[PYTHON] Was ist Hyperopt?
Fassen Sie die Logik-, Verwendungs- und Überprüfungsergebnisse von hyperopt zusammen
Einführung
Beim Erstellen eines Modells mit maschinellem Lernen ist eine Optimierung der Hyperparameter erforderlich.
Es wäre schön, wenn es durch Rastersuche gründlich untersucht werden könnte, aber wenn die Anzahl der Parameter wie bei DNN groß ist, ist der Rechenaufwand lächerlich.
Es ist möglich, den Rechenaufwand durch Suchen nach Parametern mit einer zufälligen Suche zu reduzieren, aber die Wahrscheinlichkeit, den optimalen Parameter zu finden, ist gering.
Daher gibt es eine Methode namens Sequential Model-based Global Optimization (SMBO), die effizient nach guten Parametern sucht.
In Python gibt es eine Bibliothek namens Hyperopt für die Verwendung von SMBO (es scheint, dass Kaggler es oft verwendet ...).
Wenn Sie mit Hyperopt suchen, finden Sie Artikel, in denen die Verwendung erläutert wird. Es gab jedoch nicht viele Artikel, in denen die interne Logik und Überprüfung erläutert wurde.
Daher werden wir in diesem Artikel nicht nur die Verwendung von Hyperopt zusammenfassen, sondern auch die internen Logik- und Verifizierungsergebnisse. Wenn Sie es nur verwenden möchten, überspringen Sie die erste Hälfte.
Hyperopt-Logik
Was ist Hyperopt
hyperopt ist eine Python-Bibliothek, die effizient nach Parametern von Modellen für maschinelles Lernen sucht.
Unter SMBO implementiert hyperopt eine Logik namens Tree-Structured Parzen Estimator Approach (TPE).
Daher werden wir in diesem Kapitel nach der Erläuterung des Umrisses von SMBO kurz die Berechnungsmethode von TPE erläutern.
Auf die folgenden zwei Artikel wurde verwiesen.
' % 3A% 2F% 2Fwww.lri.fr% 2F ~ kegl% 2Fresearch% 2FPDFs% 2FBeBaBeKe11.pdf & usg = AFQjCNF60kZOogiGZmIBfsuY1Jai4SIVcA]) (TPE-Papier)
- http://neupy.com/2016/12/17/hyperparameter_optimization_for_neural_networks.html
Letzteres ist insbesondere ein englischer Artikel, aber ich empfehle ihn, weil er SMBO-> Gauß-Prozess-> TPE auf leicht verständliche Weise mit Zahlen erklärt.
Sequential Model-based Global Optimization(SMBO)
SMBO ist eines der Frameworks für die effiziente Suche nach Modellparametern.
Der Ablauf des SMBO-Algorithmus ist wie folgt.
| Algorithm: SMBO |
|---|
 |
[Algorithmen zur Hyperparameteroptimierung](https://www.google.co.jp/url?sa=t&rct=j&q=1esrc=s&source=web&cd=3&cad=rja&uact=8&ved=0ahUKEwiqh8GBhffVAhWHiLwKHXG Von .lri.fr% 2F ~ kegl% 2Fresearch% 2FPDFs% 2FBeBaBeKe11.pdf & usg = AFQjCNF60kZOogiGZmIBfsuY1Jai4SIVcA])
Erklärung der Symbole
- $ x $: Parameter
- $ f (x) $: Verlust bei Verwendung des Parameters $ x $
- $ H $: Satz von Parameter $ x $ und Modellverlust $ f (x) $ bei Verwendung dieses Parameters
- $ T $: Anzahl der wiederholten Versuche
- $ M $: Eine Funktion, die den Parameter $ x $ verwendet und den Verlust $ f (x) $ vorhersagt, wenn dieser Parameter verwendet wird.
- $ S $: Eine Funktion, die den erwarteten Wert berechnet, wie viel Verlust wahrscheinlich reduziert wird, wenn ein bestimmter Parameter $ x $ verwendet wird.
Die Punkte von SMBO befinden sich in der Funktion $ M $ und der Funktion $ S $.
Die Funktion $ M $ sagt voraus, wie viel Verlust bei Verwendung eines Parameters $ x $ wahrscheinlich ist. Mit dieser Funktion $ M $ können Sie vorhersagen, wie viel Verlust Sie wahrscheinlich verlieren werden, ohne sich die Mühe machen zu müssen, das Modell mit $ x $ zu schätzen. $ M $ kann beispielsweise ein Modell wie die lineare Regression sein, am häufigsten wird jedoch der Gauß-Prozess verwendet, und Hyperopt verwendet TPE.
Die Funktion $ S $ berechnet den erwarteten Wert, wie viel Verlust wahrscheinlich reduziert wird, wenn der Parameter $ x $ verwendet wird.
Angenommen, Sie verwenden einen Parameter $ x $ und sagen die Genauigkeit mit der Funktion $ M $ voraus. Sie erhalten eine 50% ige Chance, 0,3 zu verlieren, und eine 50% ige Chance, 0,1 zu verlieren. In diesem Fall berechnet die Funktion $ S $, dass der erwartete Verlust bei Verwendung des Parameters $ x $ $ 0,3 * 0,5 + 0,1 * 0,5 = 0,2 $ beträgt.
Mit der Funktion $ S $ können Sie den Parameter $ x $ finden, der Verluste am wahrscheinlichsten reduziert.
Berechnen Sie dann mit dem geschätzten Parameter $ x $ das Modell und notieren Sie, wie viel Verlust Sie tatsächlich gemacht haben. Zusätzlich aktualisieren wir basierend auf diesem Parameter $ x $ und dem Verlust $ f (x) $ die Verlustvorhersagefunktion $ M $.
Der Umriss von SMBO besteht darin, diese Berechnung $ T $ mal zu wiederholen und den Parameter $ x $ mit dem niedrigsten Verlust und seinem Verlust zurückzugeben.
Tree-structured Parzen Estimator Approach(TPE)
TPE ist eine Neuheit des Originalpapiers von hyperopt, einer Methode zur Berechnung der im vorherigen Abschnitt beschriebenen Funktionen $ M $ und $ S $.
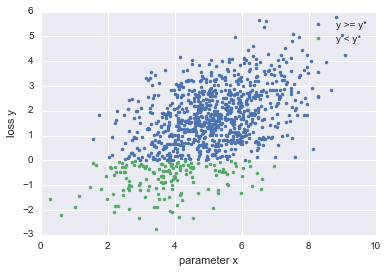
In TPE wird zunächst basierend auf dem Wert des Parameters $ x $ die Funktion $ M $, die die Wahrscheinlichkeit berechnet, dass der Verlust $ y $ beträgt, wie folgt berechnet.
p(x|y) = \left\{
\begin{array}{ll}
l(x) & (y \lt y^*) \\
g(x) & (y \geq y^*)
\end{array}
\right.
$ y ^ * $ ist der Schwellenwert, der die Verteilung $ l (x) $ für Parameter berechnet, die kleiner als ein Verlust sind, und die Verteilung $ g (x) $ für Parameter, die größer als ein Verlust sind.
Wenn Sie das Bild der Funktion $ M $ erklären, sieht es wie in der folgenden Abbildung aus
| Parameter |
|
|---|---|
 |
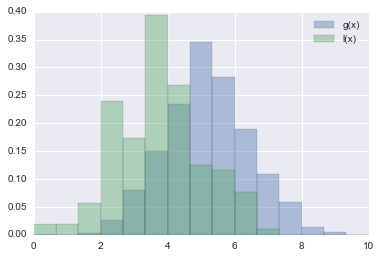 |
Durch Definieren der Funktion $ M $ auf diese Weise wird die Verteilung des Parameters $ x $, wenn der Verlust kleiner als $ y ^ \ * $ ist, und die Verteilung des Parameters $ x $, wenn der Verlust größer als $ y ^ \ * $ ist Kann berechnet werden.
In TPE wird basierend auf $ l (x) $ und $ g (x) $ die Funktion $ S $, die den erwarteten Verlust berechnet, wenn der Parameter $ x $ ausgewählt wird, wie folgt definiert.
EI_{y^*}(x) = (\gamma + \frac{g(x)}{l(x)}(1 - \gamma))^{-1}
$ \ Gamma $ ist jedoch ein Parameter, der bestimmt, wie viel Prozent der Daten als Schwellenwert $ y ^ \ * $ festgelegt werden.
Um diesen Wert zu erhöhen, machen Sie $ g (x) $ so klein wie möglich und $ l (x) $ so groß wie möglich. Mit anderen Worten, die Funktion $ S $ wählt den Parameter $ x $ aus, der mit höherer Wahrscheinlichkeit weniger als den Schwellenwert $ y ^ \ * $ verliert.
Auf diese Weise sucht TPE nach dem Parameter $ x $, um den nächsten Verlust zu berechnen.
Hinweis
In diesem Kapitel habe ich die Logik von Hyperopt vereinfacht. Es gibt also einige irreführende Teile. Zum Beispiel ist TPE eine Methode zur Berechnung von $ l (x) $ und $ g (x) $, um genau zu sein. Wenn Sie die genaue Logik kennen möchten, wenden Sie sich bitte an [Originalarbeit](https://www.google.co.jp/url?sa=t&rct=j&q=1esrc=s&source=web&cd=3&cad=rja&uact=8&ved=0ahUKEwiqh8GBhffVAhWHiLWHiLWHiLWHiLWHiLWHiLWHiLWHiLWHiLWHiLWHlHHHHHHHHHHHh Bitte lesen Sie% 3A% 2F% 2Fwww.lri.fr% 2F ~ kegl% 2Fresearch% 2FPDFs% 2FBeBaBeKe11.pdf & usg = AFQjCNF60kZOogiGZmIBfsuY1Jai4SIVcA).
Wie benutzt man Hyperopt
In diesem Kapitel wird beschrieben, wie Sie Hyperopt mit Python verwenden. Ich habe auf das [offizielle Tutorial] verwiesen (https://github.com/hyperopt/hyperopt/wiki/FMin).
Importieren Sie zunächst die vier Module hp, tpe, Trials und fmin aus hyperopt.
from hyperopt import hp, tpe, Trials, fmin
Die Beschreibung jedes Moduls ist unten zusammengefasst.
- hp: Wird verwendet, um zu bestimmen, aus welcher Verteilung die Parameter abgetastet werden
- tpe: Wird verwendet, um zufällig zu suchen oder zu entscheiden, ob die tpe-Logik verwendet werden soll
- Versuche: Erstellen Sie eine Instanz, um den Prozess der Hyperopt-Berechnung aufzuzeichnen
- fmin: Die Funktion, die tatsächlich die Berechnung von Hyperopt durchführt
Hyperopt verwenden
- Nach welchem Parameter gesucht werden soll
- Welcher Wert muss minimiert werden?
Muss im Voraus definiert werden.
Um dies anhand eines konkreten Beispiels zu erklären, nehmen wir an, dass diesmal SVM verwendet wird.
Definition der zu suchenden Parameter
Wenn in SVM die Parameter, die Sie einstellen möchten, beispielsweise $ C $, $ gamma $, $ kernel $ sind, definieren Sie zuerst die zu durchsuchenden Parameter im Wörterbuchtyp oder Listentyp wie folgt.
hyperopt_parameters = {
'C': hp.uniform('C', 0, 2),
'gamma': hp.loguniform('gamma', -8, 2),
'kernel': hp.choice('kernel', ['rbf', 'poly', 'sigmoid'])
}
hp.uniform ist eine Funktion zum Abtasten von Parametern aus einer gleichmäßigen Verteilung und gibt den Parameternamen min, max an.
hp.loguniform sucht nach Parametern im Bereich $ exp (min) $ bis $ exp (max) $. Daher ist für Parameter wie $ C $ und $ gamma $ von SVM, die für die Suche im Bereich von $ 10 ^ {-5} $ bis $ 10 ^ {2} $ geeignet sind, hp.loguniform Es ist besser, zu verwenden (wir werden dies in einem späteren Kapitel überprüfen).
hp.choice kann Kategorien probieren. Es ist eine gute Idee, diese Funktion bei der Auswahl eines SVM-Kernels zu verwenden.
Sie können eine andere als die hier gezeigte Verteilung angeben. Weitere Informationen finden Sie im offiziellen Tutorial (https://github.com/hyperopt/hyperopt/wiki/FMin).
Definition des zu minimierenden Wertes
In Hyperopt müssen Sie definieren, was als Funktion minimiert werden soll.
Für SVM ist die Funktion wie folgt definiert.
def objective(args):
#Modellinstanziierung
classifier = SVC(**args)
#Training eines Modells anhand von Zugdaten
classifier.fit(x_train, y_train)
#Etikettenvorhersage unter Verwendung von Validierungsdaten
predicts = classifier.predict(x_test)
#Berechnen Sie micro f1 mit dem Predictive Label und dem korrekten Label
f1 = f1_score(y_test, predicts, average='micro')
#Dieses Mal möchte ich das Mikro f1 maximieren-Mit 1 multiplizieren, um zu minimieren
return -1*f1
Das Argument args enthält die im vorherigen Abschnitt definierten hyperopt_parameters.
In diesem Beispiel legen wir zuerst die definierten Parameter fest, um eine SVM-Instanz zu erstellen.
Als nächstes werden wir das Modell anhand der Zugdaten trainieren.
Verwenden Sie das trainierte Modell, um die Bezeichnung der Validierungsdaten vorherzusagen.
Dieses Mal besteht der Zweck darin, den Parameter zu finden, der das Mikro f1 maximiert, und das Mikro f1 der Validierungsdaten wird berechnet.
Es gibt das zuletzt berechnete Mikro f1 zurück. Beachten Sie jedoch, dass Hyperopt nur die Minimierung unterstützt. Wenn Sie also den Parameter finden, der den Wert wie in dieser Zeit maximiert, multiplizieren Sie ihn mit -1 und geben Sie ihn zurück.
Hyperopt-Berechnung
Suchen Sie nach Parametern mit den vordefinierten "hyperopt_parameters" und "def object".
Suchen Sie nach Parametern, indem Sie wie folgt vorgehen.
#Anzahl der Iterationen
max_evals = 200
#Eine Instanz, die den Prozess des Versuchs aufzeichnet
trials = Trials()
best = fmin(
#Eine Funktion, die den zu minimierenden Wert definiert
objective,
#Diktat oder Liste der zu suchenden Parameter
hyperopt_parameters,
#Welche Logik zu verwenden ist, im Grunde tpe.schlage vor ok
algo=tpe.suggest,
max_evals=max_evals,
trials=trials,
#Testprozess ausgeben
verbose=1
)
Durch Übergeben von "hyperopt_parameters" und "def object" an die Funktion "fmin" werden die Parameter durchsucht, aber zusätzlich die Instanz "Versuche" zum Aufzeichnen des Berechnungsergebnisses, wie oft gesucht werden soll Es gibt auch die anzugebenden "max_evals" an.
Auf diese Weise werden die Parameter berechnet, die das Ziel minimieren.
Im obigen Beispiel sind die Inhalte von best wie folgt.
$ best
>> {'C': 1.61749553623185, 'gamma': 0.23056607283675354, 'kernel': 0}
Verwenden Sie außerdem Versuche, um den tatsächlich berechneten Micro-F1-Wert und den Wert des von Ihnen getesteten Parameters zu überprüfen.
$ trials.best_trial['result']
>> {'loss': -0.9698492462311558, 'status': 'ok'}
$ trials.losses()
>> [-0.6700167504187605, -0.9095477386934674, -0.949748743718593, ...]
$ trials.vals['C']
>> [2.085990722493943, 0.00269991295234128, 0.046611673333310344, ...]
Überprüfung der Hyperopt-Genauigkeit
Die diesmal überprüften Inhalte sind hauptsächlich die folgenden zwei.
- Was ist besser zu verwenden, "hp.loguniform" oder "hp.uniform"
- Ist Hyperopt genauer als die Zufallssuche?
Der verwendete Datensatz besteht aus Ziffern (64-dimensionale handgeschriebene Ziffern) in sklearn. 1200 Stück wurden als Zugdaten verwendet, der Rest waren Validierungsdaten.
Für den Klassifikator haben wir den SVC von sklearn verwendet. Die gesuchten Parameter sind $ C $, $ gamma $ und $ kernel $, die in den konkreten Beispielen im vorherigen Kapitel gezeigt wurden.
Der zur Überprüfung verwendete Code lautet https://github.com/kenchin110100/machine_learning/blob/master/sampleHyperOpt.ipynb Es ist in.
LogUniform vs Uniform
Im vorigen Kapitel habe ich geschrieben, dass es im Fall von SVC besser ist, "hp.loguniform" zu verwenden, aber ich habe überprüft, ob dies wirklich der Fall ist.
Als Verifizierungsmethode wurden LogUniform und Uniform jeweils 100 Mal nach 50 Iterationen durchsucht und die beste geschätzte Verteilung der Mikro-f1-Werte verglichen.
Jeder `hyperopt_parameters wurde wie folgt eingestellt.
hyperopt_parameters_loguniform = {
'C': hp.loguniform('C', -8, 2),
'gamma': hp.loguniform('gamma', -8, 2),
'kernel': hp.choice('kernel', ['rbf', 'poly', 'sigmoid'])
}
hyperopt_parameters_uniform = {
'C': hp.uniform('C', 0, 10),
'gamma': hp.uniform('gamma', 0, 10),
'kernel': hp.choice('kernel', ['rbf', 'poly', 'sigmoid'])
}
Die Ergebnisse des Vergleichs sind in der folgenden Abbildung zusammengefasst.
| LogUniform vs Uniform |
|---|
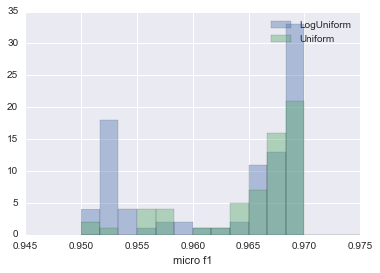 |
Das Histgramm des Log Unifrom-Ergebnisses ist blau und das Histgramm des Uniform-Ergebnisses ist grün. Obwohl LogUniform mit größerer Wahrscheinlichkeit ein niedrigeres Mikro-F1 schätzt, hat es die Häufigkeit, mit der es 0,96985, das diesmal größte Mikro-F1-Haus, aufzeichnete, fast verdoppelt.
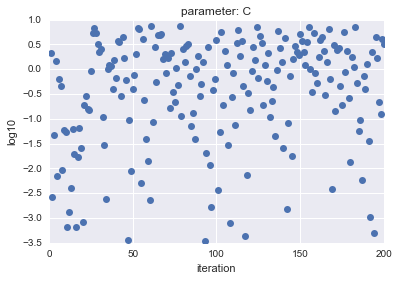
Im Fall von LogUniform werden im Fall von Uniform die Stichprobenparameter $ C $ und $ gamma $ aufgezeichnet und das Ergebnis ist wie folgt.
- Für Log Uniform
| parameter |
parameter |
|---|---|
 |
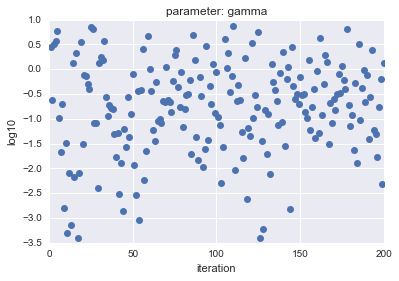 |
- Für Uniform
| parameter |
parameter |
|---|---|
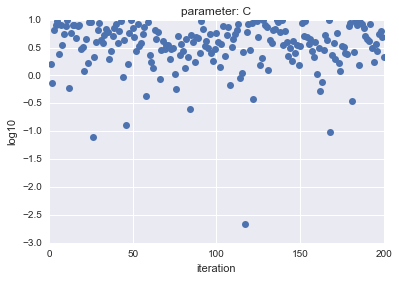 |
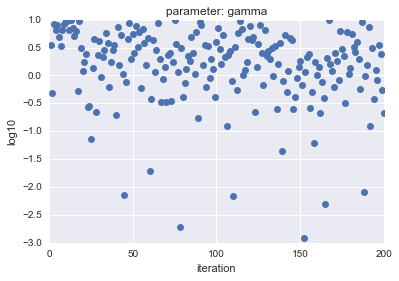 |
Die horizontale Achse zeigt die Iteration und die vertikale Achse zeigt die logarithmischen Werte von $ C $ und $ gamma $.
Wie Sie sehen können, hat LogUniform eine gleichmäßigere Stichprobe aus dem Ganzen. Wenn Sie in der Lage sind, gleichmäßig aus dem Ganzen abzutasten, ist es wahrscheinlicher, dass Sie nach genaueren Parametern suchen können (obwohl es wahrscheinlicher ist, dass sie niedriger sind ...).
HyperOpt vs RandomSearch
Als nächstes untersuchten wir, in welchem der Fälle, in denen HyperOpt verwendet und die Parameter von RandomSearch geschätzt wurden, die Parameter mit größerer Wahrscheinlichkeit mit höherer Genauigkeit geschätzt werden konnten.
Der verwendete Datensatz und die Versuchsbedingungen sind dieselben wie im vorherigen Abschnitt. Wir haben jeweils 100-mal mit HyperOpt und RandomSearch geschätzt und die Häufigkeit der besten erhaltenen Micro-F1-Werte verglichen.
Die Ergebnisse des Vergleichs sind in der folgenden Abbildung zusammengefasst.
| HyperOpt vs RansomSearch |
|---|
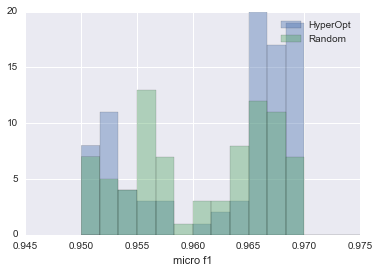 |
Das blaue ist HyperOpt und das grüne ist Random Search. Wie Sie sehen können, ist HyperOpt mehr als doppelt so wahrscheinlich in der Lage, Parameter zu schätzen, die einen Micro-F1-Wert von 0,965 oder höher erzeugen.
Dies zeigt, dass es besser ist, HyperOpt als RandomSearch zu verwenden.
Zusätzliches Experiment
Obwohl HyperOpt genauer ist als RandomSearch, dauert die Berechnung länger, nicht wahr? Um die Frage zu überprüfen, haben wir die Berechnungszeit verglichen. Wir haben jeweils 200 Iterationen gedreht und die benötigte Zeit gemessen.
#HyperOpt-Berechnungszeit
%timeit hyperopt_search(200)
>> 1 loop, best of 3: 32.1 s per loop
#Berechnungszeit für die zufällige Suche
%timeit random_search(200)
>> 1 loop, best of 3: 46 s per loop
Nun, Hyperopt ist eher schneller ... Da RandomSearch von mir selbst implementiert wurde, liegt möglicherweise ein Problem mit meiner Codierung vor, aber es scheint, dass hyperopt tatsächlich codiert ist, um automatisch eine verteilte Verarbeitung durchzuführen. Selbst wenn Sie Hyperopt verwenden, können Sie anscheinend mit der gleichen Geschwindigkeit oder schneller als mit der Zufallssuche rechnen.
Zusammenfassung
Dieses Mal haben wir die Logik, Verwendung und Genauigkeit von Hyperopt of Python überprüft.
Schließlich scheint es besser zu sein, Hyperopt zu verwenden, als die Parameter mit der Zufallssuche abzustimmen.
Ich habe es wie das stärkste TPE geschrieben, aber es scheint ein Problem mit TPE zu geben (Ignorieren der Abhängigkeit zwischen Variablen usw.).
Trotzdem hat hyperopt den Vorteil, dass es zusammen mit sklearn und xgboost verwendet werden kann, daher werde ich es von nun an häufig verwenden.
Recommended Posts