[PYTHON] Suchen Sie nach technischen Blogs durch maschinelles Lernen mit dem Schwerpunkt "Verständlichkeit"
Ich möchte neue Technologie erwerben! Selbst wenn Sie danach suchen, ist es häufig so, dass die Artikel, die an die Spitze der Suche kommen, nicht "leicht zu verstehen" sind. Die Anzahl der Aufrufe des Artikels sowie die Anzahl der Likes und Endungen von Qiita können als Referenz verwendet werden, dies bedeutet jedoch nicht, dass es als Gefühl hoch sein sollte.
Können wir also nicht nur den "Ruf" dieser Sätze, sondern auch die Zusammensetzung und den Schreibstil der Sätze selbst bewerten und ihre "Verständlichkeit" bewerten? Also, was ich experimentell versucht habe, ist der folgende "Elephant Sense".
chakki-works/elephant_sense (Es wird ermutigend sein, wenn Sie mir einen Stern m (_ _) m geben)

- Der Name stammt aus der Geschichte, dass das Gefühl eines Elefanten tatsächlich erstaunlich ist.
Während der Entwicklung haben wir das grundlegende Verfahren zur Verarbeitung natürlicher Sprache / zum maschinellen Lernen befolgt, daher möchte ich den Prozess in diesem Artikel vorstellen.
Tor
Im Voraus habe ich versucht herauszufinden, wie einfach es ist, die Artikel von Qiita zu verstehen, indem ich "einfach gesucht" und "diejenigen mit einer hohen Anzahl von Likes extrahiert" habe (zu diesem Zeitpunkt). "Leicht zu verstehen" wurde subjektiv bewertet. In den folgenden Phasen werde ich erklären, wie man mit diesem Gefühl umgeht. Als Ergebnis wurde festgestellt, dass die Situation wie folgt ist.

Es schien, als ob die Situation so wäre, dass selbst wenn wir basierend auf Likes extrahieren würden, es nicht 50% erreichen würde, also haben wir uns das Ziel gesetzt, die Hälfte davon leicht verständlich zu machen.

Frühere Forschungen
Es gibt einige frühere Studien zur Bewertung der Verständlichkeit von Sätzen. Die folgenden zwei Indikatoren sind im englischsprachigen Raum bekannt ("Bewertungsindex für Lesbarkeit (1)) Ich bin mit dem Blog vertraut.
- Flesch Reading Ease
- Berechnet anhand der Anzahl der Wörter pro Satz (Satzlänge) und der Anzahl der Silben pro Wort
- Flesch-Kincaid Grade Level
- Verwendet die gleichen Funktionen wie Flesch Reading Ease, aber niedriger ist für höhere Noten (= schwierig)
Mit anderen Worten: "Ein langer Satz voller Wörter ist schwer zu verstehen." Im Gegenteil, wenn die Satzlänge angemessen ist und die Anzahl der verwendeten Wörter insgesamt gering ist, ist die Punktzahl gut. MS Word kann diesen Index übrigens berechnen. Es kann eine gute Idee sein, es auszuprobieren.
Der Zweck dieses Index besteht hauptsächlich darin, die Schwierigkeit von Texten zu messen, z. B. ob ein bestimmter Satz für Grundschüler oder Schüler gedacht ist. In Japan gibt es folgende Forschungsanstrengungen.
- Forschungslabor für Lesbarkeit an der Nagaoka University of Technology
- Messung der Schwierigkeit japanischer Texte im Sato / Matsuzaki-Labor, Abteilung für elektronische Informationssysteme, Graduiertenschule für Ingenieurwissenschaften, Nagoya-Universität
Da jedoch nichts als lehrbuchartiger Satz angenommen wird, wird die Punktzahl stark vom Verhältnis von pädagogischem Kanji und Hiragana beeinflusst, das im Satz enthalten ist, und es wird in Standardnotation wie in diesem technischen Blog geschrieben. Ich habe den Eindruck, dass das Messen und Schätzen des Satzniveaus vorhandener Texte begrenzt ist (dieser Punkt lautet "Über Sätze, die für japanische Lernende leicht zu lesen sind. /project-meeting/files/JCLWorkshop_no2_papers/JCLWorkshop2012_2_34.pdf) ”).
Als Abschlussstudie gab es eine Studie zur Messung der Verständlichkeit der folgenden Computerhandbücher.
Quantitative Bewertungsmethode zur Verständlichkeit des Computerhandbuchs
Diese Studie präsentiert die folgenden zwei Perspektiven zur Qualität des Ausdrucks im Handbuch.
- Genauigkeit des Ausdrucks: Richtigkeit des Inhalts, Richtigkeit der Notation (Grammatikfehler usw.)
- Ausdrucksqualität: Leicht zu verstehen, leicht zu lesen, leicht zu verwenden (Durchsuchbarkeit), konkrete Diagramme, geeignete Beispiele usw.
In Bezug auf technische Blogs gibt es zwei Punkte: "Ist der Inhalt, den Sie schreiben, korrekt?" Und "Ist der Schreibstil angemessen?" Ähnlich wie in dieser Studie konzentrieren wir uns diesmal auf die "Qualität des Ausdrucks" (da externes Wissen erforderlich ist, um festzustellen, ob der Ausdruck korrekt ist). Wie später beschrieben wird, haben wir uns auch auf diese Untersuchung für die zu verwendenden Merkmalsmengen bezogen.
Darüber hinaus habe ich die folgenden Artikel kurz als Studie zu den Merkmalen von Sätzen gelesen (siehe das neueste NIPS / EMNLP).
- Document Summarization Using Sentence Features
- Extractive Summarization Using Supervised and Semi-supervised Learning
- Recognizing contextual polarity in phrase-level sentiment analysis
- Analyzing Linguistic Knowledge in Sequential Model of Sentence
Vorbereitung der Daten
Ich habe mich dieses Mal für maschinelles Lernen entschieden, daher brauche ich trotzdem Daten. Insbesondere wurden Daten mit Anmerkungen versehen, z. B. "Dieser Artikel ist leicht zu verstehen / schwer zu verstehen".
In der Regel ist es wichtig, die Aufgabe vor dem Kommentieren gut zu gestalten.
NAIST Text Corpus Annotation Specification
Diese Methode ist in den folgenden Büchern sehr gut organisiert. Es empfiehlt sich daher, sie beim Kommentieren von Textdaten einmal zu lesen.
Natural Language Annotation for Machine Learning
Dieses Mal haben wir uns entschieden, "leicht verständlich" als Standard für "Können Junioren es lesen?" Zu verwenden. Dies soll verhindern, dass die Klarheit des Wissens des Kommentators beeinträchtigt wird. Und ich habe beschlossen, es am 0/1 zu bewerten. Dies liegt daran, dass es schwierig war, die Bühne zu definieren, und nur drei Mitglieder des Teams für die Bewertung mobilisiert werden konnten. Daher war es notwendig, sie so stabil wie möglich zu gestalten (ich habe sie leicht geschrieben, aber dies ist "leicht zu verstehen". Es gab viele Debatten darüber, wie man Anmerkungen macht.
Außerdem habe ich beschlossen, das Zielkorpus von Qiita zu nehmen. Mit anderen Worten, diesmal besteht der Zweck darin, "zu bewerten, ob Qiitas Artikel von Junioren am 0/1 gelesen werden können oder nicht" und die Punktzahl vorherzusagen, um "die Anzahl der Artikel, die sich leicht verständlich anfühlen, auf 50% zu erhöhen". (Gemäß dem obigen Buch war es wichtig, dass die Annotationsarbeit und die darüber hinaus zu erledigende Aufgabe richtig miteinander verknüpft waren).
Die Annotation wurde für 100 Artikel durchgeführt. Wenn Sie jedoch die Artikel zufällig auswählen, haben die meisten Artikel eine geringe Anzahl von Likes, daher habe ich das angepasst. Das endgültige Annotationsergebnis lautet wie folgt (3 ist MAX (alle hinzugefügt 1), da es von 3 Personen erstellt wurde).

Wir werden ein Modell mit diesen Daten erstellen.
Ein Modell bauen
Wenn Sie süchtig nach neuronalen Netzen sind, tendieren Sie dazu, Word2Vec zum Codieren mit RNN zu verwenden, aber dieses Mal habe ich beschlossen, ein Modell zu erstellen, das die Basislinie darstellt.
Die Merkmalsmengen, die als Kandidaten unter Bezugnahme auf frühere Forschungsergebnisse ausgewählt wurden, sind wie folgt.
- Length Feature
- Satzlänge (Durchschnitt / Maximum / Minimum)
- Kurslänge
- Abschnittslänge
- Satzlänge
- Counting Feature
- Anzahl der Wörter
- Wort TF / IDF
- Verhältnis Hiragana / Katakana / Kanji / Alphabet / Zahl
- Anzahl der Satzzeichen
- Anzahl der Zeilenumbrüche
- Anzahl der hervorgehobenen Wörter (Schlüsselklammer / doppeltes Anführungszeichenpaar)
- Anzahl / Verhältnis der Aufzählungszeichen (bezogen auf die Gesamtzahl der Sätze)
- Anzahl und Verhältnis der Überschriften (bezogen auf die Gesamtzahl der Sätze)
- Anzahl der Zahlen (Bild) / Verhältnis (bezogen auf die Gesamtzahl der Sätze)
Das Bild von Merkmalen in natürlicher Sprache ist grundsätzlich entweder in "Länge" oder "Zahl" unterteilt. "Zahl" kann durch Hinzufügen einer Populationsnummer als "Häufigkeit (Wahrscheinlichkeit)" und durch Hinzufügen von Voraussetzungen als "bedingte Wahrscheinlichkeit" abgeleitet werden.
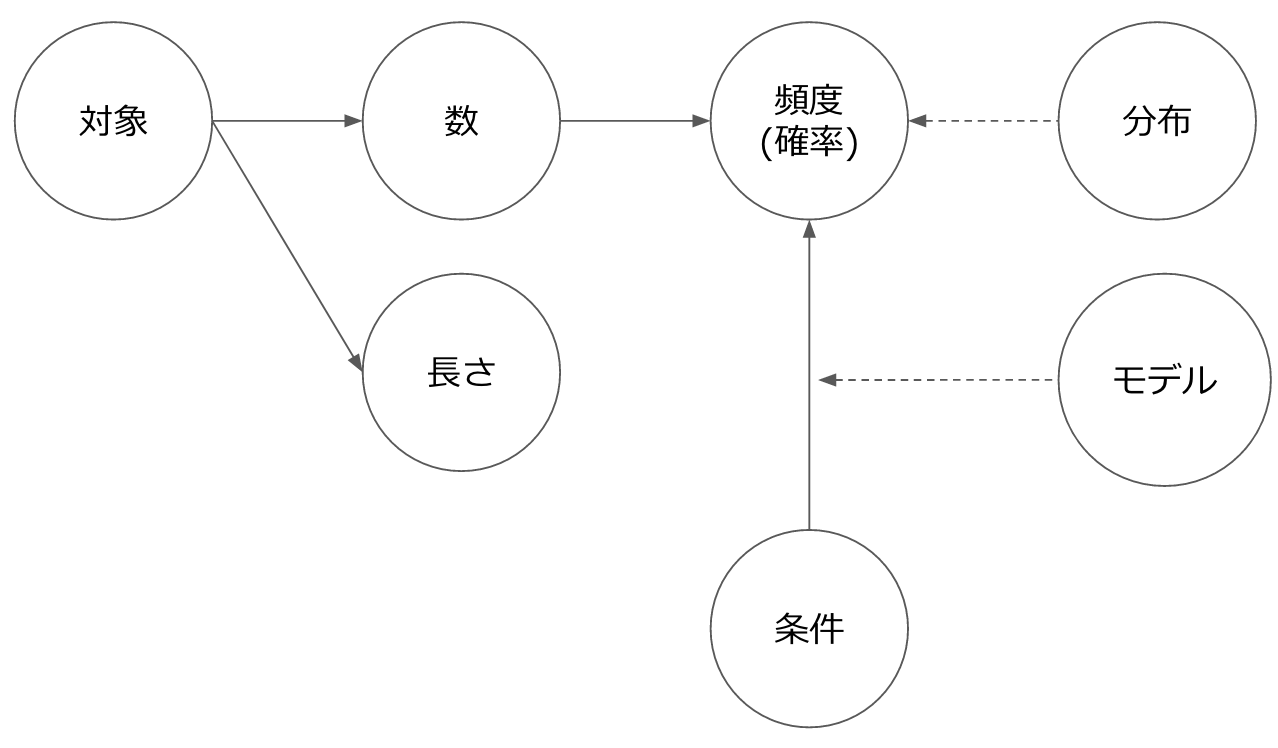
Was die Worte betrifft, habe ich diesmal die Vorverarbeitung sehr sorgfältig durchgeführt (@Hironsan sollte diesen Bereich später erklären).
Ich habe versucht, den einfachen RandomForest mit den aufgeführten Funktionen zu verwenden. (RandomForest ist auch gut, weil Sie den Beitrag jedes Feature-Betrags leicht sehen können).
Hier ist das Ergebnis der tatsächlichen Erstellung des Modells.
elephant_sense/notebooks/feature_test.ipynb

Der Datensatz ist klein, aber viel genauer. Wenn man sich die Funktionen ansieht, scheint das Folgende gut zu funktionieren.
- image_count: Anzahl der Figuren
- satz_max_length: Maximale Länge des Satzes
- user_followers_count: Anzahl der Follower des Benutzers
Es bedeutet: "Es wird von einer zuverlässigen Person geschrieben, es wird mit einer angemessenen Satzlänge geschrieben und es enthält eine Zahl." Insbesondere das Vorhandensein oder Fehlen der Figur war sehr effektiv. "Anzahl der Follower von Benutzern" widerspricht dem Zweck dieser Zeit, und es war ursprünglich eine Richtlinie, sie aufgrund der einzigartigen Eigenschaften von Qiita nicht aufzunehmen, sondern aufgrund der Genauigkeit + Informationen über "Schriftsteller", wenn sie in Zukunft auf andere Sätze angewendet werden Ich habe beschlossen, es einzulegen, weil es in irgendeiner Form genommen werden kann.
Darüber hinaus ist das Ergebnis der Klassifizierung nur nach den Likes, die dieses Mal verglichen werden sollen, wie folgt.
elephant_sense/notebooks/like_based_classifier.ipynb

Wenn Sie sich das ansehen, können Sie sehen, dass der "leicht verständliche" Satz (1) nicht vorhergesagt werden kann. In diesem Sinne scheint dieses Modell nützlicher zu sein als ich erwartet hatte.
Einbeziehung in die Anwendung
Lassen Sie uns eine Anwendung erstellen, die tatsächlich verwendet werden kann, indem das erstellte Modell integriert wird.
Beim Einbetten eines maschinellen Lernmodells in eine Anwendung wird das in diesem Modell verwendete Objekt zur Normalisierung verwendet (diesmal StandardScaler. Beachten Sie, dass) ebenfalls erforderlich ist. Wenn Sie beim Erstellen des Modells normalisiert haben, müssen Sie bei der Erstellung von Vorhersagen natürlich normalisieren.
Das Frontend ist einfach und mit Vue.js/axios erstellt. axios ist eine Bibliothek zum Senden von http-Anfragen, die sowohl auf der Serverseite (Node) als auch auf der Clientseite verwendet werden kann (insbesondere die Unterstützung von XSRF-Cookies wurde geschätzt).
Die fertige Anwendung wurde in Heroku bereitgestellt. Da wir dieses Mal Scicit-Learn usw. verwenden, ist die normale Bereitstellung schwierig, sodass wir die Bereitstellung mit Docker durchführen.
Container Registry and Runtime
Bis jetzt musste ich ein Buildpack-Handwerker werden, daher ist dies praktisch (aber es ist ein bisschen schmerzhaft, weil es nicht in einer Proxy-Umgebung verwendet werden kann).
Die bereitgestellte Anwendung lautet wie folgt.
Aber ... langsam! Ich hätte wirklich gerne mehr Beiträge zur Bewertung, aber ich schränke sie aufgrund der Leistung ein (derzeit erziele ich 50 Suchergebnisse und zeige sie an). Ich mache vorerst Parallelverarbeitung, aber schließlich analysiere ich jeden Satz in HTML und extrahiere Features ... also wird es ziemlich langsam sein. Ich denke, dass hier Verbesserungen erforderlich sind, einschließlich Einfallsreichtum auf der Front-End-Seite.
Was das Anzeigeergebnis betrifft, habe ich den Eindruck, dass es in Ordnung ist. Um jedoch 50% des Ziels zu erreichen, müssen vor der Anzeige mehr Sätze ausgewertet werden, sodass es zwei Seiten derselben Medaille mit dem oben genannten Leistungsproblem gibt.
Das Tag meter wird verwendet, um die Punktzahl anzuzeigen. Ich habe zum ersten Mal in dieser Entwicklung von der Existenz erfahren. Wie das "Fortschritt" -Tag gibt es einige Tags, die ich nicht kenne.
von jetzt an
Ich habe den Eindruck, dass ich eine Reihe von Prozessen wie Problemstellung, Datenerfassung, Modellkonstruktion und Anwendung durchlaufen habe. Wenn sich dies weiterentwickelt, kann es meiner Meinung nach auf Entwurfsdokumente, API-Dokumente usw. angewendet werden, um die Qualität von Dokumenten zu verbessern und neue Teilnehmer bei der Suche nach "gut organisierten" Sätzen zu unterstützen. ..
Derzeit arbeitet mein Team chakki an einer "Gesellschaft, in der jeder bis zur Teezeit (15:00) zurückkehren kann" durch maschinelles Lernen / Verarbeitung natürlicher Sprache. Wir versuchen es zu realisieren. Zunächst arbeiten wir derzeit an Informationen in natürlicher Sprache (Dokumente, Überprüfungen, Quellcode usw.) in der Systementwicklung.
 [@chakki_works](https://twitter.com/chakki_works)
[@chakki_works](https://twitter.com/chakki_works)
Wenn Sie interessiert sind, Bitte kommen Sie und hören Sie zu!
Recommended Posts