[PYTHON] Deep Learning avec Shogi AI sur Mac et Google Colab Chapitre 11
Technique d'apprentissage
Apprentissage ordinaire
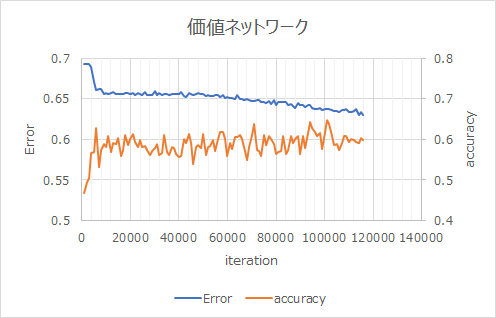
Résultats d'apprentissage du réseau de valeur au chapitre 10.
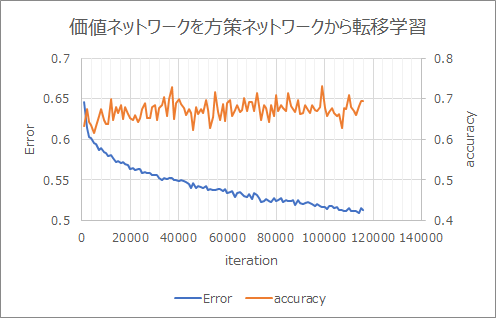
Apprentissage par transfert
Apprendre en transférant les résultats d'apprentissage du réseau politique. L'erreur était faible et la précision était élevée.
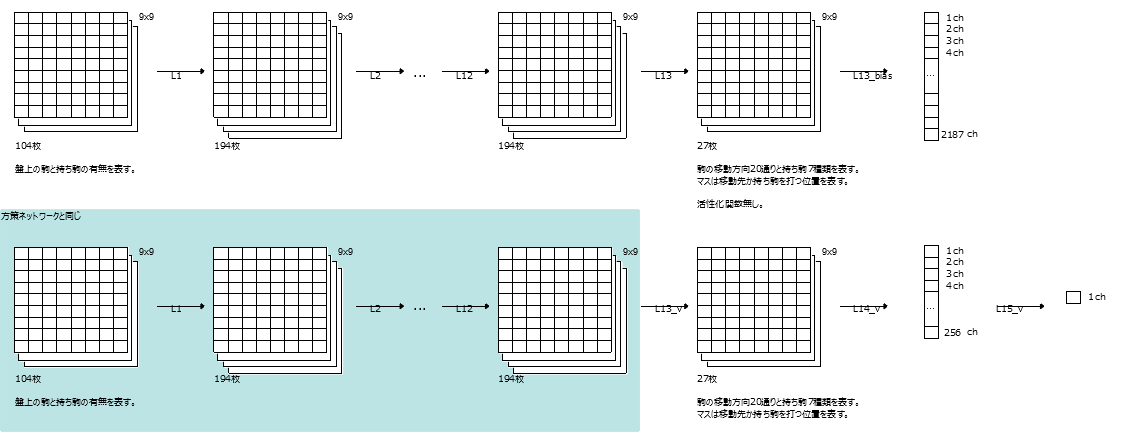
Apprentissage multi-tâches
La ligne supérieure est Chapter 7 Policy Network
La rangée du bas est Chapter 10 Value Network
L'idée de l'apprentissage multi-tâches est de le rendre commun car les parties bleu clair sont les mêmes.
 C'est ce qui se passe lorsque le bleu clair est normalisé.
C'est ce qui se passe lorsque le bleu clair est normalisé.
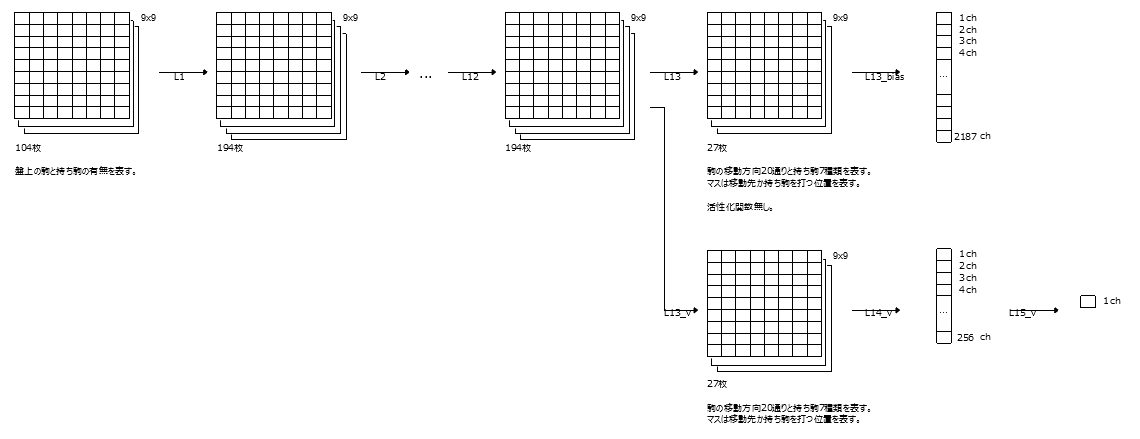
Vous pouvez apprendre les politiques et les valeurs en même temps. La précision est également bonne.
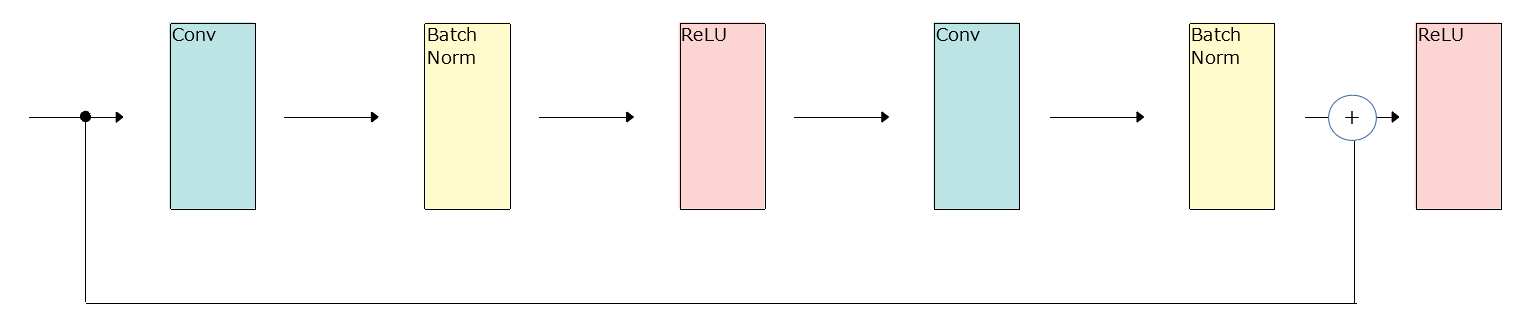
Residual Network Il semble que la configuration appelée ResNet soit bonne. Je ne comprends pas pourquoi ResNet est bon, mais il semble que la recherche progresse.
1 bloc de ResNet
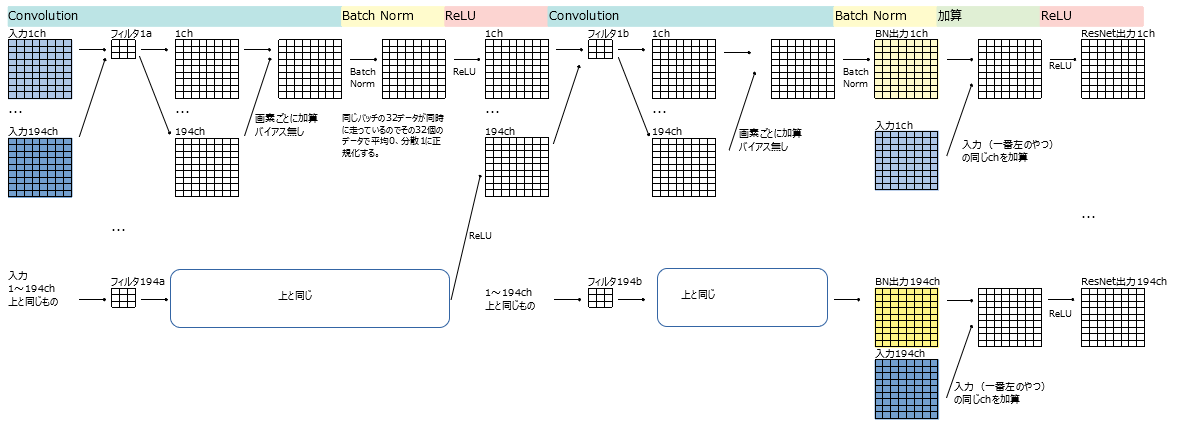
Détails d'un bloc de ResNet
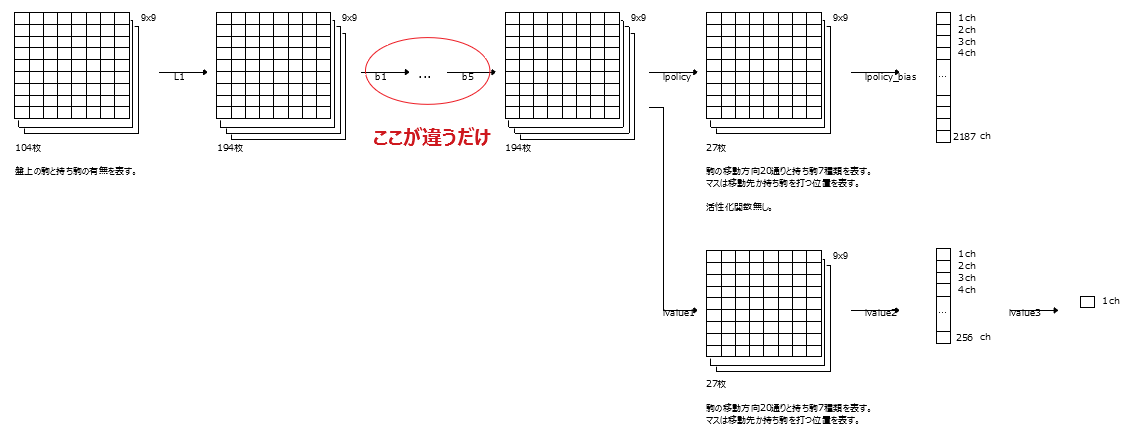
Connectez 5 blocs ResNet et remplacez-les par L2 à L12 pour l'apprentissage multitâche.
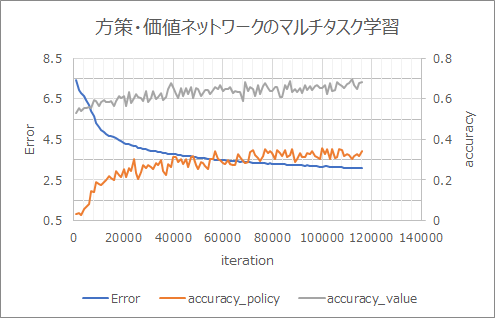
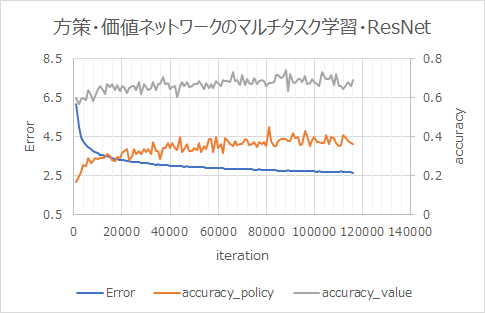
Résultat d'apprentissage
L'apprentissage progresse plus vite que sans ResNet.
policy_value_resnet.py
x + h2 x + h2 est l'opération d'ajout de x et h2 "élément par élément". (Quand j'ai imprimé la valeur, c'était comme ça)
def __call__(self, x):
h1 = F.relu(self.bn1(self.conv1(x)))
h2 = self.bn2(self.conv2(h1))
return F.relu(x + h2)
h = self['b{}'.format(i)](h) Cette façon d'écrire signifie self.bi (h).
for i in range(1, self.blocks + 1):
h = self['b{}'.format(i)](h)
pydlshogi/network/policy_value_resnet.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from chainer import Chain
import chainer.functions as F
import chainer.links as L
from pydlshogi.common import *
ch = 192
fcl = 256
class Block(Chain):
def __init__(self):
super(Block, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn1 = L.BatchNormalization(ch)
self.conv2 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1, nobias=True)
self.bn2 = L.BatchNormalization(ch)
def __call__(self, x):
h1 = F.relu(self.bn1(self.conv1(x)))
h2 = self.bn2(self.conv2(h1))
return F.relu(x + h2)
# x +Lorsque h2 a imprimé la valeur et l'a confirmée, x et h2 ont été ajoutés élément par élément. En d'autres termes, x, h2 et x + h2 sont 194 éléments.
#J'avais peur que le premier sentiment soit 388 éléments, alors je l'ai vérifié, mais F.Cela signifie-t-il que chaque élément est ajouté dans relu?
class PolicyValueResnet(Chain):
def __init__(self, blocks):
super(PolicyValueResnet, self).__init__()
self.blocks = blocks
with self.init_scope():
self.l1 = L.Convolution2D(in_channels = 104, out_channels = ch, ksize = 3, pad = 1)
for i in range(1, blocks + 1):
self.add_link('b{}'.format(i), Block()) #Le premier argument est le nom et le deuxième argument est la classe
# policy network
self.lpolicy = L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1, nobias = True)
self.lpolicy_bias = L.Bias(shape=(9*9*MOVE_DIRECTION_LABEL_NUM))
# value network
self.lvalue1 = L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1)
self.lvalue2 = L.Linear(9*9*MOVE_DIRECTION_LABEL_NUM, fcl)
self.lvalue3 = L.Linear(fcl, 1)
def __call__(self, x):
h = F.relu(self.l1(x))
for i in range(1, self.blocks + 1):
h = self['b{}'.format(i)](h) #Cette façon de s'écrire.b Combien.
# policy network
h_policy = self.lpolicy(h)
policy = self.lpolicy_bias(F.reshape(h_policy, (-1, 9*9*MOVE_DIRECTION_LABEL_NUM)))
# value network
h_value = F.relu(self.lvalue1(h))
h_value = F.relu(self.lvalue2(h_value))
value = self.lvalue3(h_value)
return policy, value
Recommended Posts