie sich japanische Aktieninformationen und zeichnen Sie Kerzen-Charts mit Python-Pandas http://sinhrks.hatenablog.com/entry/2015/02/04/002258
Prognostizieren Sie die Aktienkurse durch Big-Data-Analyse aus früheren Daten http://qiita.com/ynakayama/items/420ebe206e34f9941e51
- Aktienkurse mit Pandas kratzen ~ Versuchen Sie, ein S ◯ I-Chart im Wertpapierstil zu zeichnen ~ http://www.stockdog.work/entry/2016/08/26/170152
Obwohl es sich nicht um eine einzelne Aktie handelt, habe ich einen neuen Artikel über Aktieninvestitionen geschrieben.
"Es gibt eine Gewinnmethode für dieses Spiel (finanzierte Investition) - Shareholding Association Game-" https://qiita.com/Kuma_T/items/667e1b0178a889cc42f7
Recommended Posts