[PYTHON] Reconnaissez votre patron avec Deep Learning et masquez l'écran
Contexte
Lorsque vous êtes au travail, tout le monde consulte des informations non commerciales, n'est-ce pas?
À ce moment-là, je me sens mal à l'aise que ** le patron se faufile derrière moi **. Bien sûr, vous pouvez changer d'écran à la hâte, mais ce type de comportement peut être suspect et vous ne le remarquerez peut-être pas lorsque vous vous concentrez. Ainsi, afin de changer d'écran sans être méfiant, j'ai créé un système qui reconnaît automatiquement que le patron s'approche et cache l'écran.
Plus précisément, Keras </ font> est utilisé pour apprendre par machine le visage du boss, et la caméra est utilisée pour reconnaître qu'il approche et changer d'écran.
Mission
La mission est de changer d'écran automatiquement lorsque le boss approche.
La situation est la suivante.
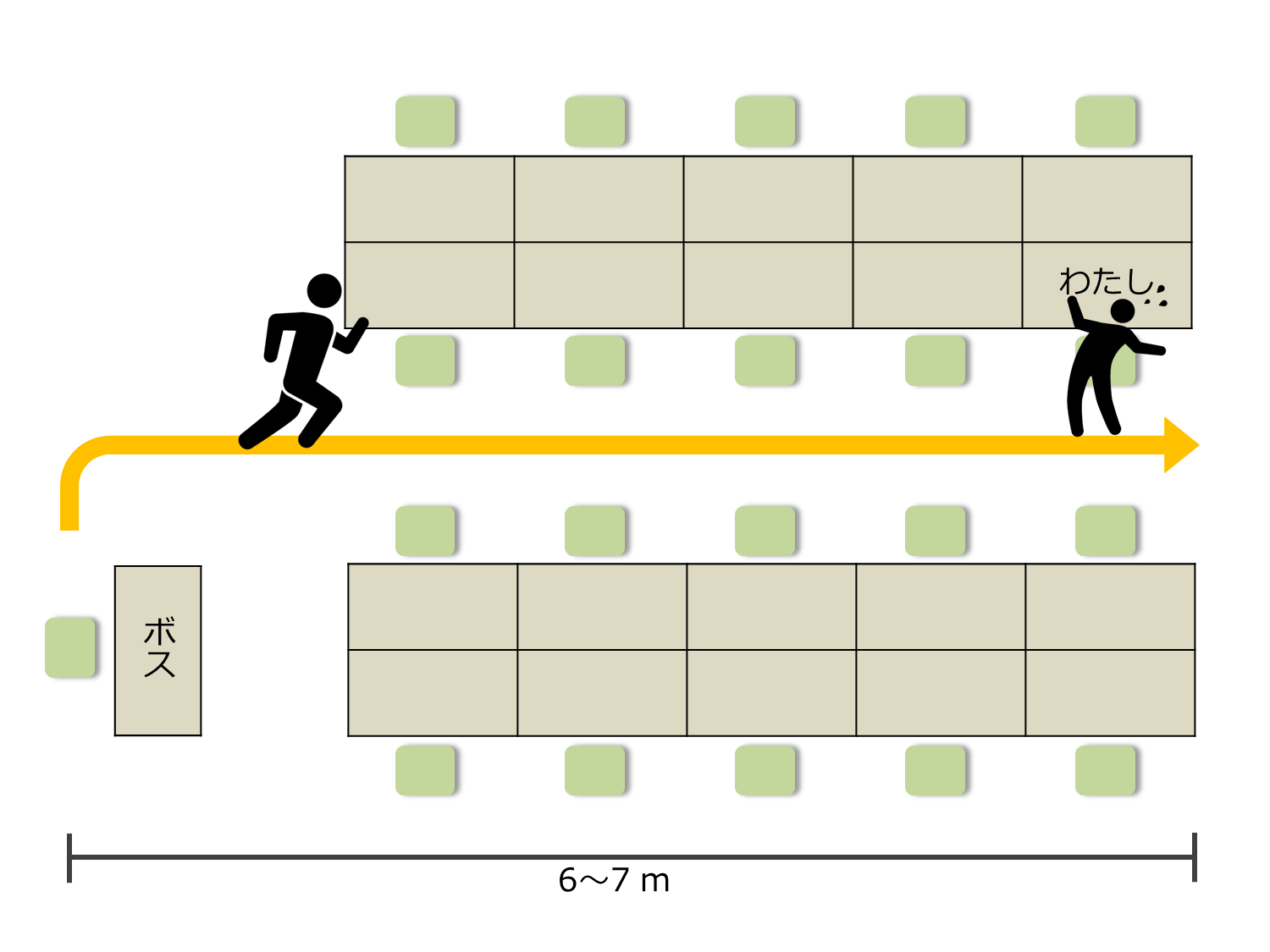
La distance entre le siège du patron et mon siège est d'environ 6,7 m. Il faut 4,5 secondes après que le patron quitte mon siège pour atteindre mon siège. Par conséquent, il est nécessaire de masquer l'écran pendant ce temps. Je n'ai pas beaucoup de temps à perdre.
Stratégie ~ Comment masquer l'écran? ~
Je pense qu'il existe de nombreuses stratégies possibles, mais mon idée est la suivante.
Tout d'abord, utilisez l'apprentissage automatique pour laisser l'ordinateur apprendre à l'avance le visage du patron. Ensuite, installez une caméra Web dans votre siège et changez d'écran lorsque la caméra Web attrape le visage du patron. C'est la stratégie parfaite. Appelons ce merveilleux système "** Boss Sensor **".

Configuration du système de capteur Boss
La configuration système extrêmement simple du capteur de bossage est la suivante.

- Obtenez des images en temps réel à l'aide d'une webcam.
- La détection de visage et la reconnaissance de visage sont effectuées sur l'image acquise à l'aide du modèle d'apprentissage.
- Si le résultat de la reconnaissance est le boss, changez d'écran.
Les techniques suivantes sont nécessaires pour effectuer ces opérations:
- Obtenez l'image du visage
- Reconnaissance d'image de visage
- Changement d'écran
Examinons-les un par un et intégrons-les enfin.
Obtenir l'image du visage
Tout d'abord, récupérez l'image de la caméra Web.
La caméra Web utilisée cette fois-ci est [BUFFALO BSW20KM11BK](https://www.amazon.co.jp/%E3%83%90%E3%83%83%E3%83%95%E3%82%A1%E3 % 83% AD% E3% 83% BC-BSW20KM11BK-iBUFFALO-% E3% 83% 9E% E3% 82% A4% E3% 82% AF% E5% 86% 85% E8% 94% B5200% E4% B8% 87% E7% 94% BB% E7% B4% A0WEB% E3% 82% AB% E3% 83% A1% E3% 83% A9-120% C2% B0% E5% BA% 83% E8% A7% 92% E3% 82% AC% E3% 83% A9% E3% 82% B9% E3% 83% AC% E3% 83% B3% E3% 82% BA% E6% 90% AD% E8% BC% 89% E3% 83% A2% E3% 83% 87% E3% 83% AB / dp / B008AO4KXQ).

Je pense que n'importe quelle caméra Web fera l'affaire tant qu'elle aura des performances.
Vous pouvez obtenir l'image de la caméra avec le logiciel ci-joint, mais compte tenu du traitement ultérieur, il est préférable de l'obtenir à partir du programme. De plus, comme la reconnaissance faciale est effectuée dans le traitement suivant, il est nécessaire de ne découper que l'image du visage. Alors, obtenons l'image du visage en utilisant Python et OpenCV. Voici le code pour cela:
J'ai pu obtenir une meilleure image de visage que ce à quoi je m'attendais.

Apprendre et reconnaître le visage du patron
Utilisez ensuite l'apprentissage automatique pour permettre à l'ordinateur de reconnaître le visage du patron. Les trois points suivants sont une procédure approximative:
- Collection d'images
- Traitement d'image
- Créez un modèle d'apprentissage automatique
Regardons-les un par un.
Collection d'images
Tout d'abord, vous devez obtenir une image pour apprendre. J'ai utilisé la méthode de collecte suivante:
- Recherche d'images Google
- Collectez des images sur Facebook
- Pris avec un appareil photo
Au début, j'ai collecté des images à partir de la recherche sur le Web et de Facebook, mais je n'ai pas eu assez d'images. Par conséquent, j'ai utilisé une caméra vidéo pour filmer une vidéo et j'ai décomposé la vidéo en images.
Traitement d'image
D'ailleurs, j'ai pu acquérir un grand nombre d'images avec des visages, mais je ne peux pas les mettre sur l'appareil d'apprentissage telles quelles. En effet, la partie qui n'a rien à voir avec le visage occupe une grande partie de l'image. Par conséquent, je ne découperai que l'image du visage.
J'ai principalement utilisé ImageMagick pour la découpe. Vous ne pouvez obtenir que l'image du visage en la découpant à l'aide d'ImageMagick.
De nombreuses images de visage ont été collectées comme ceci:

Peut-être suis-je la personne qui possède la plus grande image de visage de patron au monde. Doit avoir plus que les parents.
Vous êtes maintenant prêt à étudier.
Construire un modèle d'apprentissage automatique
L'apprentissage se fait en construisant un réseau neuronal convolutif (CNN) avec Keras. TensorFlow est utilisé pour le back-end de Keras. Si vous voulez juste reconnaître le visage, vous pouvez accéder à l'API Web pour la reconnaissance d'image, mais cette fois j'ai décidé de le faire moi-même en tenant compte des performances en temps réel.
Le réseau a la configuration suivante. Keras est pratique car vous pouvez facilement générer la configuration.
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
convolution2d_1 (Convolution2D) (None, 32, 64, 64) 896 convolution2d_input_1[0][0]
____________________________________________________________________________________________________
activation_1 (Activation) (None, 32, 64, 64) 0 convolution2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_2 (Convolution2D) (None, 32, 62, 62) 9248 activation_1[0][0]
____________________________________________________________________________________________________
activation_2 (Activation) (None, 32, 62, 62) 0 convolution2d_2[0][0]
____________________________________________________________________________________________________
maxpooling2d_1 (MaxPooling2D) (None, 32, 31, 31) 0 activation_2[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 32, 31, 31) 0 maxpooling2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_3 (Convolution2D) (None, 64, 31, 31) 18496 dropout_1[0][0]
____________________________________________________________________________________________________
activation_3 (Activation) (None, 64, 31, 31) 0 convolution2d_3[0][0]
____________________________________________________________________________________________________
convolution2d_4 (Convolution2D) (None, 64, 29, 29) 36928 activation_3[0][0]
____________________________________________________________________________________________________
activation_4 (Activation) (None, 64, 29, 29) 0 convolution2d_4[0][0]
____________________________________________________________________________________________________
maxpooling2d_2 (MaxPooling2D) (None, 64, 14, 14) 0 activation_4[0][0]
____________________________________________________________________________________________________
dropout_2 (Dropout) (None, 64, 14, 14) 0 maxpooling2d_2[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 12544) 0 dropout_2[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 512) 6423040 flatten_1[0][0]
____________________________________________________________________________________________________
activation_5 (Activation) (None, 512) 0 dense_1[0][0]
____________________________________________________________________________________________________
dropout_3 (Dropout) (None, 512) 0 activation_5[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 2) 1026 dropout_3[0][0]
____________________________________________________________________________________________________
activation_6 (Activation) (None, 2) 0 dense_2[0][0]
====================================================================================================
Total params: 6489634
Le code est ici:
Si vous pouvez le faire jusqu'à présent, vous pouvez le reconnaître comme un boss lorsque le boss apparaît sur la caméra.
Changement d'écran
Maintenant, après avoir reconnu le visage du boss à l'aide du modèle entraîné, nous devons changer d'écran. Cette fois, préparons et affichons simplement une image du style de travail. Puisque je suis programmeur, j'ai préparé les images suivantes.

C'est comme travailler. Tout ce que vous avez à faire est d'afficher cette image.
Je veux afficher l'image en plein écran, je vais donc l'afficher en utilisant PyQt. Voici le code pour cela:
Maintenant, tout est prêt.
Achevée
Il est terminé lorsque les technologies vérifiées jusqu'à présent sont combinées. Je l'ai essayé.
"Le patron a quitté son siège. Il s'approche de mon siège."

"OpenCV a détecté le visage. Il jette l'image dans le modèle d'apprentissage."

"En toute sécurité, j'ai reconnu que j'étais le chef et l'écran a changé. ヽ (‘ ∇ ’) Maintenant

Réflexion
Avec autodiscipline.
Même si la précision de l'image de l'ensemble de test était élevée, l'image acquise par la caméra Web était parfois difficile à reconnaître. Il semble que cela soit lié au degré de frappe de la lumière et au flou de l'image. Je dois faire une normalisation d'image correctement.
La classification était une classification binaire du patron ou d'une autre personne, mais lorsqu'une image autre que l'image du visage était entrée, elle était parfois classée comme un patron. Si quoi que ce soit, c'était un patron. Il aurait peut-être été préférable de reconnaître l'utilisation de la probabilité d'être un patron plutôt que la classification binaire.
Le traitement de l'image est difficile.
Code source
Vous pouvez télécharger le code source à partir des référentiels suivants.
en conclusion
Cette fois, j'ai essayé de reconnaître le boss et de cacher l'écran en combinant l'acquisition d'images en temps réel de la caméra Web et la reconnaissance faciale à l'aide de Keras.
Actuellement, j'utilise OpenCV pour la détection de visage, mais je pense que la précision de la détection de visage avec OpenCV n'est pas bonne, donc j'aimerais améliorer ce domaine en utilisant Dlib. J'aimerais utiliser un modèle de détection de visage que j'ai formé moi-même.
J'utilisais PyQt pour afficher l'image du vent sur laquelle je travaillais, mais cela prend beaucoup de temps entre la commande et l'affichage, je dois donc améliorer cette zone.
La précision de reconnaissance des images acquises à partir de la caméra Web n'est pas suffisante, je voudrais donc l'améliorer de temps en temps.
La réalité n'était pas douce
Recommended Posts