[PYTHON] Implementieren Sie das Convolutional Neural Network
Es ist beliebt, Deep Learning-Bibliotheken auszuprobieren, aber selbst wenn es in Ordnung ist, Example auszuführen, funktioniert es oft nicht, wenn Sie versuchen, es in realen Fällen zu verwenden.
Ich habe versucht, es zu verschieben, aber die Genauigkeit ist nicht herausgekommen, die Art der Datenverarbeitung war schlecht, die Parameter des Modells waren schlecht, ich kenne die Ursache überhaupt nicht ... Um die Situation zu überwinden, ist es immer noch notwendig, den Mechanismus zu verstehen. Ich werde.
Aus diesem Grund möchte ich in diesem Band die zu treffenden Schritte und die Gründe dafür erläutern, von der ersten Startlinie der Bildvorbereitung bis zum Erlernen des in Chainer implementierten CNN. Theorie wird als erster Teil geschrieben, aber hier, wie die in der Bibliothek usw. festgelegten Parameter mit der Seite der Theorie übereinstimmen Ich würde auch gerne sehen.
Das diesmal eingeführte Know-how ist im folgenden Repository zusammengefasst. Ich hoffe, dass es bei der Bilderkennung hilfreich sein wird.
Datenaufbereitung
Es ist leicht zu glauben, dass Sie viele Daten wie Zehntausende vorbereiten müssen, aber bei der neueren Bilderkennung ist es üblich, ein trainiertes Modell zu verwenden.
 CS231n Lecture11 Training ConvNets in practice, p26
CS231n Lecture11 Training ConvNets in practice, p26
Kann das trainierte Modell nicht nur "trainierte Aufgaben" ausführen? Wie Sie vielleicht denken (z. B. Katzenerkennung), können die unteren Ebenen des Modells die Grundfunktionen des Bildes extrahieren. Daher ist es durch Trainieren (oder Hinzufügen) nur der oberen Schicht, während die untere Schicht unverändert bleibt, möglich, selbst mit einer kleinen Datenmenge eine Unterscheidungsleistung zu erzielen. Dies wird als Feinabstimmung (oder Transferlernen) bezeichnet.
Wie viele Ebenen Sie verlassen sollten, hängt davon ab, wie nahe Ihre beabsichtigte Aufgabe an der ursprünglichen "trainierten Aufgabe" liegt.
 CS231n Lecture11 Training ConvNets in practice、p33
CS231n Lecture11 Training ConvNets in practice、p33
Caffe ist eine bekannte Bibliothek für die Verwendung trainierter Modelle. Es gibt eine offizielle Beschreibung der Feinabstimmungsmethode mit Caffe.
Fine-tuning CaffeNet for Style Recognition on “Flickr Style” Data
Chainer kann Caffe-Modelle laden, daher ist auch eine Feinabstimmung möglich.
Persönliche Best Practices für die Feinabstimmung mit Chainer
Wenn Sie den Wert des trainierten Modells, das Sie beim Training gelernt haben, nicht ändern möchten, können Sie das Flag "volatitle" verwenden, um die Fehlerausbreitung auf die trainierte untere Ebene zu stoppen.
Unten finden Sie ein Tutorial zu TensorFlow.
Wenn Sie ein Modell von Caffe mitbringen möchten, gibt es die folgenden Tools.
Auf diese Weise nimmt die Anzahl der zu erfassenden Daten aufgrund der Leistungen unserer Vorgänger allmählich ab. Dieses Mal habe ich das trainierte Modell gespeichert. Verwenden Sie es daher zum ersten Mal (ich habe git lfs verwendet).
Man kann jedoch sagen, dass es immer notwendiger wird zu verstehen, welche Art von Modell ich als Basis verwende. Dieser Punkt wird im nächsten Abschnitt erläutert. Daher werden wir hier kurz die Erfassung von Bilddaten aus ImageNet erläutern, das als Bilddatensatz bekannt ist.
Ein Datensatz, der Bilder basierend auf der konzeptionellen Struktur des Wortes WordNet markiert. Die Anzahl der registrierten Wörter (dh Beschriftungen) beträgt ungefähr 100.000, und es werden Aktivitäten durchgeführt, um ungefähr 1000 Bilder für jedes Wort zu sammeln. Es ist auch als der in ILSVRC (Image Net Large Scale Visual Recognition Challenge) verwendete Datensatz bekannt.
Wenn Sie jetzt Forscher sind, können Sie den gesamten Datensatz herunterladen, wenn Sie sich bewerben und die Erlaubnis erhalten. Ist dies nicht der Fall, können Sie die URL des Bildes für jedes Etikett abrufen und müssen sie selbst löschen. Darüber hinaus können auch Daten wie Bildmerkmalsdaten und Objektgrenzen erfasst werden.

Sie können die URL des Bildes vom Download erhalten. Es gibt jedoch viele defekte Links.

Ich habe es gemacht, weil es die menschliche Natur ist, parallel herunterladen zu wollen und dabei defekte Links zu vermeiden.
mlimages/mlimages/scripts/gather_command.py
Nehmen wir nun an, Sie haben das Bild vorerst heruntergeladen und vorbereitet.
Das Modell verstehen
Die gesammelten Bilder müssen entsprechend der gewünschten Aufgabe und dem zu verwendenden trainierten Modell verarbeitet werden. Daher möchte ich hier mein Verständnis vertiefen, indem ich dem Code des tatsächlichen Modells folge. Der AlexNet-Code von Chainer wird zur Erklärung verwendet. Dies ist ein monumentales Modell, mit dem die Aktivität des neuronalen Netzes bei der Bilderkennung begann. Beachten Sie, dass die Definition des Netzwerks für andere Bibliotheken als Chainer (Caffe usw.) nahezu identisch ist. Sie können also davon ausgehen, dass die hier erläuterten Inhalte auch auf andere als Chainer angewendet werden können.
chainer/examples/imagenet/alex.py
Es ist ein sehr kurzer Code, daher werde ich einen Auszug der Definition unten veröffentlichen.
class Alex(chainer.Chain):
"""Single-GPU AlexNet without partition toward the channel axis."""
insize = 227
def __init__(self):
super(Alex, self).__init__(
conv1=L.Convolution2D(3, 96, 11, stride=4),
conv2=L.Convolution2D(96, 256, 5, pad=2),
conv3=L.Convolution2D(256, 384, 3, pad=1),
conv4=L.Convolution2D(384, 384, 3, pad=1),
conv5=L.Convolution2D(384, 256, 3, pad=1),
fc6=L.Linear(9216, 4096),
fc7=L.Linear(4096, 4096),
fc8=L.Linear(4096, 1000),
)
self.train = True
def clear(self):
self.loss = None
self.accuracy = None
def __call__(self, x, t):
self.clear()
h = F.max_pooling_2d(F.relu(
F.local_response_normalization(self.conv1(x))), 3, stride=2)
h = F.max_pooling_2d(F.relu(
F.local_response_normalization(self.conv2(h))), 3, stride=2)
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = F.max_pooling_2d(F.relu(self.conv5(h)), 3, stride=2)
h = F.dropout(F.relu(self.fc6(h)), train=self.train)
h = F.dropout(F.relu(self.fc7(h)), train=self.train)
h = self.fc8(h)
self.loss = F.softmax_cross_entropy(h, t)
self.accuracy = F.accuracy(h, t)
return self.loss
Wenn Sie es jetzt selbst anpassen und verwenden möchten, sind die wichtigsten Teile die Eingabe- und Ausgabeteile.
Der Eingabeteil hängt von der Größe des Bildes ab und davon, ob es Graustufen sein soll oder nicht. Der Ausgabeteil ist wichtig, wenn Sie die Anzahl der Klassen hinzufügen oder ändern, die bei der Implementierung der Feinabstimmung identifiziert werden sollen. Werden.
Zunächst zur Eingabe. Die Punkte sind wie folgt.
- Bildgröße:
insize = 227 - Erste Schicht, die Eingaben empfängt: "conv1 = L.Convolution2D (3, 96, 11, Schritt = 4)"
Wichtig ist die Definition der ersten Schicht. Gemäß der Convolution2D API können die Einstellungen wie folgt interpretiert werden.
- in_channel: 3
- out_channel: 96
- ksize: 11
- stride: 4
Was bedeuten diese Elementwerte? Hier im theoretischen Teil [Definition des für die Faltung verwendeten Filters](http://qiita.com/icoxfog417/items/5fd55fad152231d706c2#%E3%83%95] % E3% 82% A3% E3% 83% AB% E3% 82% BF% E3% 81% AE% E8% A8% AD% E5% AE% 9A).
- Anzahl der Filter (K): Die Anzahl der zu verwendenden Filter. Ungefähr der Wert der zweiten Potenz wird genommen (32, 64, 128 ...)
- Filtergröße (F): Die Größe des verwendeten Filters
- Filterbewegungsbreite (S): Breite zum Verschieben des Filters
- Auffüllen (P): Wie viel soll der Randbereich des Bildes ausfüllen?
Zunächst einmal ist ein Filter wie ein Fenster, das zum Falten verwendet wird. Das folgende Bild bestimmt, wie stark das Originalbild um diese Größe komprimiert wird und so weiter.

Dann ist es leicht zu verstehen, wie die Größe des Filters die Größe nach der Komprimierung bestimmt, indem man die folgende Abbildung betrachtet.
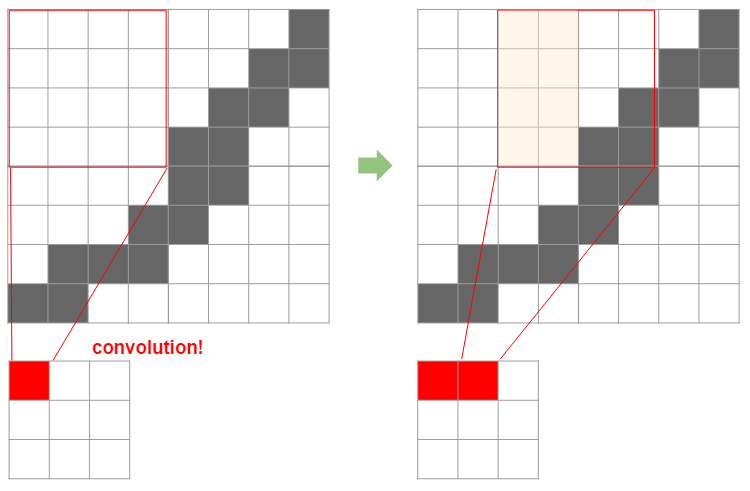
Hier wird ein 4x4-Filter auf ein 8x8-Bild angewendet, indem es um zwei verschoben wird. In diesem Fall wird das endgültige 8x8-Bild auf 3x3 komprimiert. Hier beträgt die Originalgröße $ N $, die Filtergröße $ F $, die Folienbreite $ S $ und die komprimierte Bildbreite wird nach der folgenden Formel berechnet.
Wenn wir diese Formel anwenden, können wir sehen, dass $ (8 -4) / 2 + 1 = 3 $ genau 3 ist. Wenn das Auffüllen von $ P $ verwendet wird, um einen Rand um das Bild herum zu erstellen (tatsächlich ist die Helligkeit 0 = schwarz, und in diesem Sinne ist der Rand ** schwarz **), ist dies wie folgt.
Dies ist anhand der folgenden Abbildung leicht zu verstehen. Dies bedeutet, dass die Randgröße x 2 zur Originalgröße hinzugefügt wird.

Wie Sie an der Tatsache erkennen können, dass die Unterteilung enthalten ist, müssen Sie die Breite des anzuwendenden Filters, die Folienbreite usw. so einstellen, dass sie richtig teilbar sind. Dies ist die erste Einschränkung bei Verwendung anderer Modelle.
Ich werde bis hierher zusammenfassen. Es wurde festgestellt, dass die Breite der Schicht nach dem Aufbringen des Filters unter Verwendung der folgenden drei Punkte aus den ersten genannten Punkten berechnet werden kann.
- Filtergröße (F): Die Größe des verwendeten Filters
- Filterbewegungsbreite (S): Breite zum Verschieben des Filters
- Auffüllen (P): Wie viel soll der Randbereich des Bildes ausfüllen?
** Schichtbreite nach dem Filtern = $ (N + P \ mal 2 - F) / S + 1 $ ** ** Das Eingabebild muss zu den im vorhandenen Modell verwendeten Filtern passen (das Ergebnis der obigen Formel ist eine saubere Ganzzahl) **
Was nun mit der letzten verbleibenden "Anzahl der Filter (K)" zusammenhängt, ist die "Tiefe (Anzahl der Kanäle)" des Bildes. Die Anzahl der Kanäle ist das Tiefenelement im Bild und entspricht der Farbe (RGB) im Bild. Daher beträgt die Anzahl der Kanäle in der ersten Schicht häufig 3. Im Gegenteil, wenn das vorhandene Netzwerk verwendet wird und dies 1 ist, bedeutet dies Graustufen und muss durch Vorverarbeitung in Graustufen umgewandelt werden.
Lassen Sie uns nun darüber nachdenken, was nach dem Falten mit der Tiefe passiert. Die Tiefe des Filters entspricht der Tiefe des Eingabebildes (andernfalls kann es nicht berechnet werden), sodass die Tiefe nach der Faltung immer "1" ist. Was ist nun, wenn wir weitere Filter hinzufügen? Dies erhöht die Anzahl der Faltungsschichten mit einer Tiefe von 1 um die Anzahl der Filter (siehe Abbildung unten).

Normalerweise verwendet CNN auf diese Weise mehrere Filter für die Faltung. Mit anderen Worten ist die "Anzahl der Filter (K)" die "Tiefe (Anzahl der Kanäle)" nach dem Falten. Dies entspricht natürlich der Eingabetiefe der nächsten Ebene (ich denke, der out_channel von conv1 und der in_channel von conv_2 haben im Code den gleichen Wert).
Nachdem wir alle Elemente eines Filters gesehen haben, wollen wir die Definition von Ebene 1 noch einmal überprüfen.
- in_channel: 3-> Tiefe des ersten Bildes. RGB = 3
- out_channel: 96-> Tiefe der Schicht nach der Faltung = Anzahl der Filter (K)
- ksize: 11-> Filtergröße (F)
- Schritt: 4-> Filterschlittenbreite (S)
Convolution2D hat auch einen Parameter für pad, der natürlich dem Padding (P) entspricht. Jetzt verstehen Sie die Parameter. Und von hier aus können Sie sehen, dass AlexNet die folgenden Einschränkungen hat:
- Die Größe des Eingabebildes muss nach Subtraktion von 11 durch 4 teilbar sein (die eingestellte Größe 227 erfüllt dies). * Genau genommen ist es notwendig, die Definition der folgenden Schichten zu erfüllen.
- Das Eingabebild muss in RGB-Farbe dargestellt werden
Daher ist die Größe des Bildes nicht wirklich festgelegt, und andere Größen können verwendet werden, wenn die Bedingungen erfüllt sind. Wenn Sie jedoch nicht wissen, ob der zuvor erlernte Inhalt angewendet wird, ist der Ausgabeteil betroffen. In AlexNet ist es eine lineare Funktion aus der 6. Schicht, und von hier aus ist es der Teil, der anhand des gewundenen Ergebnisses klassifiziert. Wenn Sie eine Feinabstimmung durchführen, müssen Sie diese ersetzen oder mit SVM verbinden. In diesem Fall müssen Sie jedoch die folgende Definition verstehen. Die Definition der 6. Schicht von Chainer lautet "fc6 = L.Linear (9216, 4096)", woraus hervorgeht, dass die Anzahl der Eingänge 9216 und die Anzahl der Ausgänge 4096 beträgt, der Eingang jedoch "9216". Wissen Sie was das bedeutet?
Da die Ausgabe von der Faltungsschicht natürlich "Breite x Höhe x Tiefe" ist, wird gefolgert, dass die vorherige "Faltung" "Breite x Höhe x Tiefe = 9216" ist. Die Tiefe ergibt sich aus der Tatsache, dass der out_channel von "conv5" 256 ist. Wenn Sie also 9216 durch 256 teilen, können Sie sehen, dass es 36 ist, also Breite x Höhe = 36, also ist die Breite 6. Diese "6" ist natürlich, wenn die Breite des Eingabebildes wie definiert 227 beträgt. Wenn Sie also die Größe des Eingabebilds ändern möchten, müssen Sie mehr hinzufügen und die Größe anpassen. Natürlich können Sie die Größe anpassen, indem Sie sie falten, aber Sie können auch ein Pooling verwenden, das die Größe ohne Verwendung von Gewichten anpasst, dh die Breite komprimiert (siehe hier für Details zum Pooling) (http: / /qiita.com/icoxfog417/items/5fd55fad152231d706c2#%E3%83%AC%E3%82%A4%E3%83%A4%E6%A7%8B%E6%88%90)).
Diese Pooling-Schicht wird auch in AlexNet verwendet. Aufgrund dieses Poolings beträgt die Breite, die zum Zeitpunkt von conv5 13 betrug, jetzt 6 bei fc6. Die folgende Abbildung zeigt den Berechnungsprozess bis fc6. Wenn Sie also interessiert sind, folgen Sie ihm bitte. Die Berechnungsreihenfolge lautet conv1> pool1> conv2> pool2> conv3> conv4> conv5> pool5> fc6 (* Es gibt kein Pooling zwischen conv3> conv4 und conv4> conv5).
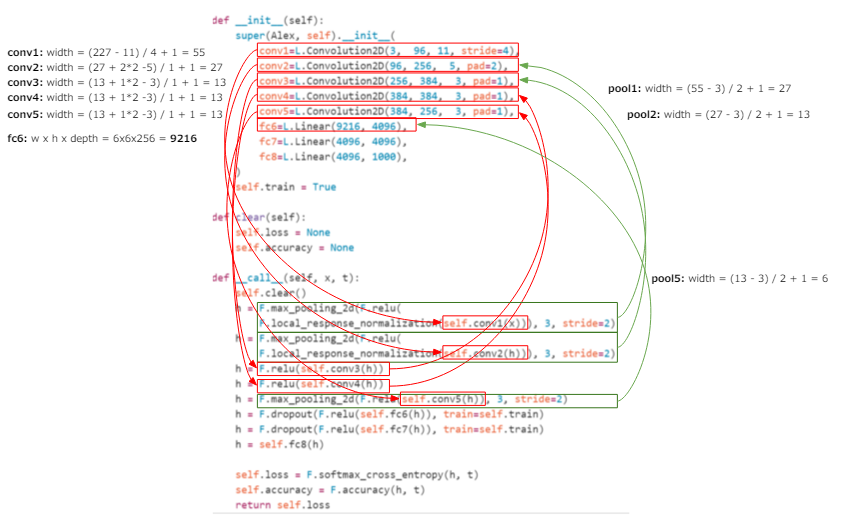
Wenn Sie ein großes Bild verwenden, sollten Sie es daher mit diesem Pooling etwas stärker komprimieren (im Gegenteil, wenn es klein ist, wird es nicht gepoolt). Wie bereits erwähnt, werden bei diesem Pooling keine Gewichte verwendet, sodass die Gewichte, die Sie vom trainierten Modell mitbringen, irrelevant sind. Wenn Sie ein trainiertes Modell verwenden, ist es daher besser, die Einstellung durch Pooling anstelle der trainierten und gewichteten Faltungsschicht vorzunehmen.
Abschließend werde ich die Punkte beim Anpassen des trainierten Modells zusammenfassen. Theoretisch denke ich, dass dies im tatsächlichen Gebrauch funktionieren kann oder nicht. Ich möchte es noch einmal zusammenfassen, sobald ich es verstehe.
-
Die Ebenendefinition zeigt Größen- und Farbbeschränkungen an
-
Wenn Sie eine Lernmaschine für die Feinabstimmung an eine bestimmte Ebene anhängen möchten, kann die Anzahl der Eingaben abgeleitet werden, indem die Größe des Eingabebilds und die Filterdefinition jeder Ebene der Reihe nach berechnet werden.
-
Heutzutage ist es etwas kompliziert, Filter anzuwenden, und die Ebenen werden tiefer. Daher wird nicht empfohlen, sie zu berechnen, außer zum Lernen. Die oberste Ebene sollte mit der Anzahl der zu klassifizierenden Klassen übereinstimmen. Es wird daher empfohlen, sie gehorsam an der obersten Ebene anzubringen.
-
Wenn Sie die Größe des Eingabebilds ändern möchten, behalten Sie die trainierte gewichtete Faltungsebene bei und passen Sie sie mit Pooling an
-
In letzter Zeit ist es zum Mainstream geworden, Pooling nicht zu beißen, aber ich denke, es ist möglich, es einzusetzen, um das trainierte Modell abzulenken.
-
Informationen zu "Kürzlich" finden Sie unter Stanfords Vorlesung (Vorlesung 7, S. 89). Es gibt auch ein bisschen über AlphaGo. Das Verständnis von CNN führt auch zum Verständnis des hochmodernen KI-Mechanismus.
Datenvorverarbeitung
An diesem Punkt verstehe ich das Modell und weiß, welche Art von Daten vorbereitet werden sollten. Was jedoch beim eigentlichen Training benötigt wird, ist kein "Bild", sondern eine "Matrix", die es numerisch ausdrückt. Wenn Sie bei diesem Konvertierungsprozess einen Fehler machen, hilft das trainierte Modell nicht weiter. Die wichtigsten Punkte sind wie folgt.
- Matrixtransformation
- Intuitiv Breite (B) x Höhe (H) x Tiefe (K)
- Wenn Sie in Form einer Matrix denken, entsprechen die Zeilen der Matrix der Höhe und die Spalten der Breite, sodass die Matrix H x B x K ist.
- Beim Lernen ist es üblich, dies weiter in K x H x B umzuwandeln
- Die tatsächliche Verarbeitung finden Sie unter chainer / examples / imagenet / train_imagenet.py
read_image. .. - Tiefeneinstellung
- Wenn das Modell RGB, aber nur Helligkeit annimmt, duplizieren Sie den Helligkeitswert und passen Sie ihn an. Nur die Helligkeit kann durch die Tatsache identifiziert werden, dass die Dimension 2 ist (da keine Farbe vorhanden ist, wird sie durch eine zweidimensionale Matrix dargestellt).
- Es gibt ein Format namens RGBA auf der Welt, daher wird in diesem Fall A gelöscht.
- Informationen zur tatsächlichen Verarbeitung finden Sie unter
load_imagein Caffe / io.py. - Normalisierung von Bilddaten
- Normalisieren durch Subtrahieren des berechneten Durchschnitts von allen Datensätzen. Beachten Sie, dass natürlich alle Bildgrößen gleich sein müssen.
- Den durchschnittlichen Berechnungsprozess finden Sie unter chainer / examples / imagenet / compute_mean.py.
- Skalierung
- RGB-Farbe und -Helligkeit nehmen Werte von 0 bis 255 an. Teilen Sie diese durch 255, um sie in einen Wert von 0-1 umzuwandeln.
- Die tatsächliche Verarbeitung finden Sie unter chainer / examples / imagenet / train_imagenet.py
read_image. ..
In dem diesmal erstellten Tool haben wir eine Klasse (LabeledImage) implementiert, die ein Bild liest, die Tiefe anpasst und dann eine Matrixkonvertierung durchführt.
to_array und from_array können von dort aus matrixiert und wiederhergestellt werden. Da es auch eine Methode zum Ändern der Bildgröße gibt, ist es möglich, nach der Verarbeitung eine Matrix zu erstellen, z. B. eine Größenanpassung. Ich hoffe, Sie können es als Referenz für die Implementierung verwenden.
Die Implementierung für die Mittelwertbildung ist fast dieselbe, aber ich habe versucht, sie als tatsächliches Image zu speichern. Dies macht es auch dann verfügbar, wenn Sie kein Numpy verwenden, und hat den zusätzlichen Vorteil, dass Sie Trends in Ihren Daten sehen können.
Das Folgende ist ein durchschnittliches Bild, das aus ImageNet-Katzenbildern erstellt wurde. Sie können jedoch sehen, dass keine Funktionen sichtbar sind.

Das ist ein schlechter Trend. Dies liegt daran, dass sich die Farbe usw. nur in diesem Teil geändert haben sollte, wenn es eine Funktion gibt, die allen Bildern gemeinsam ist (für ein menschliches Gesicht die Position der Augen und des Mundes usw.). Wenn die Anzahl der Bilder groß ist, ist es natürlich, dass sie insgesamt schwärzlich sind, aber ich denke, dass sie verwendet werden können, um die Tendenz zu erfassen, sie nur in einer bestimmten Klasse zu erstellen.
Vorbereitung der Lehrerdaten
Sie können nicht einfach lernen, indem Sie Bilder vorbereiten. Für dieses Bild müssen wir Lehrerdaten erstellen, z. B. zu welcher Klasse es gehört. Hierzu wird häufig das Format verwendet, in dem der "Bildpfad" und das "Lehrerlabel" als Paar beschrieben werden (das Gefühl unten).
tabby\51879196_5a4404873a.jpg 10
tortoiseshell\1802271715_d1b3acb8f4.jpg 13
tom\1433889998_6a42ce2633.jpg 12
Wenn Sie dies manuell tun, geht die Sonne natürlich unter, daher möchte ich sie automatisch erstellen. Wenn die Bilder in Ordnern für jede Klasse gespeichert sind, entspricht die Ordnerstruktur den Lehrerdaten, sodass Sie damit Lehrerdaten erstellen können.
Selbst mit dem diesmal erstellten Tool habe ich ein einfaches Skript erstellt und es beschriftet (mlimages / mlimages / scripts / label_command.py. /label_command.py)).
Wenn Sie Bilder automatisch durch Scraping usw. sammeln, können Sie sie manchmal nicht öffnen oder einige von ihnen eignen sich möglicherweise nicht als Lehrerdaten. Es ist eine gute Idee, diese Faktoren hier zu eliminieren, da Sie weinen möchten, wenn Sie diese Bilder während des Lernens treffen und eine Ausnahme fliegt und Sie stundenlang aufhören zu lernen. Beim Lernen muss das durchschnittliche Bild für die Normalisierung berechnet werden (siehe oben). Zu diesem Zeitpunkt werden Konvertierung und Berechnung in dieselbe Matrix wie in der Produktion durchgeführt, sodass Sie dort nachsehen können. Dieses Mal wird bei der Berechnung des Durchschnittsbildes das "für die Durchschnittsberechnung verwendete (erstellte) Bild" als Datei ausgegeben und als Trainingsdaten verwendet.
Das Aufteilen der Daten in Test und Training, das ordnungsgemäße Mischen usw. entspricht dem normalen maschinellen Lernen. Dies kann einfach durch Teilen der Datei oder Verarbeiten mit Zufallszahlen erfolgen, daher denke ich nicht, dass es zu viel Mühe gibt.
Modelllernen
Sobald die Lehrerdaten fertig sind, müssen Sie nur noch trainieren. Die größte Überlegung hierbei ist die Leistung und Überwachung (es scheint sich um die Betriebsführung zu handeln ...).
Performance
Für die Leistung sind folgende Punkte wichtig:
- GPU
- Parallelverarbeitung
GPU. Ich war mir dessen sehr bewusst, aber lassen Sie uns trotzdem einen GPU-Computer vorbereiten (AWS ist ebenfalls akzeptabel). Mit einer CPU können Sie nicht sicher sein, dass sich die Genauigkeit verbessert, selbst wenn Sie einige Tage warten. Mit einer GPU können Sie sie jedoch in wenigen Stunden sehen oder die Berechnung ist abgeschlossen. Während des Trainings müssen viele Parameter angepasst werden, z. B. die Modellkonfiguration, Hyperparameter wie die Trainingsrate und die Stapelgröße. Der Schlüssel ist, wie schnell dieser Überprüfungs- / Bestätigungszyklus ausgeführt werden kann. Daher ist es besser, ihn mit Hardware zu lösen, wo er mit Hardware gelöst werden kann.
Parallelverarbeitung ist im Vergleich dazu ein Gerät in Bezug auf Software. Beim Lernen von Bildern wird nur der Pfad zum Bild in die Lehrerdaten geschrieben. Daher ist es notwendig, die Bilder zum Zeitpunkt des Lernens zu lesen. Wenn Sie dies jedoch in der Reihenfolge von oben tun, wird das langsame Lernen noch langsamer, sodass die Bilder im Mini-Batch (Sammlung von Daten, die sofort trainiert werden sollen) parallel sind Es ist notwendig, wie Lesen mit zu entwickeln. Da "Multiprocessing" in Python verfügbar ist und "asyncio" ab 3 verfügbar ist, parallelisieren Sie, wo es mit diesen Modulen parallelisiert werden kann.
Überwachung
Während des Lernens müssen Sie sehen, ob Sie richtig lernen. Notieren Sie den Fehler und die Genauigkeit für jede festgelegte Lernmenge (1 Charge / Epoche usw.). Es ist auch wichtig, das Modell unterwegs zu speichern. Wenn Sie nur auf der Konsole ausgeben, bleibt im Falle einer Unterbrechung oder eines Blitzschlags nichts mehr übrig. Es wird daher empfohlen, in einer Protokolldatei, Modelldatei usw. aufzuzeichnen, die ohnehin auf der Festplatte verbleibt. ..
Das Beispiel von Chainer ist eine gute Referenz für die Implementierung eines bestimmten Lernskripts.
chainer/examples/imagenet/train_imagenet.py
Da async / await in Python einfacher zu schreiben ist, denke ich, dass Multiprocessing in Python3 etwas einfacher zu schreiben sein wird. Ich habe Python3 für das Tool verwendet, das ich dieses Mal erstellt habe (aber es gibt noch keine Protokollierung ...).
mlimages/mlimages/training.py/generate_batches
Damit ist die Erläuterung aller Punkte abgeschlossen. Abschließend werde ich ein Skript einfügen, das die Datenerfassung, die Erstellung von Lehrerdaten und das Lernen als Referenz zusammenfasst. AlexNet wird wie gewohnt für das Modell verwendet.
mlimages/examples/chainer_alex.py
Ich hoffe, es wird hilfreich sein, wenn Sie tatsächlich lernen. Die Genauigkeit dieses Skripts verbesserte sich auf der CPU auch nach 2 Tagen überhaupt nicht, aber wenn es auf der GPU berechnet wurde, erreichte es innerhalb weniger Stunden eine Genauigkeit von 50-60%. Im tatsächlichen Modell erhöht sich im Gegensatz zum Beispiel die Genauigkeit beim Betrachten nicht, und es gibt keine Garantie. Mir war sehr bewusst, dass der Beitrag der Geschwindigkeit beim Auffrischen auf der Grundlage einer legitimen Bewertung des Modells immer noch von Bedeutung ist.
Recommended Posts