[PYTHON] Zusammenfassung der Situationen, in denen Plotly Express verwendet werden kann [Wann können Sie es von matplotlib aus verwenden? ]]
Einführung
Apropos Zeichnen von Grafiken: Matplotlib + Serborn ist das wichtigste. Darüber hinaus ** Das Potenzial ist Plotly Express, mit dem Sie interaktive Grafiken erstellen können. ** ** ** Ich möchte mich auf die Punkte konzentrieren, an denen Plotly Express bequemer ist als Matplotlib + Seaborn.
Ich habe den Eindruck, dass ich nicht viel Angewohnheit habe. ** Diagramme können mit weniger Linien als grafisch dargestellt werden, und diejenigen, die Matplotlib verwendet haben, sollten in der Lage sein, es ohne große Beschwerden einzuführen. ** ** **
Persönliches Denken ** Die Szene, in der Plotly Express nützlich ist ** sieht so aus. ――Ich habe ein Histogramm geschrieben, aber der Saum ist rechts zu breit, daher bin ich mir nicht sicher ... Aber es ist umständlich, ein Diagramm zu schreiben, bei dem nur der rechte Saum vergrößert ist. ――Ich möchte ein gestapeltes Balkendiagramm erstellen, aber die wenigen sind zerstört. Erstens sind die mit Seaborn angehäuften Grafiken problematisch. ――Ich möchte die Daten überprüfen, die im Streudiagramm nicht ausgerichtet sind, aber es ist schwierig herauszufinden, welche Daten nicht ausgerichtet sind. ――Ich habe ein Paarplot erstellt, aber es gibt zu viele erklärende Variablen ... Gibt es eine Möglichkeit zu überprüfen, welche erklärenden Variablen auf einmal wichtig sind? ――Ich möchte die Zeit und den Wert wissen, wenn ein Fehler in den Zeitreihendaten auftritt.
Was ist in diesem Artikel zu tun?
Lassen Sie uns ein praktisches Diagramm im Vergleich zu Seegeborenen zeichnen. Wir werden Titandaten, jährliche Passagierzählungsdaten und Daten zur Weinqualität aus dem Python-Datensatz als analytische Daten verwenden.
** Mit Titandaten --Wasserstoff
- Gestapeltes Balkendiagramm
- Box Whisker Mit Fluggastnummernangaben
- Liniendiagramm Mit Weinqualitätsdaten
- Streudiagramm
- Parallele Koordinaten **
Ich habe auch einen Link zur eigentlichen HTML-Datei für diese Grafiken gepostet. Über den HTML-Link können Sie das Gefühl erleben, sich tatsächlich zu bewegen. Es fühlt sich gut an. Zum Beispiel dieses Diagramm. https://nakanakana12.github.io/plotly/hello_world/histgram.html
Dieser Artikel enthält wahnsinnig detaillierte Informationen zum Zeichnen verschiedener Grafiken. Zusammenfassung der grundlegenden Zeichenmethode von Plotly Express, dem De-facto-Standard der Python-Zeichenbibliothek in der Reiwa-Ära https://qiita.com/hanon/items/d8cbe25aa8f3a9347b0b
Bibliothek importieren
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
from sklearn.datasets import load_wine
Titandaten
python
df = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.csv')
#Alle 10 Jahre wurde eine Spalte mit gerundetem Alter hinzugefügt
df["age10"] = df["age"] // 10 * 10
df["survived_num"] = df["survived"]
df["survived"] = df["survived"].replace(1,"alive").replace(0,"dead")
df["sex_num"] = df["sex"].replace("female",1).replace("male",0)
df = df.reset_index()
df.head()

Histogramm
** Plotly ist praktisch für Distributionen mit einem langen Saum rechts! ** ** **
Zeigt ein Histogramm des Fahrpreises an. Farbcodiert je nachdem, ob sie überlebt haben. Der Fahrpreis ist nicht normal verteilt, aber ** hat einen langen Saum auf der rechten Seite **. In einem solchen Fall macht es matplotlib schwierig, eine kleine Anzahl von Daten zu sehen, was ein ziemliches Problem darstellt.
Mit plotly können Sie einen kleinen Bereich vergrößern, sodass Sie die Situation leicht erfassen können.
In diesem Fall ist die Anzahl der Personen mit hohem Tarif gering, aber die Überlebensrate ist hoch, wenn Sie nur eine Grafik durchgehen.
python
fig = px.histogram(df, x="fare", color="survived",nbins=200, opacity=0.4, marginal="box"
, title="Tarifhistogramm von Survived")
fig.update_layout(barmode='overlay')
fig.show()
#Als HTML speichern
fig.write_html('./histogram.html', auto_open=False)

Klicken Sie hier für die HTML-Datei. Sie können es bewegen. https://nakanakana12.github.io/plotly/hello_world/histgram.html
Gestapeltes Balkendiagramm
** Mit Plotly Express sind gestapelte Balkendiagramme leicht und leicht zu sehen! ** ** **
Dies kann die beste Empfehlung sein.
Das Problem beim Erstellen eines gestapelten Balkendiagramms besteht darin, dass es viele Klassifizierungen gibt. Manchmal weiß ich nicht, wie wenige Dinge es gibt. Mit plotly ist es praktisch, die Nummer durch Bewegen des Cursors überprüfen zu können, auch wenn die Nummer klein ist.
Hier haben wir uns vorgestellt, ob wir nach Alter überlebt haben oder nicht. Außerdem habe ich einen Fall erstellt, in dem das Geschlecht zusammen angezeigt wird, und einen Fall, in dem das Diagramm getrennt ist. Es ist gut sichtbar, dass die Überlebensrate nach den 50er Jahren niedrig ist und dass die Überlebensrate bei Frauen höher ist.
python
#Vorverarbeitung
df_bar = df.groupby(["survived", "age10","sex"],as_index=False).size().reset_index(drop=True)
df_bar.columns = ["survived", "age10","sex","count"]
df_bar.head()

python
fig = px.bar(df_bar, y="age10", x="count", orientation="h",color="survived"
, title="Nach Alter überlebt(Alles zusammen anzeigen)")
fig.show()
 Klicken Sie hier für die HTML-Datei.
https://nakanakana12.github.io/plotly/hello_world/bar.html
Klicken Sie hier für die HTML-Datei.
https://nakanakana12.github.io/plotly/hello_world/bar.html
python
fig = px.bar(df_bar, y="age10", x="count", orientation="h",facet_row="sex",color="survived"
, title="Nach Alter überlebt")
fig.show()

Klicken Sie hier für die HTML-Datei. https://nakanakana12.github.io/plotly/hello_world/bar3.html
Box Whisker
** Einfach zu überprüfende Ausreißer! ** ** **
Im Fall von Box-Whiskern ist es praktisch, die Ausreißer und Konfidenzintervalldaten leicht überprüfen zu können.
Ich persönlich finde es auch praktisch, hover_data als Index anzugeben. Dies macht es einfach, den Ausreißerindex und die Daten in den anderen Spalten sofort zu sehen.
python
fig = px.box(df, x="pclass", y="age", color="survived", hover_data=["index"])
fig.show()
#Als HTML speichern
fig.write_html('./box.html', auto_open=False)

Klicken Sie hier für die HTML-Datei. https://nakanakana12.github.io/plotly/hello_world/box.html
Fluggastdaten
Liniendiagramm
** Kennen Sie leicht die Zeit und den Wert abnormaler Werte! ** ** **
Bei Zeitreihendaten ist das gestrichelte Diagramm ein Standard. Zeichnen wir den monatlichen Übergang von der Anzahl der Passagierdaten.
Sie können das anzuzeigende Diagramm auswählen, indem Sie auf die Legende klicken, oder Sie können den Anzeigebereich mit dem Schieberegler unten auswählen. Sie können auch die x- und y-Achse der Punkte, die Sie interessieren, mit der Maus überprüfen.
Um ehrlich zu sein, profitieren diese Daten nicht, aber sie scheinen nützlich zu sein, wenn es viele Kategorien gibt oder wenn Sie die x-Achse von Ausreißern überprüfen möchten.
python
df = sns.load_dataset("flights")
fig = px.line(df, x="year", y="passengers", color="month", title="Änderungen in der Anzahl der Passagiere")
fig.update_layout(xaxis_range=['1949-01-01', '1961-01-01'], # datetime.Kann durch Datum / Uhrzeit angegeben werden
xaxis_rangeslider_visible=True)
fig.show()
#Als HTML speichern
fig.write_html('./time_series.html', auto_open=False)

Klicken Sie hier für die HTML-Datei. https://nakanakana12.github.io/plotly/hello_world/time_series.html
Daten zur Weinqualität
Datenaufbereitung
python
data_wine = load_wine()
df = pd.DataFrame(data_wine["data"], columns=data_wine["feature_names"])
df["target_ID"] = data_wine["target"]
df["target"] = df["target_ID"].replace(0,"bad").replace(1,"good").replace(2,"great")
df["alcohol_rank"] = np.where(df["alcohol"] < df["alcohol"].mean(),"low", "high")
df["flavanoids_rank"] = np.where(df["flavanoids"] < df["flavanoids"].mean(),"low", "high")
df = df.reset_index()
df.head()

Streudiagramm
** Sie können leicht den Index der Daten finden, die Sie interessieren! ** ** **
Es ist praktisch, einfach überprüfen zu können, welche Daten ein Ausreißer sind, indem Sie mit der Maus auf das Streudiagramm zeigen.
Meine persönliche Empfehlung ist, einen Index für hover_data anzugeben. Wenn Sie dies tun, können Sie den Index der Ausreißerdaten nur durch Zeigen mit der Maus finden und andere Werte leicht überprüfen.
Es ist ziemlich einfach, Dinge wie Seepaar-Pläne zu machen.
python
fig = px.scatter(df, x="alcohol", y="color_intensity", color="target",
marginal_x="box", marginal_y="histogram", trendline="ols",
hover_data=["index"],
title="Beziehung zwischen Alkoholgehalt und Farbintensität von Wein")
fig.show()
#Als HTML speichern
fig.write_html('./scatter.html', auto_open=False)

Klicken Sie hier für die HTML-Datei. https://nakanakana12.github.io/plotly/hello_world/scatter.html
python
fig = px.scatter_matrix(df, dimensions=["alcohol", "flavanoids","color_intensity","hue"],color="target",
hover_data=["index"],
title="Erklärende variable Korrelationsanalyse von Wein")
fig.show()
#Als HTML speichern
fig.write_html('./scatter2.html', auto_open=False)
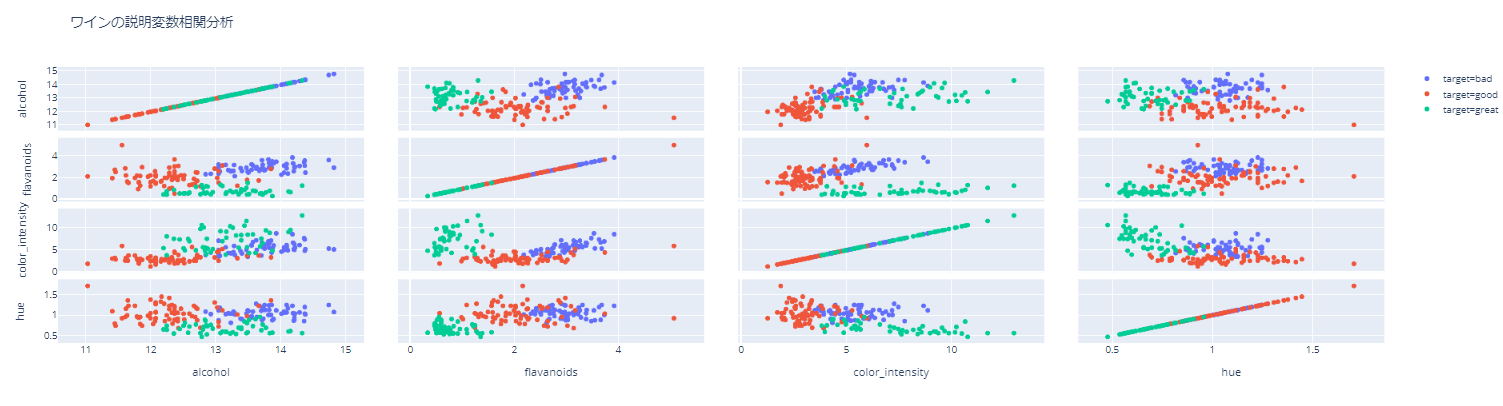
Klicken Sie hier für die HTML-Datei. https://nakanakana12.github.io/plotly/hello_world/scatter2.html
Parallele Koordinaten
** Einfache Überprüfung der Korrelation für jede Variable! !! ** ** **
Dies kann wahnsinnig nützlich sein, wenn es viele erklärende Variablen gibt.
Wenn man sich diese Abbildung ansieht, ist es offensichtlich, dass target_ID zunimmt, wenn Flavanoide und Farbton klein sind und wenn color_intensity groß ist. Ich bin der Meinung, dass die Korrelation anderer Variablen auch ziemlich leicht zu verstehen ist.
Es kann auch für kategorisierte Variablen verwendet werden.
python
fig = px.parallel_coordinates(df, dimensions=["alcohol","flavanoids", "color_intensity","hue"],color="target_ID")
fig.show()
#Als HTML speichern
fig.write_html('./parallel.html', auto_open=False)

Klicken Sie hier für die HTML-Datei. https://nakanakana12.github.io/plotly/hello_world/parallel.html
python
#Für kategoriale Variablen
fig = px.parallel_categories(df, dimensions=["alcohol_rank","flavanoids_rank","target"],color="target_ID")
fig.show()
#Als HTML speichern
fig.write_html('./parallel_cat.html', auto_open=False)

Klicken Sie hier für die HTML-Datei. https://nakanakana12.github.io/plotly/hello_world/parallel_cat.html
Am Ende
Ich wusste es selbst, aber ich hatte die Angewohnheit, es zu benutzen und gab das Lernen auf. Im Vergleich dazu fühlt sich ** Plotly Express ziemlich einfach an, um loszulegen. ** ** ** Es ist sehr praktisch, wenn Sie die Ausreißer überprüfen müssen.
Ich möchte eines Tages die 3D-Visualisierung und -Animation herausfordern.
Bis zum Ende Danke fürs Lesen. Wenn Sie es hilfreich finden, wäre es ermutigend, wenn Sie LGTM verwenden könnten.
Recommended Posts