[PYTHON] Was ist das Convolutional Neural Network?
In der Welt des maschinellen Lernens ist das Convolutional Neural Network (CNN) eine Selbstverständlichkeit, wenn es um Bilder geht, und Kagawa, wenn es um Udon geht. Es gibt jedoch überraschend wenige Erklärungen darüber, was das CNN ist.
Daher möchte ich in diesem Artikel den Mechanismus und die Vorzüge von CNN erläutern.
Wie in den Referenzen beschrieben, basiert der Inhalt der Erklärung auf Stanfords CNN-Kurs. In diesem Kurs wird von Neural Network über CNN bis zur Implementierung durch Tensorflow erläutert. Wenn Sie also interessiert sind, lesen Sie bitte auch dies.
Was ist ein Faltungs-Neuronales Netz?
Wie der Name schon sagt, ist CNN ein normales neuronales Netzwerk mit der Hinzufügung von Faltung. Hier werde ich erklären, worum es bei Faltung und Faltung geht und warum sie für die Bilderkennung wirksam sind.
Betrachten Sie als einfache Aufgabe die Aufgabe, festzustellen, ob die geschriebene Zahl ○ oder × ist. Das Folgende ist ein Beispiel für die Verwendung eines normalen neuronalen Netzwerks.

Stellen Sie sich ein Pixel im Bild als eine Eingabe vor. Bei einem 10x10-Bild ist die Eingabe ein Vektor der Größe 100 (beachten Sie, dass dies für die RGB-Darstellung x3 ist).
In der Abbildung wird der schwarze Teil des Randes des Kreises als Eingabe angezeigt. Wenn Sie sich dies jedoch ansehen, können Sie sehen, dass die Beurteilung stark beeinträchtigt wird, wenn die Position leicht abweicht. Dies liegt daran, dass die Eingabeinformationen ebenfalls falsch ausgerichtet und erkannt werden, wenn sich die Position oder Form geringfügig ändert (siehe Abbildung unten).
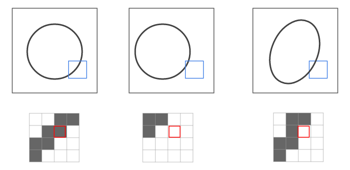
Die Innenseite des blauen Quadrats in der Abbildung ist jedoch tendenziell "schwarz von rechts oben nach links unten". Mit anderen Worten, wenn Sie anstelle von 1 Pixel eine bestimmte Fläche gleichzeitig eingeben können, können Sie anscheinend eine genauere Beurteilung vornehmen.
CNN ist die Verwirklichung dieser Idee.
Wie in der folgenden Abbildung gezeigt, wird ein kleiner Bereich, der als Filter bezeichnet wird (4x4-Bereich mit einem roten Rahmen in der folgenden Abbildung), auf dem Bild aufgenommen und als eine Merkmalsgröße komprimiert (= gefaltet).

Dieser Vorgang wird wiederholt, während der Bereich verschoben wird. Das Ergebnis ist eine Faltungsebene, eine Ebene, die durch Falten der Informationen im Filter erstellt wird.

Wenn das obige neuronale Netzwerkdiagramm in CNN konvertiert wird, sieht das Bild wie folgt aus.

Der Prozess des "Faltens" unter Verwendung dieses Filters ist speziell die Multiplikation und das innere Produkt zwischen dem "Vektor des Bildes im Filter" und dem "zum Falten verwendeten Vektor". Im Folgenden wird ein 5x5x3-Filter auf ein 32x32x3-Bild (32x32-RGB-Bild) angewendet.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p13
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p13
Dadurch wird schließlich eine 28 x 28 x 1-Ebene erstellt (wenn die Folienbreite 1 beträgt).
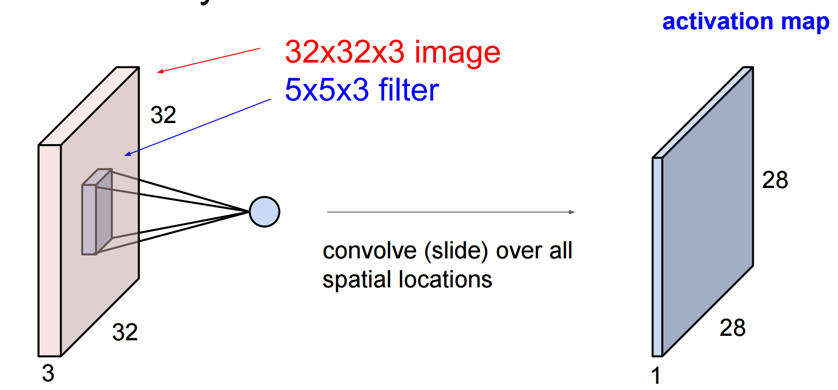 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p14
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p14
Wenn Sie die Filtertypen erhöhen, wird die Faltungsschicht entsprechend erhöht. Unten werden 6 Ebenen mit 6 Filtern erstellt.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p16
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p16
Man kann sagen, dass dies nur ein "neues Bild" durch Falten erzeugt. Wie bei einem normalen neuronalen Netzwerk ist die auf diese Weise erzeugte Faltungsschicht durch eine Aktivierungsfunktion verbunden, um ein Faltungs-Neuronales Netzwerk zu bilden (ReLU wird häufig als Aktivierungsfunktion verwendet).
Ich werde die Geschichte bisher zusammenfassen.
- CNN ist ein neuronales Netzwerk, das eine Faltungsschicht einführt, die durch Falten von Informationen über den Bereich innerhalb des Filters erstellt wird.
- Die Faltungsebene wird durch Anwenden während des Verschiebens des Filters erstellt, und es werden so viele Filter wie erstellt. Ein Netzwerk wird aufgebaut, indem diese gestapelt und mit einer Aktivierungsfunktion (ReLU usw.) verbunden werden.
- Das Falten ermöglicht das Extrahieren von Merkmalen basierend auf Bereichen anstelle von Punkten, wodurch es robust gegenüber Bildbewegungen und Verformungen ist. Darüber hinaus ist es möglich, Merkmale wie Kanten zu extrahieren, die nur anhand des Bereichs verstanden werden können.
Dieses CNN zeichnet sich durch Filtereinstellungen und Schichtung aus.
Filtereinstellungen
Die folgenden vier Parameter müssen für den zur Faltung verwendeten Filter eingestellt werden.
- Anzahl der Filter (K): Die Anzahl der zu verwendenden Filter. Es wird ungefähr eine Potenz von 2 genommen (32, 64, 128 ...)
- Filtergröße (F): Die Größe des verwendeten Filters
- Filterbewegungsbreite (S): Breite zum Verschieben des Filters
- Auffüllen (P): Wie viel soll der Randbereich des Bildes ausfüllen?
Beim Auffüllen wird der Randbereich des Bildes wie unten gezeigt mit 0 gefüllt.
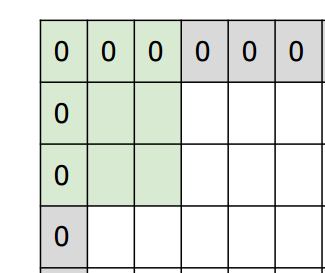 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p35
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p35
Der Grund dafür ist, dass das normale Falten die Häufigkeit des Faltens des Randbereichs im Vergleich zu anderen Bereichen verringert. Wenn Sie die Bildränder auf diese Weise mit 0 füllen und von dort aus filtern, werden die Ränder auf die gleiche Weise wie in anderen Bereichen reflektiert.
Darüber hinaus müssen Größe und Bewegungsbreite des Filters so angepasst werden, dass sie der Bildgröße entsprechen. Bitte beachten Sie, dass Sie die Größe und Bewegungsbreite des Filters, der über das Bild hinausgeht, nicht wie unten gezeigt einstellen können.

Aus den Werten dieser Parameter kann die Größe der Faltungsschicht berechnet werden. Angenommen, Sie möchten einen 5x5x3-Filter auf ein 32x32x3-Bild mit einer Bewegungsbreite von 1 und einem Abstand von 2 anwenden. Wenn das Auffüllen hinzugefügt wird, beträgt die Größe des Bildes zunächst 32 + 2 * 2 = 36. Wenn Sie von hier aus einen Filter mit einer Breite von 5 und einer Bewegungsbreite von 1 nehmen, ist dies 32 mit 36-5 + 1. Sie erhalten also eine 32x32x3-Ebene.
Diese Parameter müssen auch festgelegt werden, wenn Sie eine Bibliothek wie Caffe verwenden. Daher sollten Sie deren Bedeutung und Berechnung der Größe berücksichtigen.
Schichtstruktur
Es gibt drei Arten von Schichten in CNN, einschließlich der Faltungsschicht.
- Faltungsebene: Eine Ebene, die Features faltet
- Pooling-Ebene: Eine Ebene, um die Ebene zu reduzieren und die Handhabung zu vereinfachen
- Vollständig verbundene Ebene: Die Ebene, die die endgültige Beurteilung anhand der Merkmalsmenge vornimmt
Das Bild ist wie folgt.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p22
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p22
Ich werde andere Schichten als die Faltungsschicht erklären. Die erste ist die Pooling-Ebene, die das Bild komprimiert. Es hat den Vorteil, dass die Bildgröße komprimiert und in späteren Ebenen einfacher zu handhaben ist.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p54
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p54
Es gibt Max Pooling als Mittel, um dieses Pooling durchzuführen. Dies ist eine Komprimierungsmethode, bei der der Maximalwert in jedem Bereich verwendet wird.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p55
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p55
Eine vollständig verbundene Ebene ist eine Ebene, die alle Elemente der vorherigen Ebene verbindet. Es wird hauptsächlich in der Schicht verwendet, die das endgültige Urteil trifft. Durch die Kombination dieser Schichten erstellen wir eine CNN.
Entwicklung von CNN
Die Genauigkeit von CNN hat sich im Laufe der Jahre verbessert, aber die folgenden Merkmale sind in neueren Konfigurationen zu sehen.
- Verkleinern Sie den Filter und vertiefen Sie die Hierarchie
- Beseitigen Sie Pooling- und FC-Ebenen
In der folgenden Abbildung sehen Sie, dass die Ebenen mit zunehmender Genauigkeit von Jahr zu Jahr tiefer werden.
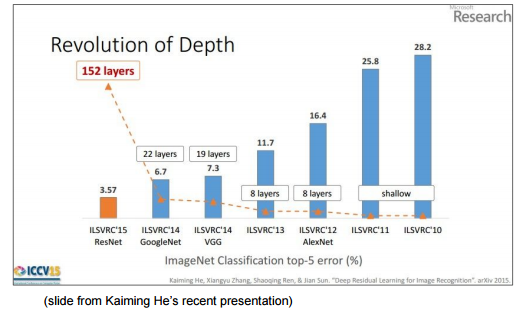 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p78
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p78
In Bezug auf die Tiefe der Ebene ist Folgendes möglicherweise leichter zu verstehen. Im Vergleich zu den 8 Schichten von AlexNet, die 2012 erschienen sind, hat sich ResNet, das 2015 die Krone gewann, deutlich auf 152 Schichten erhöht.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p80
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p80
Es scheint, dass es viele der folgenden Muster als Grundkonfiguration von CNN gibt.
(Convolution * N + (Pooling)) * M + Fully Connected * K
** N ** ist ungefähr ~ 5 und ** M ** Schichten sind geschichtet (M ist ein ziemlich großer Wert), und schließlich ist FC zur Beurteilung ** K ** Schicht (0 <= K <=). 2) Es ist wie beim Einrichten (manchmal füge ich mithilfe der SoftMax-Funktion eine Ebene hinzu, um das Klassifizierungsproblem zu lösen). ReLU wird häufig als Aktivierungsfunktion verwendet.
Obwohl CNN sehr kompliziert aussieht, kann es durch Backpropagation wie Neural Network trainiert werden, da es nicht die Grundlagen des Neural Network entfernt, das sich mit dem Gewicht ausbreitet. Ich denke, die Flexibilität hier ist auch der Reiz von Neural Network.
CNN-Anwendungsbeispiel
CNN wurde nicht nur auf das Originalbild, sondern auch auf andere Aufgaben angewendet. Dieses Anwendungsbeispiel ist in der folgenden Folie sehr gut organisiert. Wenn Sie also interessiert sind, schauen Sie bitte.
Trends bei Faltungs-Neuronalen Netzen
Mit anderen Worten, ein CNN, der ein Bild identifizieren kann, kann die Eigenschaften des Bildes gut erfassen. Mit anderen Worten kann das CNN ohne die Diskriminanzschicht als der Prozess des Transformierens des Eingabebildes in einen Vektor angesehen werden, der seine Merkmale (unterscheidbar) gut darstellt. Einige der Anwendungsbeispiele verwenden diese Funktion, und insbesondere das Anwendungsbeispiel zum Hinzufügen einer Beschriftung zum Bild kombiniert die Funktionsmenge des aus CNN extrahierten Bildes und die Textinformationen.
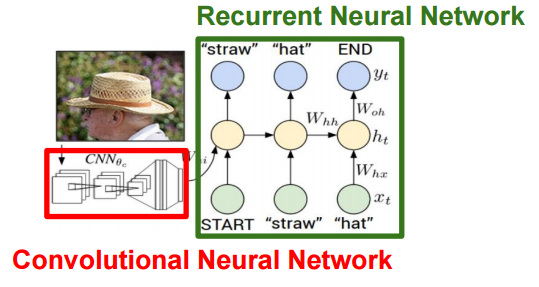
Ich denke, dass in Zukunft verschiedene Anwendungsbeispiele herauskommen werden. Wenn Sie das aktuelle Framework für maschinelles Lernen verwenden, können Sie es selbst ausprobieren. Ich hoffe, dieser Artikel wird Ihnen helfen.
Verweise
Recommended Posts