[PYTHON] Einführung in die Monte-Carlo-Methode
Einführung
Heutzutage ist der Bayes'sche Ansatz nicht mehr die Norm, und es ist beliebt, Trainingsdaten zu sammeln und in Deep Learning zu integrieren, aber manchmal ist es möglich, solche klassischen Berechnungen durchzuführen.
Ich wollte MCMC erklären, aber es war nicht einfach, einfache Simulationen zu erklären, deshalb werde ich einfache Simulationen einmal erklären. Ich persönlich möchte in naher Zukunft über MCMC schreiben.
Dieser Artikel basiert weitgehend auf Kapitel 11 von PRML.
Monte-Carlo-Methode
Wenn Sie am maschinellen Lernen beteiligt sind, hören Sie häufig das Wort Monte-Carlo-Simulation oder Monte-Carlo-Methode. Bevor ich diesen Artikel schrieb, dachte ich vage: "Ah, MCMC, richtig?", Aber als ich versuchte, ihn konkret zu erklären, blieb ich in der Antwort stecken. In einem solchen Fall können Sie, wenn Sie Wikipedia fragen, die allgemeine Idee verstehen, daher möchte ich vorerst einen Blick auf den Wikipedia-Artikel werfen.
Monte-Carlo-Methode (Monte-Carlo-Methode, (Englisch):Die Monte-Carlo-Methode (MC) ist ein allgemeiner Begriff für Methoden, die Simulationen und numerische Berechnungen unter Verwendung von Zufallszahlen durchführen.
Benannt nach Monte Carlo, einem der vier Bezirke (Culti) des Fürstentums Monaco, berühmt für seine Casinos.
Monte Carlo war nur ein Ortsname. Als ich das Wort Casino hörte, fragte ich mich, ob die Leute, die versuchten, im Casino zu gewinnen, es für eine Simulation erstellt hatten.
Auf dem Gebiet der Computertheorie wird die Monte-Carlo-Methode als Zufallsalgorithmus definiert, der eine Obergrenze für die Wahrscheinlichkeit eines Fehlers angibt.[1]。
Mit anderen Worten, die meisten Dinge können als Monte-Carlo-Simulation oder Monte-Carlo-Methode unter Verwendung von Zufallszahlen bezeichnet werden. Tatsächlich heißt es in dem Artikel, dass die "Mirror-Rabin-Primzahl-Beurteilungsmethode", ein Algorithmus zur probabilistischen Bestimmung, ob eine Primzahl eine Primzahl ist oder nicht, auch die Monte-Carlo-Methode ist. Dieses Mal konzentriere ich mich jedoch auf maschinelles Lernen und habe keine Zeit, die Methode zur Beurteilung von Primzahlen zu übersehen.
Daher möchte ich mein Denken auf Folgendes beschränken.
Betrachten Sie einen Algorithmus, der eine Zufallszahl X erzeugt, die der Verteilung von P folgt, wenn eine bestimmte Wahrscheinlichkeitsverteilung P bestimmt wird.
Wenn Sie die Zufallszahl $ X $ generieren können, die in der obigen Problemeinstellung angezeigt wird, können Sie sie auf verschiedene Simulationen und numerische Berechnungen anwenden.
Inhaltsverzeichnis
--Variable Konvertierungsmethode --Exponentialverteilung
- Normalverteilung
- Cauchy Verteilung
- Ablehnungs-Probenahmemethode
- Gammaverteilung
Angenommen, es ist möglich, eine gleichmäßig verteilte Zufallszahl $ U $ von $ [0, 1] $ zu erzeugen. Aus diesem $ U $ eine Zufallszahl, die der berühmten Wahrscheinlichkeitsverteilung folgt
Variable Konvertierungsmethode
Sei $ P $ die Wahrscheinlichkeitsverteilung, die Sie generieren möchten.
Eine variable Konvertierungsmethode zum Finden einer Funktion $ F_ {P}
Da $ u und y $ gleichzeitig erscheinen, habe ich das Gefühl, nicht zu verstehen. Da es jedoch eine Beziehung von $ Y = F_ {P} (U) $ gibt, wird mit der Umkehrfunktion $ F_ {p} ^ {-1} $ von $ F_ {p} $ $ U = F_ {p Sie können} ^ {-1} (Y) $ schreiben. Mit dieser Formel können wir sehen, dass wir $ p (y) = du / dy = d (F_ {p} ^ {-1} (y)) / dy $ schreiben können. Tatsächlich denke ich, dass diese Formeltransformation ziemlich schwierig ist. Zumindest auf den ersten Blick ist es schwer zu verstehen. Sie fragen sich vielleicht, warum die Umkehrfunktion angezeigt wird, aber gewöhnen wir uns nach und nach daran, indem wir uns das folgende Beispiel ansehen.
Beispiel: Exponentialverteilung
Die Exponentialverteilungswahrscheinlichkeitsdichtefunktion $ p $ wird durch die folgende Formel ausgedrückt.
Setze $ G (x) = \ int_ {0} ^ {x} p (x) dx $. Durch Differenzieren der integrierten Funktion wird die ursprüngliche Funktion wiederhergestellt, sodass $ dG / dx = p (x) $ gilt. Ich wollte eine Funktion finden, die $ p (y) = d (F_ {p} ^ {-1} (y)) / dy $ erfüllt, also habe ich das Gefühl, dass die Umkehrfunktion von $ G $ $ F $ ist. (Eigentlich so).
Wenn Sie $ G $ konkret berechnen,
import numpy as np
import matplotlib.pyplot as plt
Lambda = 0.1
N = 100000
u = np.random.rand(N)
y = - Lambda * np.log(1 - u)
plt.hist(y, bins=200)
plt.show()
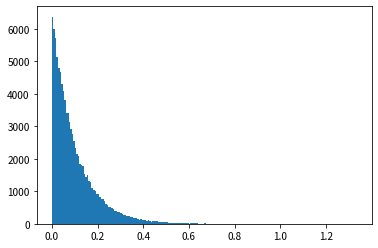
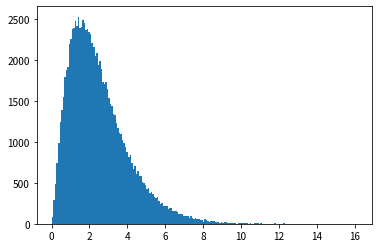
Wenn wir uns die Ergebnisse des Histogramms ansehen, können wir sehen, dass es eine ähnliche Form wie die Wahrscheinlichkeitsdichtefunktion der Exponentialverteilung hat und dass Zufallszahlen erzeugt werden können, die der Exponentialverteilung folgen.
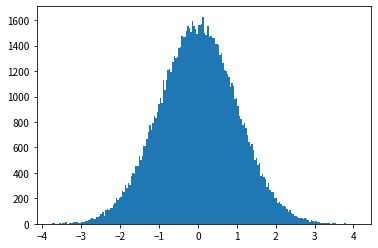
Beispiel: Normalverteilung
Als nächstes werde ich den "Box-Muller-Algorithmus" vorstellen, einen bekannten Algorithmus zum Erstellen von Zufallszahlen mit einer Standardnormalverteilung. Aus der Gleichverteilung $ (z_1, z_2) $ auf einer Platte mit Radius 1
Ich habe die Formel absteigend angegeben, weil ich es aufgegeben habe, diese Formel abzuleiten. ..
Ich habe tatsächlich ein Python-Skript geschrieben, das mit dieser Funktion $ F $ Zufallszahlen generiert.
import numpy as np
import matplotlib.pyplot as plt
N = 100000
z = np.random.rand(N * 2, 2) * 2 - 1
z = z[z[:, 0] ** 2 + z[:, 1] ** 2 < 1]
z = z[:N]
r = z[:, 0] ** 2 + z[:, 1] ** 2
y = z[:, 0] / (r ** 0.5) * ((-2 * np.log(r)) ** 0.5)
plt.hist(y, bins=200)
plt.show()
Cauchy Verteilung
Lassen Sie uns abschließend eine Zufallszahl generieren, die der Cauchy-Verteilung folgt. Cauchy-Verteilungen werden statistisch selten im Vergleich zu Exponential- und Normalverteilungen verwendet. Im nächsten Abschnitt werden im Abschnitt zur Gammaverteilung jedoch Zufallszahlen verwendet, die der Cauchy-Verteilung folgen. Daher werden wir sie hier vorstellen. Die Wahrscheinlichkeitsdichtefunktion der Cauchy-Verteilung wird durch die folgende Formel ausgedrückt.
p(x; c) = \frac{1}{1 + (x - c)^2}
Die kumulative Verteilungsfunktion $ G $ der Cauchy-Verteilung kann einfach wie folgt geschrieben werden, indem die Umkehrfunktion der $ \ tan $ -Funktion namens $ \ arctan $ verwendet wird.
u = G(x) = \int_{-\infty}^{x} p(x; c) = \frac{1}{\pi} \arctan (x - c) + \frac{1}{2}
Daher kann die Umkehrfunktion $ F $ von $ G $ wie folgt geschrieben werden.
F(u) = \tan \bigg(\pi \bigg(u - \frac{1}{2} \bigg)\bigg) + c
Das heißt,
Lassen Sie uns das Ergebnis der tatsächlichen Generierung einer Zufallszahl mit dieser Funktion $ F $ sehen.
cauchy_F = lambda x: np.tan(x * (np.pi / 2 + np.arctan(c)) - np.arctan(c)) + c
N = 100000
u = np.random.rand(N)
y = cauchy_F(u)
y = y[y < 10]
plt.hist(y[y < 10], bins=200)
plt.show()
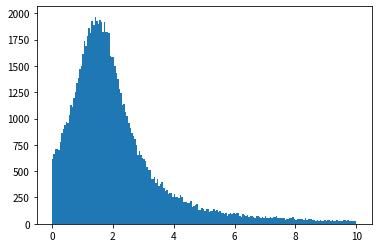
Wenn wir uns die Ergebnisse des Histogramms ansehen, können wir sehen, dass es eine ähnliche Form wie die Wahrscheinlichkeitsdichtefunktion der Exponentialverteilung hat und dass Zufallszahlen erzeugt werden können, die der Exponentialverteilung folgen.
Wenn Sie sich das Skript jedoch genauer ansehen, finden Sie eine Zeile, die Sie interessiert: y = y [y <10].
Wenn Sie diese Zeile entfernen und ausführen, ist dies lächerlich.
Dies bedeutet, dass lächerlich große Ausreißer erzeugt werden können. Dieses Ergebnis ist etwas überzeugend und erinnert an die Tatsache, dass der Mittelwert der Cauchy-Verteilung abweicht.

Wenn ich den Zufallszahlenwert auf 10 oder weniger beschränke, liegt der Durchschnittswert meiner Meinung nach bei 2, aber da extrem große Werte selten auftreten, wurde der Durchschnittswert nach oben verschoben. Ich erinnere mich an die Geschichte, dass das Durchschnitts- und das Durchschnittseinkommen unterschiedlich sind.
Punkte der variablen Konvertierungsmethode
Sie müssen mit den Merkmalen der Distribution vertraut sein. In den meisten Fällen müssen Sie in der Lage sein, die kumulative Verteilungsfunktion in einer einfachen Form zu schreiben. Ich denke, es wäre eine Menge Arbeit, auf andere Weise danach zu fragen. Auch wenn F keine leicht zu berechnende Funktion ist, macht es doch keinen Sinn.
Ablehnungsmethode
Beispiel: Gammaverteilung
Die Wahrscheinlichkeitsdichtefunktion der Gammaverteilung wird durch die folgende Formel ausgedrückt.
p(x; a, b) = b^{a} z^{a-1} \exp(-bz) / \Gamma(a)
Da es schwierig ist, den Wert der $ \ Gamma $ -Funktion zu finden, verwenden wir $ \ tilde {p} $ und ignorieren den $ \ Gamma $ -Teil.
\tilde{p}(x; a) = z^{a-1} \exp(-z)
Lassen Sie uns nun k finden, das die Cauchy-Verteilung überschreitet. Es war mühsam, von Hand zu berechnen, deshalb habe ich mich diesmal auf das Skript verlassen.
gamma_p_tilda = lambda x: (x ** (a - 1)) * np.exp(-x)
cauchy_p = lambda x: 1 / (1 + ((x - c) ** 2)) / (np.pi / 2 + np.arctan(c))
z = np.arange(0, 100, 0.01)
gammas = gamma_p_tilda(z)
cauchys = cauchy_p(z)
k = np.max(gammas / cauchys)
cauchys *= k
plt.plot(z, gammas, label='gamma')
plt.plot(z, cauchys, label='cauchy')
plt.legend()
plt.show()
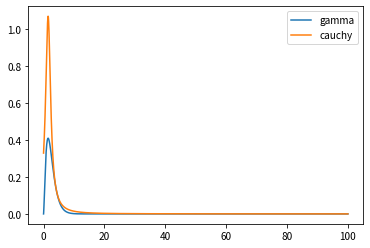
Der im obigen Skript gespeicherte Wert von $ k $ betrug $ 2.732761944808582 $.
N = 100000
u = np.random.rand(N * 3)
y = cauchy_F(u)
u0 = np.random.rand(N * 3)
u0 *= k * cauchy_p(y)
y = y[u0 < gamma_p_tilda(y)]
y = y[:N]
plt.hist(y, bins=200)
plt.show()
Anwendbare Bedingungen für die Ablehnung von Stichproben
Wir brauchen eine vorgeschlagene Verteilung $ Q $, die leicht Zufallszahlen erzeugen kann. Sie müssen auch $ k $ berechnen, das $ kq \ geq p $ erfüllt. Wenn Sie versehentlich den Wert von $ k $ zu stark erhöhen, müssen Sie die generierten Zufallszahlen ablehnen, damit $ k $ so klein wie möglich wird. In diesem Fall ist es jedoch erforderlich, sie aus der konkreten Form der Funktion abzuleiten oder den Wert genau zu berechnen, was eine angemessene Menge an Schwierigkeiten darstellt. Wenn der Wert von $ k $ bestimmt oder berechnet wird, ob er abgelehnt werden soll, wird der Wert der Wahrscheinlichkeitsdichtefunktion sowohl für $ P $ als auch für $ Q $ verwendet, sodass die Wahrscheinlichkeitsdichtefunktion selbst leicht zu berechnen sein muss. Daher kann dieses Verfahren nicht angewendet werden, wenn die Berechnung der Wahrscheinlichkeitsdichtefunktion selbst schwierig ist, beispielsweise in einem Modell, in dem mehrere Variablen eng miteinander verflochten sind.
In Richtung MCMC
Bisher haben wir einen Überblick über Standardtechniken zur Erzeugung von Zufallszahlen gegeben. Wenn Sie es sich ansehen, können Sie sehen, dass die ursprüngliche Wahrscheinlichkeitsverteilung in einer Form vorliegen muss, die bis zu einem gewissen Grad einfach zu handhaben ist.
Es wurde gefunden, dass statistisch wichtige Zufallszahlen wie Normalverteilung, Exponentialverteilung und Gammaverteilung aus einer gleichmäßigen Verteilung erzeugt werden können. Ich denke, dies allein kann viele Dinge bewirken, aber es gibt komplexere Modelle, die den Bayes'schen Ansatz verwenden. Diese Generierungsmethode allein verfügt nicht über genügend Waffen, um dem komplexen Bayes'schen Modell entgegenzuwirken.
Daher kommt ein Algorithmus heraus, der Zufallszahlen für ein komplizierteres Modell namens MCMC erzeugen kann. Das nächste Mal möchte ich das grafische Modell, das der Hauptbereich für die Anwendung von MCMC ist, und die konkrete Methode von MCMC erläutern.