[PYTHON] Eine Sammlung von Methoden, die beim Aggregieren von Daten mit Pandas verwendet werden
CSV-Datei lesen
data = pd.read_csv("sample.csv", encoding="UTF-8")
data
Ergebnis

Inhalt von sample.csv
Nicht notwendig,Nicht notwendig,Nicht notwendig,Nicht notwendig,Nicht notwendig,Nicht notwendig
Nicht notwendig,Titel A.,Titel B.,Titel C.,Titel D.,Nicht notwendig
Nicht notwendig,10,20,30,40,Nicht notwendig
Nicht notwendig,100,200,300,400,Nicht notwendig
Nicht notwendig,Nicht notwendig,Nicht notwendig,Nicht notwendig,Nicht notwendig,Nicht notwendig
Ich speichere die Daten in der Google-Tabelle als CSV und stelle mir die Daten bei der Analyse vor. Ich denke, es gibt einige Blätter, in denen Memos und Bemerkungen geschrieben werden, ohne strukturiert zu sein. Ich denke, dass Sie den Bereich beim Speichern auswählen können, aber dieses Mal werde ich versuchen, ihn nach dem Üben mit Pandas zu organisieren.
Ändern Sie den Inhalt der angegebenen Zeile in den Spaltennamen
data.columns = data.iloc[0]
data
Ergebnis

Extrahieren Sie nur die angegebenen Zeilen / Spalten
data = data.iloc[1:3,1:5]
data
Ergebnis
 Es ist genau das, was ich will.
Es ist genau das, was ich will.
Erstellen Sie verschiedene zusammenfassende Statistiken (Fehler)
data.describe()
Ergebnis
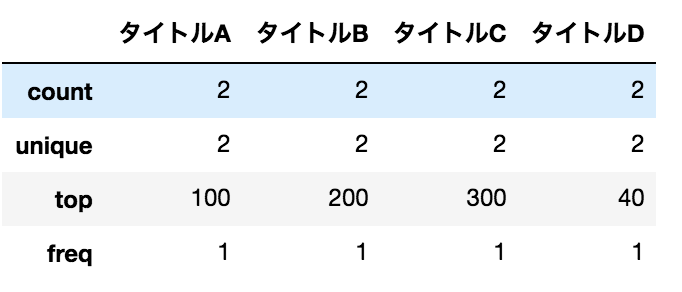 Ich dachte, dass der Durchschnitt usw. herauskommen würde, aber das tut es nicht.
Dies liegt daran, dass der Werttyp nicht numerisch ist.
Ich dachte, dass der Durchschnitt usw. herauskommen würde, aber das tut es nicht.
Dies liegt daran, dass der Werttyp nicht numerisch ist.
Ändern Sie den Werttyp
data = data.astype('int')
data
Ergebnis

Erstellen Sie verschiedene zusammenfassende Statistiken (Erfolg)
data.describe()
Ergebnis

Holen Sie sich den Korrelationskoeffizienten
data.corr()
Ergebnis
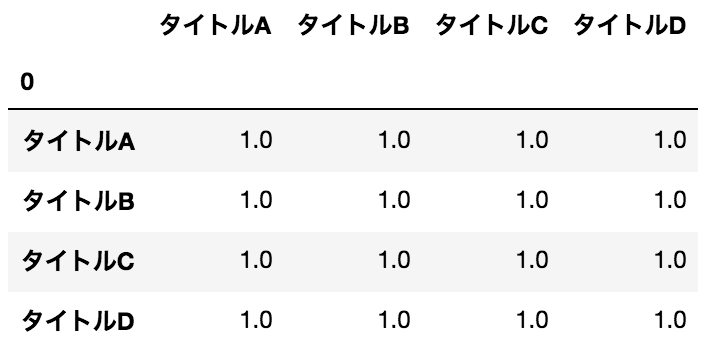 #### Bemerkungen
Ich weiß nicht, was die 0 oben links ist
#### Bemerkungen
Ich weiß nicht, was die 0 oben links ist
Verschiedene andere Dinge
data.sum() #gesamt
data.skew() #Schiefe
data.kurt() #Kurtosis
data.var() #Verteilt
data.cov() #Kovarianzmatrix
Bemerkungen
- Es war leicht zu verstehen, Kovarianz http://mathtrain.jp/covariance
- Die Kovarianzmatrix http://mathtrain.jp/covariance war leicht zu verstehen
Anzeige Diagramm Bart Diagramm
%matplotlib inline #Erforderlich, um auf Seite angezeigt zu werden
data.plot(kind='box')
Ergebnis
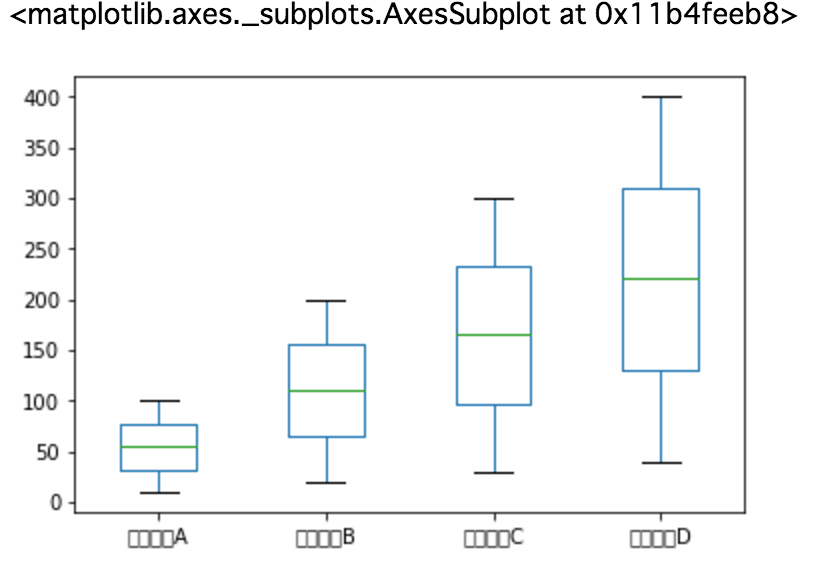 #### Bemerkungen
Das japanische Etikett wird nicht angezeigt, das japanische jedoch
```
matplotlib.rcParams['font.family'] = 'M+ 1c' #Festlegbare Schriftart
```
Es kann durch Angabe von als angezeigt werden.
Folgende Schriftarten können angegeben werden
```
import matplotlib.font_manager as fm
fm.findSystemFonts()
```
Sie können unter herausfinden.
http://qiita.com/hagino3000/items/1b54acc01483ccd0ac72
Ich bezog mich auf.
#### Bemerkungen
Das japanische Etikett wird nicht angezeigt, das japanische jedoch
```
matplotlib.rcParams['font.family'] = 'M+ 1c' #Festlegbare Schriftart
```
Es kann durch Angabe von als angezeigt werden.
Folgende Schriftarten können angegeben werden
```
import matplotlib.font_manager as fm
fm.findSystemFonts()
```
Sie können unter herausfinden.
http://qiita.com/hagino3000/items/1b54acc01483ccd0ac72
Ich bezog mich auf.
DataFrame-Join (Zeilenrichtung)
pd.concat([data,data])
Ergebnis

DataFrame-Join (Spaltenrichtung)
pd.concat([data,data], axis=1)
Ergebnis

Ändern Sie alle Werte
data.pipe(lambda df: df / 2)
Ergebnis

Nach Wert sortieren
data['Titel A.'].sort_values(ascending = True)
Ergebnis

Recommended Posts