[PYTHON] Umgang mit unausgeglichenen Daten
Dies ist der Artikel am 10. Tag des Adventskalenders des Docomo Advanced Technology Research Institute.
Ich heiße Kaneda von Docomo. Dieser Artikel enthält die Grundlagen zum Bewerten und Erstellen von Modellen für unausgeglichene Daten, mit denen Sie bei der Analyse realer Daten konfrontiert sind. Außerdem führen wir in der zweiten Hälfte des Artikels Experimente durch, um unser Verständnis von unausgeglichenen Daten zu vertiefen. Ich denke, es gibt viele Punkte, die nicht erreicht werden können, aber danke.
1. Was sind unausgeglichene Daten?
Daten wie ** positives Beispiel 1%, negatives Beispiel 99% **. Es ist nicht auf die binäre Klassifizierung beschränkt, sondern kann in einer Klassifizierung mit mehreren Klassen behandelt werden. Dieser Artikel konzentriert sich auf die häufigsten binären Klassifikationen (bei denen es positive und negative Minderheitenfälle gibt).
2. Bewertungsmethode
Der Schlüssel zum Erstellen eines Modells aus unausgeglichenen Daten liegt in der Entscheidung, wie das Modell bewertet werden soll. Wenn die Bewertungsmethode nicht festgelegt ist, wissen Sie nicht, welches Ziel Sie anstreben sollten. Bei unausgeglichenen Daten ist zu beachten, dass es Bewertungsindikatoren gibt, die nicht wie in normalen Zeiten interpretiert werden können.
Wie zu bewerten
Zusammenfassend halte ich es für besser, ** eine Präzisionsrückrufkurve (im Folgenden als PR-Kurve bezeichnet) ** zu zeichnen. Darüber hinaus ist es wichtig, das für jede Problemeinstellung erforderliche Gleichgewicht zwischen Präzision und Rückruf zu berücksichtigen, einen geeigneten Schwellenwert festzulegen und eine endgültige binäre Klassifizierung durchzuführen. Bei der Optimierung der Parameter des Modells wird empfohlen, den Bereich unter der PR-Kurve (im Folgenden als PR-AUC bezeichnet) als Bewertungsindex zu verwenden.
Im Folgenden erklären wir, warum PR-Kurven und PR-AUC zur Vorhersage unausgeglichener Daten verwendet werden sollten.
Richtige und falsche Antworten in der binären Klassifikation
| Positiv | Negativ | |
|---|---|---|
| Positiv | TP: True Positive | FN:False Negative |
| Negativ (wahrer Wert) | FP: False Positive | TN: True Negative |
Diese Tabelle wird als gemischte Matrix bezeichnet und ist unter Berücksichtigung des Bewertungsindex der binären Klassifizierung unverzichtbar. Da es richtig ist, vorherzusagen, dass ein positives Beispiel ein positives und ein negatives Beispiel ein negatives Beispiel ist, ist ein Modell mit vielen TPs und TNs und wenigen FNs und FPs ein gutes Modell.
Überlegen Sie zu diesem Zeitpunkt, ob die Reduzierung der falschen Vorhersagen von FN und FP priorisiert werden soll. Generieren Sie bei der Vorhersage unausgeglichener Daten im Allgemeinen häufig die Reduzierung der FN? Der Grund dafür ist, dass es viele Fälle gibt, in denen das positive Beispiel definitiv als positives Beispiel beurteilt wird, solange der positive Fall der Minderheit falsch eingeschätzt wird, auch wenn der negative Fall der Mehrheit als positives Beispiel leicht falsch eingeschätzt wird. Dies liegt daran (natürlich hängt es von der Problemeinstellung ab). ** In der Problemstellung, mit der Sie jetzt konfrontiert sind, ist es wichtig zu wissen, ob FN oder FP in der endgültigen Binärklassifizierung priorisiert werden sollten. ** ** **
Typischer Bewertungsindex
Schauen wir uns auf der Grundlage des oben Gesagten typische Bewertungsindizes in der binären Klassifizierung an.
Accuracy = (TP+TN)/(TP+FP+TN+FN)
Die Genauigkeit ist der offensichtlichste Indikator, aber es ist schwierig, unausgeglichene Daten vorherzusagen. Dies liegt daran, dass die Genauigkeit leicht nahe am Maximalwert von 1 liegen kann, indem einfach ein Modell erstellt wird, das alle negativen Beispiele der Mehrheit vorhersagt. Offensichtlich ist ein solches Modell nicht das, nach dem Sie suchen, daher wäre es unangemessen, die Genauigkeit als Indikator zu verwenden.
Precision = TP/(TP+FP)\\
Recall = TP/(TP+FN)
Als nächstes folgen Präzision und Rückruf. Diese werden im Allgemeinen als in einer Kompromissbeziehung stehend angesehen, und wenn die Präzision hoch / niedrig ist, ist der Rückruf niedrig / hoch. Lassen Sie uns nun noch einmal über FN und FP nachdenken, um zu überlegen, welche priorisiert werden sollten. Früher habe ich erklärt, dass Sie häufig FN reduzieren möchten, wenn Sie unausgeglichene Daten vorhersagen. In diesem Fall sollten Sie jedoch versuchen, den Rückruf zu erhöhen, der FN im Nenner enthält. Wenn Sie jedoch nur möchten, dass Recall der Maximalwert von 1 ist, müssen Sie ein Modell erstellen, das im Gegensatz zum Genauigkeitsbeispiel alle positiven Minderheiten vorhersagt. ** Daher ist es nicht erforderlich, nur Präzision oder Rückruf als Bewertungsindex zu verwenden, und es ist erforderlich, das Modell anhand der beiden Bewertungsindizes umfassend zu bewerten. ** ** **
Es gibt jedoch viele Fälle, in denen Sie die beiden Metriken Precision und Recall zu einer kombinieren möchten. Der zu diesem Zeitpunkt häufig verwendete Bewertungsindex ist der unten eingeführte F1-Wert.
F-measure = 2Recall*Precision/(Recall+Precision)
Der F1-Wert wird aus dem harmonisierten Durchschnitt von Präzision und Rückruf berechnet. Intuitiv hat ein Modell mit einem hohen F1-Wert eine hohe Präzision und einen hohen Rückruf. Bitte beachten Sie, dass der F1-Wert Precison und Recall gleichermaßen bewertet und kein Index ist, der entweder Precision oder Recall priorisiert [^ 1].
Über die Schwelle
Bevor ich mit der Einführung des nächsten Bewertungsindex fortfahre, werde ich das Konzept der Schwellenwerte bei der binären Klassifizierung erläutern. Bei der Vorhersage, ob das Modell positiv oder negativ ist, wird zuerst eine Bewertung wie "80% Wahrscheinlichkeit, positiv zu sein" berechnet. Wenn die Bewertung höher als der Schwellenwert ist (z. B. 50%), ist sie positiv und wenn sie niedriger ist, ist sie negativ. Die angenommene Verarbeitung wird durchgeführt. Da sich das Vorhersageergebnis durch Ändern dieses Schwellenwerts stark ändert, muss entschieden werden, welcher Schwellenwert verwendet werden soll, wenn tatsächlich eine binäre Klassifizierung durchgeführt wird.
Die vier zuvor eingeführten Arten von Bewertungsindizes sind alle Indizes, die nach der Bestimmung des Schwellenwerts berechnet wurden. Wenn im Voraus entschieden wird, dass "50% der Schwellenwert ist", denke ich, dass das Modell so konstruiert werden kann, dass der F1-Wert, der berechnet wird, wenn der Schwellenwert 50% beträgt, der höchste ist. Es gibt jedoch viele Fälle, in denen ** nur eine ordnungsgemäße Klassifizierung nach einem der Schwellenwerte erforderlich ist (der Schwellenwert ist nicht auf einen bestimmten Wert festgelegt) **, und in diesem Fall wird ein Bewertungsindex verwendet, für den kein Schwellenwert erforderlich ist.
Bewertungsindex, für den kein Schwellenwert erforderlich ist
Die Fläche unter der ROC-Kurve (ROC-AUC) und die Fläche unter der PR-Kurve (PR-AUC) sind Bewertungsindizes, für die kein Schwellenwert erforderlich ist.
--ROC-AUC: Fläche unter der Kurve, die beim Zeichnen der Beziehung zwischen Rückruf und falsch positiver FPR-Rate beim Ändern des Schwellenwerts gezeichnet wurde (linke Abbildung) --PR-AUC: Fläche unter der Kurve, die beim Zeichnen der Beziehung zwischen Präzision und Rückruf beim Ändern des Schwellenwerts gezeichnet wird (rechte Abbildung)
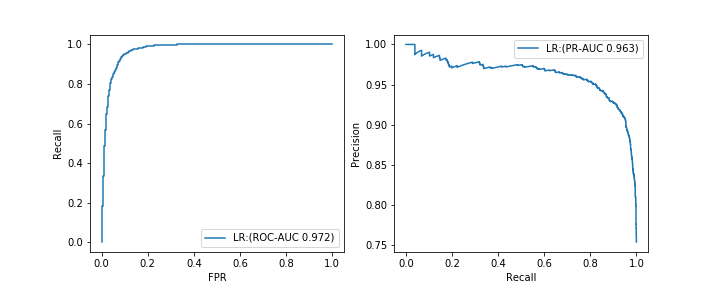
Die Formel zur Berechnung der falsch positiven Rate FPR lautet wie folgt.
FPR = FP/(FP+TN)
Ich denke, dass AUC oft auf ROC-AUC verweist. Ich werde die ausführliche Erklärung weglassen, aber alle Indikatoren haben ähnliche grundlegende Eigenschaften. Je näher am Maximalwert 1, desto besser das Modell. Da beide auf der Grundlage von zwei Bewertungsindizes wie dem F1-Wert berechnet werden, betrachten wir normalerweise kein bedeutungsloses Modell, das alle als positive oder negative Beispiele als gut vorhersagt. Im Fall einer ** unausgeglichenen Datenvorhersage ist die ROC-AUC jedoch möglicherweise keine geeignete Metrik. ** ** **
Es ist schwierig, den Grund genau zu erklären, aber als leicht verständliches Verständnis von mir selbst bewertet ** ROC-AUC "Ist es möglich, positive Beispiele als positive Beispiele und negative Beispiele als negative Beispiele korrekt vorherzusagen?" Andererseits berücksichtigt PR-AUC nur "ob das richtige Beispiel korrekt als das richtige Beispiel vorhergesagt werden kann" als Bewertungspunkt. ** Im Fall einer unausgeglichenen Datenvorhersage ist es einfach, die Mehrzahl der negativen Fälle als negative Fälle vorherzusagen, und die ROC-AUC, die dies als Bewertungspunkt verwendet, ** sind die meisten positiven Fälle positive Fälle. Selbst wenn Sie es nicht vorhersagen können, ** führt das Erstellen eines Modells, das die meisten negativen Fälle als negativ vorhersagt, wahrscheinlich zu höheren Endwerten. Andererseits berücksichtigt PR-AUC nur, ob ein positives Beispiel als positives Beispiel vorhergesagt werden kann. Unabhängig davon, wie korrekt ein negatives Beispiel als negatives Beispiel vorhergesagt wird, wird es überhaupt nicht bewertet.
Dies bedeutet jedoch nicht, dass PR-AUC ROC-AUC überlegen ist. ** Bei der Vorhersage unausgeglichener Daten ist es wichtig, Beispiele für Minderheiten richtig vorherzusagen (ich denke, dass dies häufig der Fall ist). Daher wird **, PR-AUC als geeigneter Bewertungsindex angesehen.
Wenn es ein Modell A mit einer PR-AUC von 0,5 und ein Modell B mit einer PR-AUC von 0,4 gab, "ist die mit der PR-AUC erzielte Gesamtleistung mit dem Modell A besser, aber ein spezifischer Rückruf Zu diesem Zeitpunkt ist die Präzision von Modell B höher. “** Halten Sie sich also nicht so sehr an einen AUC-Wert, berücksichtigen Sie das erforderliche Gleichgewicht zwischen Präzision und Rückruf, zeichnen Sie eine PR-Kurve und final Ich finde es gut, die Qualität eines typischen Modells zu überprüfen. ** ** **
3. Wie erstelle ich ein Modell?
Im Folgenden werden allgemeine Gegenmaßnahmen für unausgeglichene Daten eingeführt. In diesem Artikel werde ich nur die Gliederung kurz vorstellen.
Datenverarbeitung
Am einfachsten ist es, die Mehrheitsdaten zu reduzieren (Unterabtastung) oder die Minderheitsdaten zu erhöhen (Überabtastung). Es ist auch möglich, diese beiden zu kombinieren. Bei Unterabtastung gibt es eine Methode, bei der Clustering verwendet wird, um eine Abtastverzerrung zu verhindern. Beim Oversampling ist auch ein Algorithmus namens SMOTE bekannt.
Wenn Sie die Daten durch Stichproben anpassen, wird der Ausgabewert verzerrt. Wenn also der Bewertungswert selbst wichtig ist, müssen Sie den Wert [^ 2] korrigieren. Wenn der Bewertungswert selbst nicht wichtig ist und es wichtig ist, ihn in positive und negative Fälle zu unterteilen, ist keine Korrektur erforderlich.
Verarbeitung für den Algorithmus
Beim Training des Modells lösen wir intern das Problem der Zielfunktionsminimierung. Zu diesem Zeitpunkt ist es durch Anpassen der Strafe für die Fehleinschätzung des negativen Falls, bei dem es sich um die Mehrheit handelt, und der Strafe für die Fehleinschätzung des positiven Falls, bei dem es sich um die Minderheit handelt, möglich, den positiven Fall, bei dem es sich um die Minderheit handelt, korrekt vorherzusagen. ..
Ergänzung: Nutzung des Ensemble-Lernens
Wenn die Mehrheit der negativen Daten durch Unterabtastung reduziert wird, wird erwartet, dass sich die Tendenz negativer Daten abhängig davon ändert, wie sie reduziert werden. Es gibt viele Möglichkeiten, den Datentrend unverändert zu lassen, aber es wird gesagt, dass eine Methode, die das Lernen von Ensembles kombiniert, ein guter Weg ist, damit umzugehen [^ 3].
Ergänzung: Erkennung von Anomalien
Wenn sich die Anzahl der Daten zwischen positiven und negativen Beispielen zu stark unterscheidet, können Sie die positiven Beispiele für Minderheiten als abnormal betrachten und dann den Algorithmus zur Erkennung von Anomalien anwenden (in diesem Artikel weggelassen). ..
4. Experimentieren
Experimentieren Sie, um unausgeglichene Daten besser zu verstehen. In diesem Experiment werden unausgeglichene Daten aus Zufallszahlen erstellt, die einer Normalverteilung folgen, und anhand verschiedener Modelle ausgewertet. Die Datenmenge beträgt 500 für positive Fälle (y = 1) und 10000 für negative Fälle (y = 0). Die Merkmalsmenge ist zweidimensional, um die einfache Visualisierung hervorzuheben.
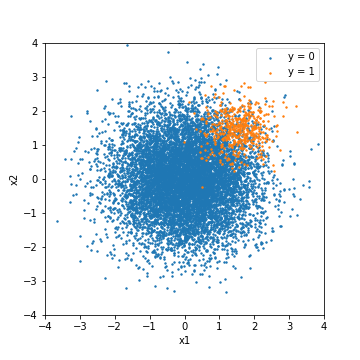
Als minimale experimentelle Bedingung werden die Trainingsdaten und die Testdaten durch 8: 2 getrennt, und die Testdaten werden nach einfacher Parametereinstellung vorhergesagt. In diesem Experiment werden zum Vergleich das Ergebnis der Abstimmung basierend auf dem F1-Wert und das Ergebnis der Abstimmung basierend auf PR-ROC [^ 4] beschrieben.
#Bei der Abstimmung mit dem Wert f1
GridSearchCV(model, params, scoring="f1")
# PR-Beim Einstellen mit AUC
GridSearchCV(model, params, scoring="average_precision")
Versuchen Sie beim Teilen eines Datensatzes, ihn zu teilen, während Sie das Gleichgewicht zwischen positiven und negativen Beispielen beibehalten [^ 5].
# scikit-Zug lernen_test_Bei Verwendung der Split-Funktion
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y)
Logistische Rückgabe
Keine Aktion
Das erste ist das Vorhersageergebnis einer normalen logistischen Regression ohne besonderen Einfallsreichtum.
- Abstimmung mit F1-Wert
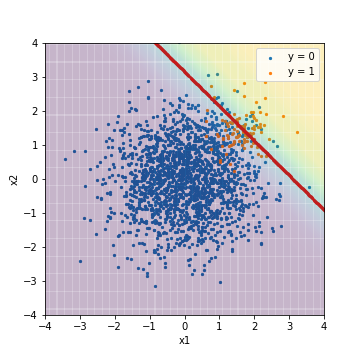
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR@F1 | 0.960 | 0.642 | 0.430 | 0.515 | 0.975 | 0.632 |
Die Hintergrundfarbe gibt den Bewertungswert an, wobei Gelb ein positives Beispiel und Lila ein negatives Beispiel angibt. Die rote Linie ist der Schwellenwert, und die Werte für Genauigkeit, Präzision, Rückruf und F1 werden aus den Ergebnissen der Klassifizierung basierend auf diesem Schwellenwert berechnet. Wie erwartet wurde das Ergebnis durch den negativen Fall der Mehrheit in Mitleidenschaft gezogen.
ROC-AUC ist ein erstaunlicher Wert von 0,975.
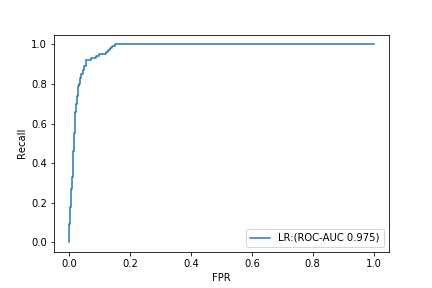
Andererseits beträgt PR-AUC 0,632.
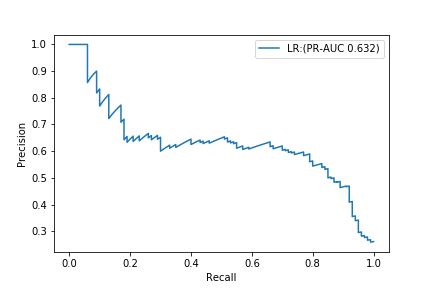
Wenn Sie sich nur ROC-AUC ansehen, werden Sie denken, dass Sie ein erschreckend gutes Modell gemacht haben, aber wenn Sie die PR-Kurve überprüfen, werden Sie feststellen, dass es kein sehr gutes Modell ist.
- Abstimmung mit PR-AUC
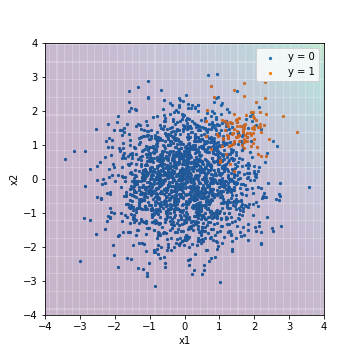
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR@PR-AUC | 0.950 | 0.000 | 0.000 | 0.000 | 0.975 | 0.632 |
Im Vergleich zum Ergebnis der Abstimmung mit dem F1-Wert können Sie sehen, dass die Hintergrundfarbe insgesamt lila wurde (dies deutete auf ein negatives Beispiel hin). In diesem Ergebnis liegen alle Daten unter dem Schwellenwert, und die Werte werden berechnet, nachdem vorhergesagt wurde, dass alle auf dem Schwellenwert basierenden Indikatoren negative Beispiele sind. Andererseits sind die Werte von ROC-AUC und PR-AUC dieselben wie das Ergebnis der Abstimmung mit dem F1-Wert. Dies liegt daran, dass ROC-AUC und PR-AUC nicht die absoluten Werte der Bewertungen sind, sondern Indikatoren, die bewerten, ob die Vorhersageergebnisse in der Reihenfolge der Bewertung sortiert sind, mit positiven Beispielen oben und negativen Beispielen unten. Mit anderen Worten kann gefolgert werden, dass diese beiden Arten von Ergebnissen fast dieselbe Reihenfolge haben, wenn die Vorhersageergebnisse in der Reihenfolge der Bewertung sortiert werden, obwohl sich die absoluten Werte der Bewertungen geändert haben.
Verarbeitung für den Algorithmus
Als nächstes folgt das Ergebnis der logistischen Regression, wobei die Verarbeitung auf den Algorithmus angewendet wird. Mit scikit-learn müssen Sie lediglich den Parameter class_weight festlegen.
#Beim Anwenden der Verarbeitung auf den Algorithmus
clf = LogisticRegression(class_weight="balanced")
- Abstimmung mit F1-Wert
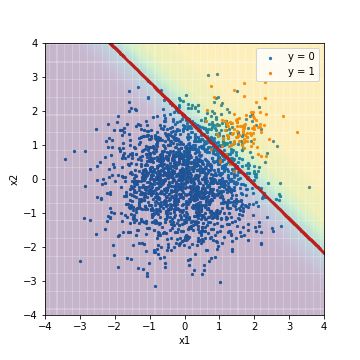
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR_weight@F1 | 0.901 | 0.329 | 0.950 | 0.488 | 0.975 | 0.633 |
- Abstimmung mit PR-AUC
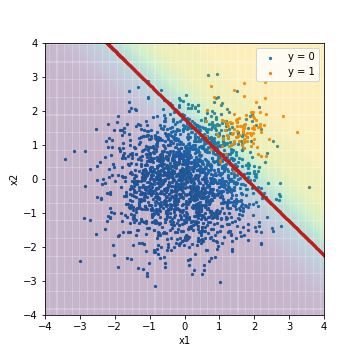
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR_weight@PR-AUC | 0.887 | 0.301 | 0.950 | 0.457 | 0.975 | 0.631 |
Im Vergleich zum Ergebnis der normalen logistischen Regression, die zuvor mit dem F1-Wert abgestimmt wurde, ist ersichtlich, dass sich die Position des Schwellenwerts deutlich nach links unten bewegt, um das richtige Beispiel korrekt vorherzusagen. Gleichzeitig steigt Recall stark an. Andererseits unterscheiden sich ROC-AUC und PR-AUC nicht wesentlich. Auch in diesem Fall wird davon ausgegangen, dass sich die Reihenfolge, in der die Vorhersageergebnisse in der Reihenfolge der Bewertungen sortiert sind, nicht geändert hat, wie im Fall einer normalen logistischen Regression.
Datenverarbeitung
Schließlich ist es das Ergebnis einer logistischen Regression, bei der die Daten verarbeitet werden. Es verwendet eine Technik namens SMOTE Tomek, die in der Bibliothek für unausgeglichenes Lernen (https://imbalanced-learn.readthedocs.io/en/stable/) implementiert ist. Dies ist eine Methode, die Unter- und Downsampling kombiniert. Durch die Anwendung von SMOTETomek werden die Trainingsdaten, die ursprünglich 400 positive und 7600 negative Fälle waren, sowohl für positive als auch für negative Fälle 7439 betragen.
- Abstimmung mit F1-Wert
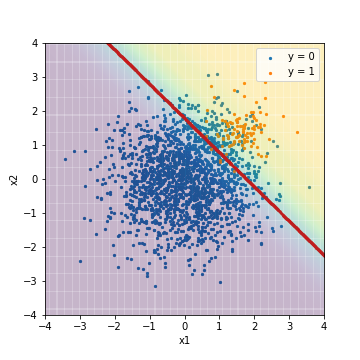
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR_sampling@F1 | 0.891 | 0.308 | 0.950 | 0.466 | 0.975 | 0.632 |
- Abstimmung mit PR-AUC
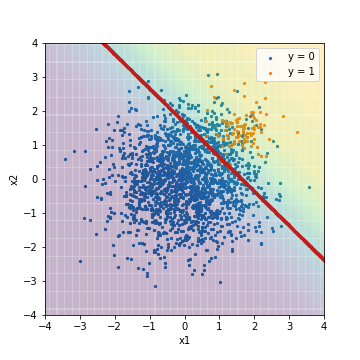
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR_sampling@PR-AUC | 0.873 | 0.279 | 0.970 | 0.433 | 0.975 | 0.632 |
Das Ergebnis ist fast das gleiche wie das Ergebnis einer logistischen Regression, bei der die Verarbeitung für den Algorithmus angewendet wird. Es gibt keinen großen Unterschied zwischen den einzelnen Indizes.
Die Ergebnisse der logistischen Regression sind wie folgt. In diesem Beispiel können wir aus der Sicht von PR-AUC sehen, dass alle Modelle die gleiche Leistung haben.
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR@F1 | 0.960 | 0.642 | 0.430 | 0.515 | 0.975 | 0.632 |
| LR@PR-AUC | 0.950 | 0.000 | 0.000 | 0.000 | 0.975 | 0.632 |
| LR_weight@F1 | 0.901 | 0.329 | 0.950 | 0.488 | 0.975 | 0.633 |
| LR_weight@PR-AUC | 0.887 | 0.301 | 0.950 | 0.457 | 0.975 | 0.631 |
| LR_sampling@F1 | 0.891 | 0.308 | 0.950 | 0.466 | 0.975 | 0.632 |
| LR_sampling@PR-AUC | 0.873 | 0.279 | 0.970 | 0.433 | 0.975 | 0.632 |
Für SVM (RBF-Kernel)
Als nächstes machte ich einen ähnlichen Vergleich mit dem nichtlinearen Modell SVM (RBF-Kernel). Die rote Linie der Schwelle wird hier nicht angezeigt.
Keine Aktion
Das erste ist das Vorhersageergebnis einer normalen SVM ohne besondere Maßnahmen.
- Abstimmung mit F1-Wert
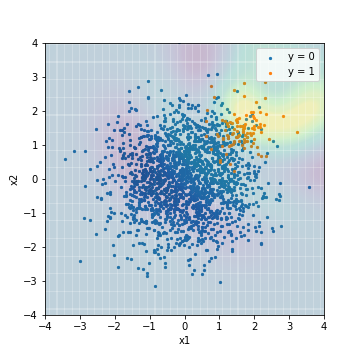
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM@F1 | 0.964 | 0.656 | 0.590 | 0.621 | 0.966 | 0.629 |
- Abstimmung mit PR-AUC
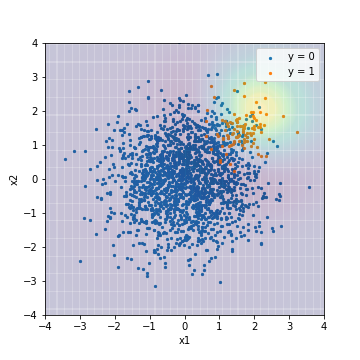
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM@PR-AUC | 0.950 | 0.000 | 0.000 | 0.000 | 0.934 | 0.650 |
Im Gegensatz zum Ergebnis der logistischen Regression gibt es einen deutlichen Unterschied im Ergebnis, je nachdem, ob es mit dem F1-Wert oder PR-AUC abgestimmt ist. Es wird vorausgesagt, dass die Punktzahl bei Abstimmung mit PR-AUC von rechts oben in der Mitte des Beispiels radial abnimmt. Dies scheint ein vernünftiges Ergebnis für dieses Modell zu sein, das sich nicht mit unausgeglichenen Daten befasst. .. Im Gegenteil, die Punktzahl, wenn sie mit dem F1-Wert eingestellt wird, sieht etwas unnatürlich aus. ** Tatsächlich abgestimmte SVM mit PR-AUC hat eine höhere PR-AUC als alle Modelle der logistischen Regression, während SVM, die mit dem F1-Wert eingestellt wurde, eine niedrigere PR-AUC aufweist als alle Modelle der logistischen Regression. Ich werde. ** Auf dieser Grundlage wird angenommen, dass der Bewertungsindex zum Zeitpunkt der Optimierung wichtig wird, wenn ein Modell mit hoher Ausdruckskraft erstellt wird.
Verarbeitung für den Algorithmus
Als nächstes wird das Ergebnis der SVM für den Algorithmus angepasst.
clf = SVC(class_weight="balanced")
- Abstimmung mit F1-Wert
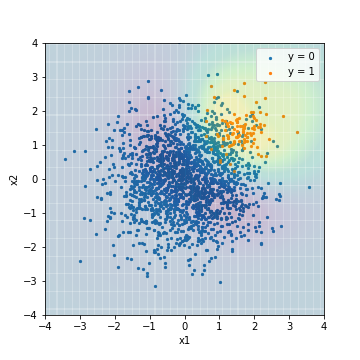
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM_weight@F1 | 0.904 | 0.339 | 0.970 | 0.503 | 0.976 | 0.575 |
- Abstimmung mit PR-AUC
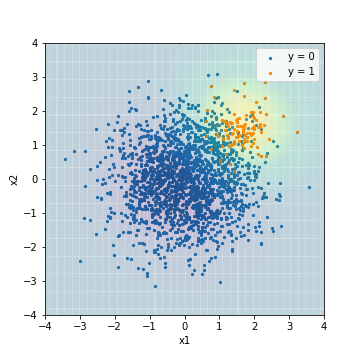
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM_weight@PR-AUC | 0.050 | 0.050 | 1.00 | 0.095 | 0.978 | 0.639 |
In allen Ergebnissen ist ersichtlich, dass das Modell darauf trainiert ist, das richtige Beispiel korrekter vorherzusagen als das normale SVM-Vorhersageergebnis. Andererseits beträgt die PR-AUC von SVM, die mit dem F1-Wert eingestellt ist, 0,575, was die schlechteste aller Zeiten ist.
Datenverarbeitung
Schließlich ist es das Ergebnis der SVM, die die Verarbeitung auf die Daten angewendet hat.
- Abstimmung mit F1-Wert
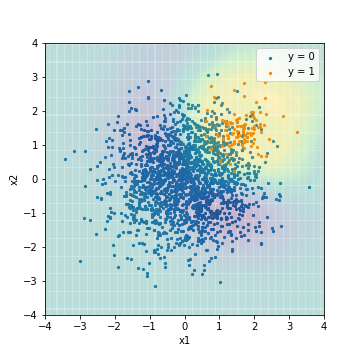
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM_sampling@F1 | 0.903 | 0.338 | 0.990 | 0.504 | 0.968 | 0.473 |
- Abstimmung mit PR-AUC
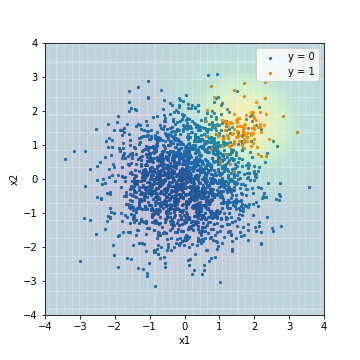
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM_sampling@PR-AUC | 0.877 | 0.289 | 1.0 | 0.448 | 0.978 | 0.637 |
Der Gesamttrend war ähnlich dem Ergebnis der SVM-Anwendung der Verarbeitung auf den Algorithmus. Andererseits wurde die PR-AUC des mit dem F1-Wert abgestimmten Modells mit 0,473 noch schlechter.
Das Ergebnis von SVM ist wie folgt. In diesem Beispiel wurde bei der Bewertung aus Sicht von PR-AUC festgestellt, dass die Leistung erheblich abnimmt, es sei denn, PR-AUC wird beim Einstellen als Bewertungsindex festgelegt. Dies liegt vermutlich daran, dass SVM ein sehr aussagekräftiges Modell ist. Im Vergleich zu linearen Modellen wie der logistischen Regression ist es ein Modell, das sich auf den für die Optimierung verwendeten Bewertungsindex spezialisiert hat.
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM@F1 | 0.964 | 0.656 | 0.590 | 0.621 | 0.966 | 0.629 |
| SVM@PR-AUC | 0.950 | 0.000 | 0.000 | 0.000 | 0.934 | 0.650 |
| SVM_weight@F1 | 0.904 | 0.339 | 0.970 | 0.503 | 0.976 | 0.575 |
| SVM_weight@PR-AUC | 0.050 | 0.050 | 1.00 | 0.095 | 0.978 | 0.639 |
| SVM_sampling@F1 | 0.903 | 0.338 | 0.990 | 0.504 | 0.968 | 0.473 |
| SVM_sampling@PR-AUC | 0.877 | 0.289 | 1.0 | 0.448 | 0.978 | 0.637 |
PR-Kurvenvergleich
Schließlich werden die PR-Kurven der 6 in diesem Experiment getesteten Modelltypen (abgestimmt mit PR-AUC) angeordnet.
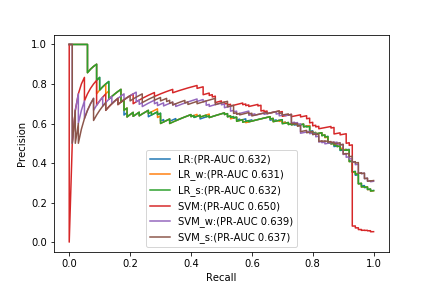
Im Vergleich zu PR-AUC allein ist das beste Modell eine normale SVM, die sich mit nichts befasst. Wenn der Rückruf jedoch hoch ist, sinkt die Präzision der SVM stark, und es ist besser, ein anderes Modell zu verwenden. Ich werde. Anhand dieses Ergebnisses können Sie erkennen, dass es schwierig ist, ein geeignetes Modell nur mit PR-AUC auszuwählen. Auch hier denke ich, dass es wichtig ist, das Gleichgewicht zwischen Präzision und Rückruf aus der ** PR-Kurve zu betrachten und das Modell mit der besten Leistung für diese Problemstellung zu finden. ** ** **
Zusammenfassung
- Zeichnen wir eine PR-Kurve!
Referenz
- Unausgeglichene Daten - Beispiel für die Implementierung eines ROC-Kurvenfehlers
- Unterschied im Verhalten zwischen PR-Kurve und ROC-Kurve in Ungleichgewichtsdaten
- Bewertungsindex des maschinellen Lernens, der von Null aus verstanden werden kann! Fit Rate-Recall Rate / ROC-Kurve und AUC
- Diskussion über den Unterschied zwischen ROC-Kurve und PR-Kurve
[^ 1]: Es gibt auch einen Index namens Fβ-Wert, der eine Verallgemeinerung des F1-Werts darstellt. Sie können die Priorität von Präzision und Rückruf anpassen, indem Sie den Wert von β anpassen. [^ 2]: Verzerrung der Vorhersagewahrscheinlichkeit aufgrund von Downsampling [^ 3]: Imbalanced-Learn, eine Bibliothek zur Vorhersage unausgeglichener Daten, bietet eine praktische Klasse namens BalancedBaggingClassifier, um diese Methode zu implementieren. [^ 4]: Die im Bewertungsparameter angegebene durchschnittliche Genauigkeit ist eine Annäherung an PR-ROC. Referenz: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.average_precision_score.html [^ 5]: GridSearchCV ist für die binäre Klassifizierung standardmäßig in Ebenen unterteilt (unter Beibehaltung des Gleichgewichts).
Recommended Posts