[PYTHON] Wie man x-means benutzt
k-bedeutet Systemübersicht
--k-means: Minimiert den quadratischen Fehler vom Schwerpunkt des Clusters. --k-Medoide: Führen Sie das EM-Verfahren so durch, dass die völlige Unähnlichkeit von den Cluster-Medoiden (die Punkte, die zum Cluster gehören und die totale Unähnlichkeit am kleinsten ist) minimiert wird. --x-means: Steuert die Clusterteilung basierend auf BIC. --g-menas: Kontrollclusterteilung durch Anderson-Lieblingstest, vorausgesetzt, die Daten basieren auf einer Normalverteilung. --gx-means: Die beiden oben genannten Erweiterungen. --etc (Siehe die Readme-Datei von pyclustering. Es gibt verschiedene)
Bestimmen der Anzahl der Cluster
Es wäre schön, wenn die Anzahl der Cluster von Menschen, die sich die Daten ansehen, sofort erkannt werden könnte, aber das ist selten, daher möchte ich eine quantitative Beurteilungsmethode.
Laut sklearn Spickzettel
- MeanShift
- VBGMM
Ist empfohlen.
Ist auch nützlich, aber meiner Erfahrung nach war es selten, dass ich einen schönen Ellbogen bekam (ein Punkt, an dem die Grafik ruckelt), und ich war oft verwirrt über die Anzahl der Cluster.
Es gibt x-means als Methode, um Clustering mit der Anzahl der Cluster vollautomatisch durchzuführen.
Im Folgenden wird beschrieben, wie Sie die Bibliothek "pyclustering" verwenden, die verschiedene Clustering-Methoden einschließlich x-means enthält.
Wie benutzt man Pyclustering?
pyclustering ist eine Bibliothek von Clustering-Algorithmen, die sowohl in Python als auch in C ++ implementiert sind.
Installation
Abhängige Pakete: scipy, matplotlib, numpy, PIL
pip install pyclustering
x-Verwendungsbeispiel
Zusätzlich zum EM-Schritt in k-means bestimmt x-means einen neuen Schritt: ob es angemessen ist, einen Cluster durch zwei oder eine Normalverteilung darzustellen, und zwei sind Gegebenenfalls wird der Cluster in zwei Teile geteilt.
Unten wird ein Jupyter-Notebook verwendet.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import cluster, preprocessing
#Wein-Datensatz
df_wine_all=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data', header=None)
#Vielfalt(Zeile 0, 1-3)Und Farbe (10 Reihen) und Menge Prolin(13 Reihen)Benutzen
df_wine=df_wine_all[[0,10,13]]
df_wine.columns = [u'class', u'color', u'proline']
#Datenformung
X=df_wine[["color","proline"]]
sc=preprocessing.StandardScaler()
sc.fit(X)
X_norm=sc.transform(X)
#Handlung
%matplotlib inline
x=X_norm[:,0]
y=X_norm[:,1]
z=df_wine["class"]
plt.figure(figsize=(10,10))
plt.subplot(4, 1, 1)
plt.scatter(x,y, c=z)
plt.show
# x-means
from pyclustering.cluster.xmeans import xmeans
from pyclustering.cluster.center_initializer import kmeans_plusplus_initializer
xm_c = kmeans_plusplus_initializer(X_norm, 2).initialize()
xm_i = xmeans(data=X_norm, initial_centers=xm_c, kmax=20, ccore=True)
xm_i.process()
#Zeichnen Sie die Ergebnisse
z_xm = np.ones(X_norm.shape[0])
for k in range(len(xm_i._xmeans__clusters)):
z_xm[xm_i._xmeans__clusters[k]] = k+1
plt.subplot(4, 1, 2)
plt.scatter(x,y, c=z_xm)
centers = np.array(xm_i._xmeans__centers)
plt.scatter(centers[:,0],centers[:,1],s=250, marker='*',c='red')
plt.show
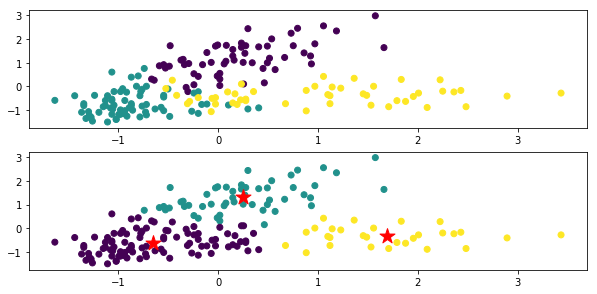
Die Oberseite ist die für jede Klasse der Originaldaten farbige Zahl, und die Unterseite ist das Clustering-Ergebnis mit x-Mitteln. Die Markierung ★ ist der Schwerpunkt jeder Klasse.
Im Code "xm_c = kmeans_plusplus_initializer (X_norm, 2) .initialize ()" wird der Anfangswert der Anzahl der Cluster auf 2 gesetzt, aber ordnungsgemäß auf 3 geclustert.
Ich führe x-means mit xm_i.process () aus.
Wenn Sie für die x-means-Instanz (xm_i im obigen Code) die Instanzvariablen vor und nach dem Lernen betrachten, können Sie sehen, wie das Lernergebnis aussieht. Zum Beispiel
xm_i.__dict__.keys()
Oder
vars(xm_i).keys()
Kann mit erhalten werden
dict_keys(['_xmeans__pointer_data', '_xmeans__clusters', '_xmeans__centers', '_xmeans__kmax', '_xmeans__tolerance', '_xmeans__criterion', '_xmeans__ccore'])
Ich denke, Sie sollten sich verschiedene Dinge ansehen, wie z.
_xmeans__pointer_data
Eine Kopie der zu gruppierenden Daten.
_xmeans__clusters
Eine Liste, die zeigt, welche Zeile der Originaldaten (\ _xmeans__pointer_data) zu jedem Cluster gehört.
Die Anzahl der Elemente in der Liste entspricht der Anzahl der Cluster, jedes Element ist auch eine Liste, und die Nummer der zum Cluster gehörenden Zeile wird gespeichert.
_xmeans__centers
Eine Liste der Schwerpunktkoordinaten (Listen) für jeden Cluster
_xmeans__kmax
Maximale Anzahl von Clustern (Sollwert)
_xmeans__tolerance
Eine Konstante, die die Stoppbedingung für die x-bedeutet-Iteration bestimmt. Der Algorithmus wird beendet, wenn die maximale Änderung des Schwerpunkts des Clusters unter diese Konstante fällt.
_xmeans__criterion
Es ist eine Beurteilungsbedingung der Clusterteilung. Standard: BIC
_xmeans__ccore
Dies ist der Einstellungswert für die Verwendung von C ++ - Code anstelle von Python-Code.
Recommended Posts