[PYTHON] Verwendung von xgboost: Mehrklassenklassifizierung mit Irisdaten
** xgboost ** ist eine Bibliothek, die ** GBDT ** verarbeitet, eines der Entscheidungsbaummodelle. Wir haben die Schritte zur Installation und Verwendung zusammengefasst. Es kann in verschiedenen Sprachen verwendet werden, beschreibt jedoch die Verwendung in Python.
Was ist GBDT?
- Eine Art Entscheidungsbaummodell --Steigungsbaum
- Gradient Boosting Decision Tree
Random Forest ist für dasselbe Entscheidungsbaummodell bekannt, aber der folgende Artikel fasst die Unterschiede kurz zusammen. [Maschinelles Lernen] Ich habe versucht, die Unterschiede zwischen den Entscheidungsbaummodellen zusammenzufassen - Qiita
Funktionen von GBDT
- Einfach, um eine gute Genauigkeit zu erhalten
- Kann fehlende Werte verarbeiten --Numerische Daten können verarbeitet werden
Es ist im maschinellen Lernwettbewerb Kaggle beliebt, weil es einfach zu bedienen und genau ist.
[1] Verwendung
Ich habe Irisdaten (Ayame-Sortendaten) verwendet, die zu den Scikit-Lerndatensätzen gehören. Das Betriebssystem ist Amazon Linux 2.
[1-1] Installation
Das von mir verwendete Amazon Linux 2 ist: Das Installationsverfahren für jede Umgebung ist offiziell aufgeführt. Installation Guide — xgboost 1.1.0-SNAPSHOT documentation
pip3 install xgboost
[1-2] Importieren
import xgboost as xgb
[1-3] Erfassung von Irisdaten
Es gibt keine besonderen Schritte. Holen Sie sich Irisdaten und erstellen Sie Pandas DataFrame und Series.
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_data = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_target = pd.Series(iris.target)
[1-4] Erfassung von Trainingsdaten und Testdaten
Auch hier gibt es keine speziellen Schritte, und das scicit-learn train_test_split teilt die Daten für Training und Test auf.
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(iris_data, iris_target, test_size=0.2, shuffle=True)
[1-5] In xgboost in Typ konvertieren
xgboost verwendet "DMatrix".
dtrain = xgb.DMatrix(train_x, label=train_y)
DMatrix kann aus numpys ndarray oder pandas``DataFrame` erstellt werden, sodass Sie keine Probleme beim Umgang mit den Daten haben.
Die Arten von Daten, die verarbeitet werden können, sind offiziell detailliert. Python Package Introduction — xgboost 1.1.0-SNAPSHOT documentation
[1-6] Parametereinstellungen
Stellen Sie verschiedene Parameter ein.
param = {'max_depth': 2, 'eta': 1, 'objective': 'multi:softmax', 'num_class': 3}
Die Bedeutung jedes Parameters ist wie folgt.
| Parametername | Bedeutung |
|---|---|
| max_depth | Maximale Tiefe des Baumes |
| eta | Lernrate |
| objective | Lernzweck |
| num_class | Anzahl der Klassen |
Geben Sie den Lernzweck (Rückgabe, Klassifizierung usw.) in "Ziel" an. Da es sich diesmal um eine Mehrklassenklassifikation handelt, wird 'multi: softmax' angegeben.
Details sind offiziell detailliert. XGBoost Parameters — xgboost 1.1.0-SNAPSHOT documentation
[1-7] Lernen
num_round ist die Anzahl der Lernvorgänge.
num_round = 10
bst = xgb.train(param, dtrain, num_round)
[1-8] Prognose
dtest = xgb.DMatrix(test_x)
pred = bst.predict(dtest)
[1-9] Bestätigung der Genauigkeit
Überprüfen Sie die Genauigkeitsrate mit berechnung_score von scikit-learn.
from sklearn.metrics import accuracy_score
score = accuracy_score(test_y, pred)
print('score:{0:.4f}'.format(score))
# 0.9667
[1-10] Visualisierung von Bedeutung
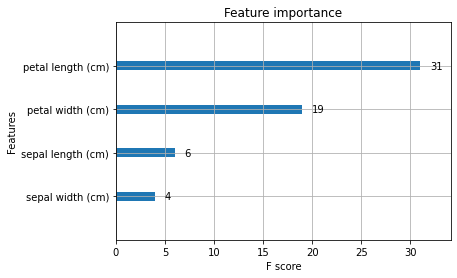
Visualisieren Sie, welche Funktionen zu den Vorhersageergebnissen beigetragen haben.
xgb.plot_importance(bst)
[2] Validierung und vorzeitiges Anhalten während des Lernens
Die Validierung während des Lernens anhand von Verifizierungsdaten und ein vorzeitiges Stoppen (Abbruch des Lernens) können problemlos durchgeführt werden.
[2-1] Datenteilung
Ein Teil der Trainingsdaten wird als Verifizierungsdaten verwendet.
train_x, valid_x, train_y, valid_y = train_test_split(train_x, train_y, test_size=0.2, shuffle=True)
[2-2] DMatrix erstellen
dtrain = xgb.DMatrix(train_x, label=train_y)
dvalid = xgb.DMatrix(valid_x, label=valid_y)
[2-3] Hinzufügen von Parametern
Add'eval_metric'to zum Parameter für die Validierung. Geben Sie für 'eval_metric' die Metrik an.
param = {'max_depth': 2, 'eta': 0.5, 'objective': 'multi:softmax', 'num_class': 3, 'eval_metric': 'mlogloss'}
[2-4] Lernen
Geben Sie die Daten an, die durch Validierung in evallist überwacht werden sollen. Geben Sie "eval" als Namen der Verifizierungsdaten und "train" als Namen der Trainingsdaten an.
Ich füge Early_stopping_rounds als Argument zu xgb.train hinzu. Early_stopping_rounds = 5 bedeutet, dass das Lernen unterbrochen wird, wenn sich der Bewertungsindex nicht fünfmal hintereinander verbessert.
evallist = [(dvalid, 'eval'), (dtrain, 'train')]
num_round = 10000
bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=5)
# [0] eval-mlogloss:0.61103 train-mlogloss:0.60698
# Multiple eval metrics have been passed: 'train-mlogloss' will be used for early stopping.
#
# Will train until train-mlogloss hasn't improved in 5 rounds.
# [1] eval-mlogloss:0.36291 train-mlogloss:0.35779
# [2] eval-mlogloss:0.22432 train-mlogloss:0.23488
#
#~ ~ ~ Unterwegs weggelassen ~ ~ ~
#
# Stopping. Best iteration:
# [1153] eval-mlogloss:0.00827 train-mlogloss:0.01863
[2-5] Bestätigung der Verifizierungsergebnisse
print('Best Score:{0:.4f}, Iteratin:{1:d}, Ntree_Limit:{2:d}'.format(
bst.best_score, bst.best_iteration, bst.best_ntree_limit))
# Best Score:0.0186, Iteratin:1153, Ntree_Limit:1154
[2-6] Prognose
Machen Sie Vorhersagen mit dem Modell mit den besten Überprüfungsergebnissen.
dtest = xgb.DMatrix(test_x)
pred = ypred = bst.predict(dtest, ntree_limit=bst.best_ntree_limit)
Am Ende
Da der DataFrame und die Serie von pandas verwendet werden können, scheint der Schwellenwert für diejenigen, die bisher maschinelles Lernen durchgeführt haben, niedrig zu sein.
Ich habe diesmal versucht, mehrere Klassen zu klassifizieren, aber es kann auch für die binäre Klassifizierung und Regression verwendet werden, sodass es in verschiedenen Situationen verwendet werden kann.
Recommended Posts