[PYTHON] Zusammenfassung der Scikit-Learn-Datenquellen, die beim Schreiben von Analyseartikeln verwendet werden können
Einführung
Dieser Artikel verwendet Python 2.7, Numpy 1.11, Scipy 0.17, Scikit-Learn 0.18 und Matplotlib 1.5. Es wurde bestätigt, dass es an einem Jupiter-Notebook funktioniert. Basierend auf Dienstprogrammen zum Laden von Daten haben wir die Datenquellen zusammengefasst, die beim Schreiben eines Artikels schnell vorbereitet werden können. Einige Spezifikationen haben sich zwischen Version 0.18 und früher geändert. Sie wird bei jeder Verwendung der Probendaten nacheinander aktualisiert.
Inhaltsverzeichnis
-
loading dataset
- iris
- boston
- diabetes
- digits
- linnerud
-
Generating dataset
- blobs
- make_classification
-
Referenz
-
Loading dataset Verwenden Sie Sklearns Lorder, um vorbereitete Beispieldaten zu laden. Dienstprogramme zum Laden von Daten führt 5 Daten als Spielzeugdatensätze ein. Diese können offline erfasst werden, da die Datenmenge nicht groß ist (ca. 100 Stichproben). [Dieser Artikel](http://pythondatascience.plavox.info/scikit-learn/scikit-learn%E3%81%AB%E4%BB%98%E5%B1%9E%E3%81%97%E3% 81% A6% E3% 81% 84% E3% 82% 8B% E3% 83% 87% E3% 83% BC% E3% 82% BF% E3% 82% BB% E3% 83% 83% E3% 83% Da es in 88 /) ausführlich zusammengefasst wurde, werde ich die Daten nur kurz vorstellen.
1.1. iris Holen Sie sich grundlegende Irisdaten mit Bündel Objekt. (Sie können es durch Kombinieren von Daten und Label erhalten, indem Sie load_iris (return_X_y = True) aus Version 0.18 festlegen.) Wird für Klassifizierungsprobleme verwendet.
load_iris.py
from sklearn.datasets import load_iris
data = load_iris()
print data.target_names
print data.target[:10]
print data.data[:10]
Bei der Ausführung werden drei Beschriftungsnamen, Datenbeschriftungen und vierdimensionale Parameter erhalten. Die Größe beträgt 50 Proben für jedes Etikett. Ausführungsbeispiel:
['setosa' 'versicolor' 'virginica']
[0 0 0 0 0 0 0 0 0 0]
[[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]
[ 5.4 3.9 1.7 0.4]
[ 4.6 3.4 1.4 0.3]
[ 5. 3.4 1.5 0.2]
[ 4.4 2.9 1.4 0.2]
[ 4.9 3.1 1.5 0.1]]
1.2. boston Dies ist ein Datensatz mit 13 Arten von Informationen am Stadtrand von Boston und den Immobilienpreisen nach Regionen. Es kann für Regressionsprobleme verwendet werden.
| Anzahl von Beispielen | Anzahl der Dimensionen | Charakteristisch | Etikette |
|---|---|---|---|
| 506 | 13 | real x>0 | real 5<y<50 |
Beschreibung der Parameter (12)
- KRIMINALITÄT: Anzahl der Verbrechen pro Kopf
- Prozentsatz der Wohngebiete über 25.000 Quadratfuß
- INDUS: Prozentsatz des Nichteinzelhandels
- CHAS: Dummy-Variable von Charles River (1: Rund um den Fluss, 0: Andere)
- NOX: NOx-Konzentration
- RM: Durchschnittliche Anzahl der Zimmer in der Residenz
- ALTER: Prozentsatz der vor 1940 errichteten Immobilien
- DIS: Entfernung von 5 Bostoner Beschäftigungseinrichtungen (gewichtet)
- RAD: Einfacher Zugang zur Ringstraße
- STEUER: Gesamtsteuersatz für Immobilien pro 10.000 USD
- PTRATIO: Kinder-Lehrer-Verhältnis nach Stadt
- B: Das Verhältnis der Schwarzen (Bk) in jeder Stadt wird durch die folgende Formel ausgedrückt. 1000 (Bk - 0,63) ^ 2
- LSTAT: Prozentsatz der Bevölkerung, die schlecht bezahlte Berufe ausübt (%)
Die folgende Abbildung zeigt die Kriminalitätsrate pro künstlicher Person und den Immobilienpreis nach Regionen in den Vororten von Boston.

1.3. diabetes Testwerte von 442 Diabetikern und Fortschreiten der Krankheit ein Jahr später. Wird für Regressionsprobleme verwendet.
| Anzahl von Beispielen | Anzahl der Dimensionen | Charakteristisch | Etikette |
|---|---|---|---|
| 442 | 10 | real -2>x>2 | int 25<y<346 |
1.4. digits Eine handgeschriebene 10-stellige Zahl von 0 bis 9, zerlegt in 64 (8 x 8) Pixel. Wird zur Bilderkennung verwendet.
| Anzahl von Beispielen | Anzahl der Dimensionen | Charakteristisch | Etikette |
|---|---|---|---|
| 1.797 | 64 | int 0<x<16 | int 0<y<9 |
1.5. Linnerud Beziehung zwischen 3 physiologischen Merkmalen und 3 sportlichen Leistungen, gemessen in einem Fitnessclub für 20 erwachsene Männer, erstellt von Dr. A. C. Linnerud von der North Carolina State University. Wird für multivariate Analysen verwendet.
| Anzahl von Beispielen | Anzahl der Dimensionen |
|---|---|
| 20 | Erklärende Variable:3,Objektive Variable:3 |
Inhalt erklärender Variablen
Chins Situps Jumps
0 5 162 60
1 2 110 60
2 12 101 101
3 12 105 37
4 13 155 58
Inhalt der Zielvariablen
Weight Waist Pulse
0 191 36 50
1 189 37 52
2 193 38 58
3 162 35 62
- Generating dataset Verwenden Sie den Probengenerator, um jedes Mal charakteristische Daten zu generieren. Sie können beliebig viele Daten mit bestimmten Merkmalen generieren.
2.1. blobs Erzeugt Daten, die wie eine zentrale Fleckenverteilung aussehen. Sie können die Anzahl der Abtastwerte und die Anzahl der Cluster in n_samples bzw. in den Zentren auswählen. Sie können die Anzahl der Beschriftungen mit n_features festlegen.
make_blobs.py
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=10, centers=3, n_features=2, random_state=0)
print(X.shape)
Ausführungsbeispiel:
array([[ 1.12031365, 5.75806083],
[ 1.7373078 , 4.42546234],
[ 2.36833522, 0.04356792],
[ 0.87305123, 4.71438583],
[-0.66246781, 2.17571724],
[ 0.74285061, 1.46351659],
[-4.07989383, 3.57150086],
[ 3.54934659, 0.6925054 ],
[ 2.49913075, 1.23133799],
[ 1.9263585 , 4.15243012]])
Beispiel generiert 3 Datensätze in 2 Klassen tun.
(Vor Version 0.18 wird in train_test_split eine Fehlermeldung angezeigt.)
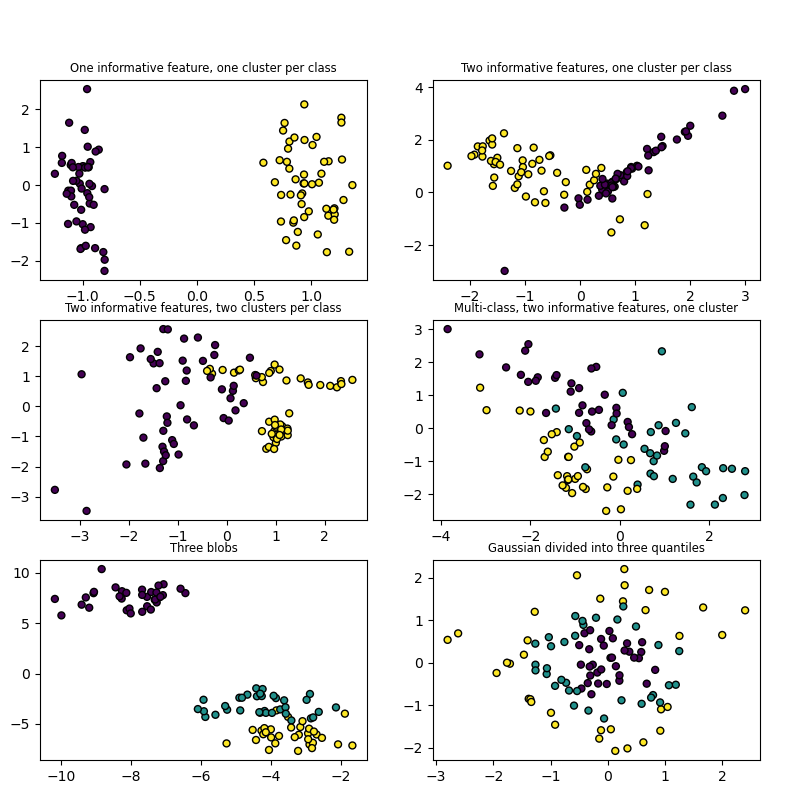
2.2. make_classification Wenn Sie sich mit Klassifizierungsproblemen befassen möchten, können Sie mehrdimensionale Daten und jedes Etikett generieren. Es gab eine ausführliche Erklärung zu dieser Site. Grundsätzlich ist es durch Anpassen von n_features, n_classes und n_informative möglich, Daten zu generieren, die Korrelationen enthalten.
| Parameter name | Description | Default |
|---|---|---|
| n_features | Anzahl der Dimensionen der zu generierenden Daten | 20 |
| n_classes | Anzahl der Etiketten | 2 |
| n_informative | Anzahl der im Datengenerierungsprozess verwendeten Normalverteilungen | 2 |
| n_cluster_per_class | Anzahl der Normalverteilungen in jedem Etikett | 2 |
make_classification.py
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
%matplotlib inline
X1, Y1 = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_informative=2,n_clusters_per_class=2, n_classes=2)
plt.scatter(X1[:, 0], X1[:, 1], marker='o', c=Y1)
Ausführungsbeispiel:
(Die Darstellung ändert sich von Lauf zu Lauf, da sie zufällig aus informativen Funktionen und Redundunt-Fetures ausgewählt wird.)

Scikit-Lernbeispiel
Es gab ein leicht verständliches Beispiel. Bitte beachten Sie auch.
Referenz
Data loading utilities blobs make_classification Beispieldatengenerierung mit scikit-learn
Recommended Posts