[PYTHON] Introduction à la modélisation statistique pour l'analyse des données
Pour ma propre étude. L'intérieur est écrit en R, je vais donc le réécrire en Python et faire de mon mieux. Les commentaires dans le code sont en langage R.
2.1 Exemple: modélisation statistique des nombres de graines
Il semble que R dispose de données de comptage pour le nombre de graines.
Je pense qu'il vaut mieux utiliser numpy et pandas pour le traitement.
Les données sont également préparées pour chacun des «numpy.array» et «pandas.Series».
Aussi pyplot pour les graphiques.
>>> data = [2, 2, 4, 6, 4, 5, 2, 3, 1, 2, 0, 4, 3, 3, 3, 3, 4, 2, 7, 2, 4, 3, 3, 3, 4, 3, 7, 5, 3, 1, 7, 6, 4, 6, 5, 2, 4, 7, 2, 2, 6, 2, 4, 5, 4, 5, 1, 3, 2, 3]
>>> import numpy
>>> import pandas
>>> matplotlib.pyplot as plt
>>> ndata = numpy.asarray(data)
>>> pdata = pandas.Series(data)
Le nombre de graines est de 50.
# length(data)
>>> len(data)
50
>>> len(ndata)
50
>>> len(pdata)
50
Pour afficher la moyenne de l'échantillon, la valeur minimale, la valeur maximale, le numéro de quadrant, etc. de données
# summary(data)
>>> pdata.describe()
count 50.00000
mean 3.56000
std 1.72804
min 0.00000
25% 2.00000
50% 3.00000
75% 4.75000
max 7.00000
dtype: float64
Obtenir la distribution de fréquence
# table(data)
>>> pdata.value_counts()
3 12
2 11
4 10
5 5
7 4
6 4
1 3
0 1
dtype: int64
On peut confirmer que le nombre de graines est de 5 et le nombre de graines de 6.
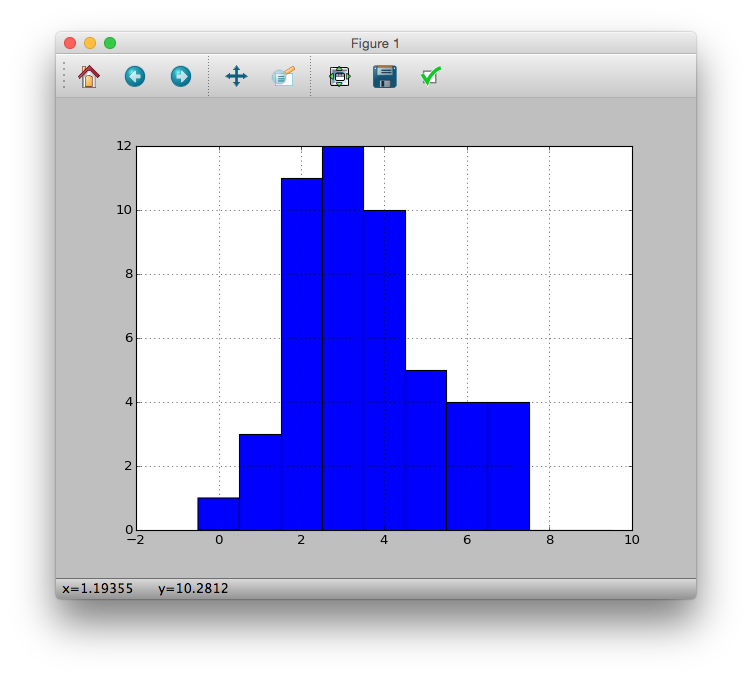
Afficher ceci sous forme d'histogramme
# hist(data, breaks = seq(-0.5, 9.5, 1))
>>> pdata.hist(bins=[i - 0.5 for i in xrange(11)])
<matplotlib.axes._subplots.AxesSubplot object at 0x10f1a9a10>
>>> plt.show()
Calcul de la statistique «variance d'échantillon» qui représente la variation des données. Il semble que la méthode de calcul de la distribution par défaut soit différente entre numpy et pandas. (Référence) En passant, dans le cas de R, il semble que ce soit une estimation sans biais.
# var(data)
>>> numpy.var(ndata) #Exemple de statistiques
2.9264000000000006
>>> numpy.var(ndata, ddof=True) #Estimation impartiale
2.9861224489795921
>>> pdata.var() #Estimation impartiale
2.986122448979593
>>> pdata.var(ddof=False) #Exemple de statistiques
2.926400000000001
L'écart type semble se comporter de la même manière que la dispersion. Cette fois, seul l'exemple des pandas.
# sd(data)
>>> pdata.std()
1.7280400600042793
# sqrt(var(data))
2.2 Examen de la correspondance entre les données et la distribution de probabilité
On peut voir que les données de numéro de graine ont les caractéristiques suivantes.
--Compte des données pouvant être comptées comme un, deux, ...
- Le nombre moyen de graines par individu est de 3,56 $ ――Il existe des variations dans le but de chaque individu, et si vous dessinez un histogramme, ce sera une distribution de montagne.
La ** distribution de probabilité ** est utilisée pour représenter la variation. Pour représenter les données du nombre de graines sous forme de modèle statistique Cette fois, il semble que la ** distribution de Poisson ** soit utilisée.
Le nombre de graines $ y_i $ d'un certain individu $ i $ est appelé ** variable de probabilité **.
Quelle est la probabilité que le nombre de graines dans un individu 1 soit $ y_1 = 2 $?
La distribution de probabilité qui s'exprime est définie par une formule mathématique relativement simple et sa forme est déterminée par les paramètres.
Dans le cas de la distribution de Poisson, le seul paramètre est la ** moyenne de la distribution **.
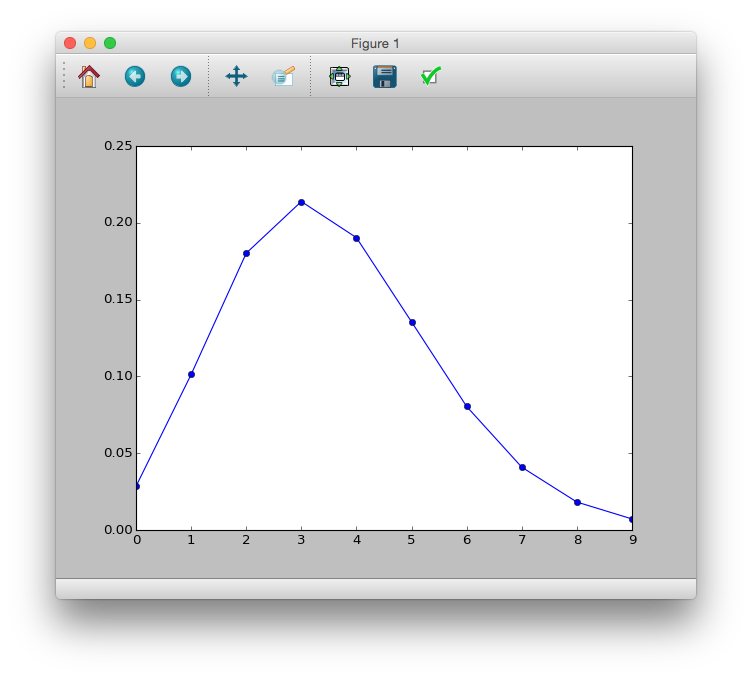
Dans cet exemple, la distribution de Poisson a une moyenne de 3,56 $. Quant à la relation de distribution, «scipy» semble être bonne.
# y <- 0:9
# prob <- dpois(y, lambda = 3.56)
# plot(y, prob, type="b", lyt=2)
>>> import scipy.stats as sct
>>> y = range(10)
>>> prob = sct.poisson.pmf(y, mu=3.56)
>>> plt.plot(y, prob, 'bo-')
>>> plt.show()
Superposition avec des données réelles
>>> pdata.hist(bins=[i - 0.5 for i in range(11)])
>>> pandas.Series(prob*50).plot()
>>> plt.plot()
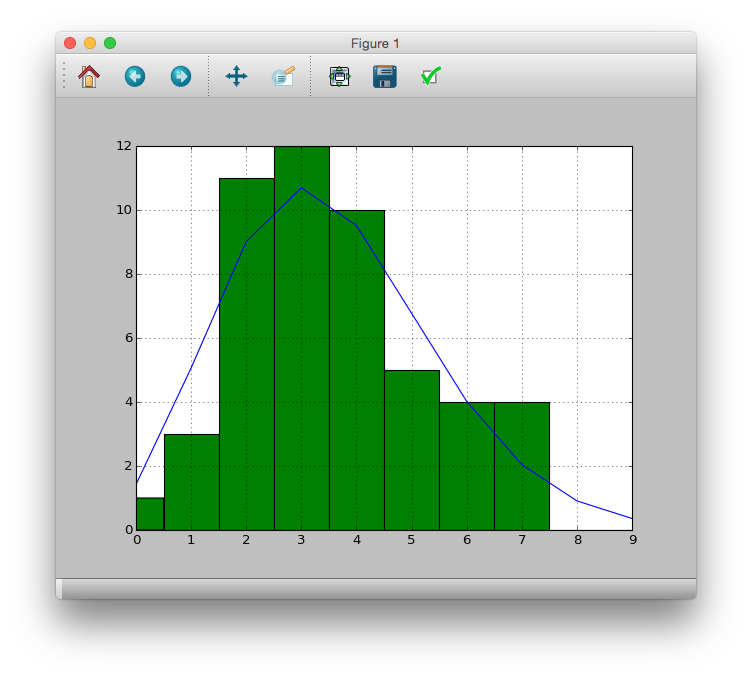
A partir de ce résultat, on considère que les données d'observation peuvent être exprimées par la distribution de Poisson.
2.3 Qu'est-ce que la distribution de Poisson?
Un peu plus de détails sur la distribution de Poisson.
Définition de la distribution de Poisson
Probabilité lorsque la moyenne est $ \ lambda $ Probabilité lorsque la variable est $ y $
p(y|\lambda) = \frac{\lambda ^{y}\exp(-\lambda)}{y!}
la nature
-La forme de la courbe change en fonction de la valeur de $ \ lambda $ -Prendre la valeur de $ y \ dans $ {$ 0, 1, 2, \ dots, \ infty $} et pour tout $ y $
\sum^{\infty}_{y=0}p(y|\lambda) = 1
- La moyenne de la distribution de probabilité est $ \ lambda $ ($ \ lambda \ geq 0 $)
- La distribution et la moyenne sont égales
Raisons du choix de la distribution de Poisson cette fois
- La valeur $ y_i $ contenue dans les données est un entier non négatif (compter les données)
- $ y_i $ a une limite inférieure (0) mais pas de limite supérieure
- La moyenne et la variance des données observées sont presque égales
2.4 Estimation la plus probable des paramètres de distribution de Poisson
Méthode d'estimation la plus probable
Une méthode pour déterminer la «qualité de l'ajustement» d'un modèle appelé ** vraisemblance **.
Dans le cas de la distribution de Poisson, déterminez $ \ lambda $.
Le produit de la probabilité $ p (y_i | \ lambda) $ pour tout individu $ i $ quand un certain $ \ lambda $ est déterminé
La vraisemblance s'écrit $ L (\ lambda) $. Dans ce cas,
\begin{eqnarray*}
L( \lambda ) &=& (y_Probabilité que 1 soit 2) \times (y_Probabilité que 2 soit 2) \times \dots \times (y_Probabilité que 50 soit 3)\\
&=& p(y_1 | \lambda) \times p(y_2 | \lambda) \times p(y_3 | \lambda) \times \dots \times p(y_50 | \lambda)\\
&=& \prod_{i}p(y_i | \lambda) = \prod_{i} \frac{\lambda^{y_i} \exp (-\lambda)}{y_i !}
\end{eqnarray*}
Il devient. Le produit est utilisé pour calculer la probabilité que 50 individus soient identiques à l'observation (= la probabilité que 50 événements soient vrais).
Comme il est difficile d'utiliser la fonction de vraisemblance $ L (\ lambda) $ telle quelle, la ** fonction de vraisemblance log ** est généralement utilisée.
\begin{eqnarray*}
\log L(\lambda) &=& \log \left( \prod_{i} \frac{\lambda^{y_i} \exp (-\lambda)}{y_i !} \right) \\
&=& \sum_i \log \left( \frac{\lambda^{y_i} \exp (-\lambda)}{y_i !} \right) \\
&=& \sum_i \left( \log(\lambda^{y_i} \exp (-\lambda)) - \log y_i ! \right)\\
&=& \sum_i \left( y_i \log \lambda - \lambda - \sum^{y_i}_{k} \log k \right)
\end{eqnarray*}
Représentez graphiquement la relation entre cette vraisemblance logarithmique $ \ log L (\ lambda) $ et $ \ lambda $.
# logL <- function(m) sum(dpois(data, m, log=TRUE))
# lambda <- seq(2, 5, 0.1)
# plot(lambda, sapply(lambda, logL), type="l")
>>> logL = lambda m: sum(sct.poisson.logpmf(data, m))
>>> lmd = [i / 10. for i in range(20, 50)]
>>> plt.plot(lmd, [logL(m) for m in lmd])
>>> plt.show()
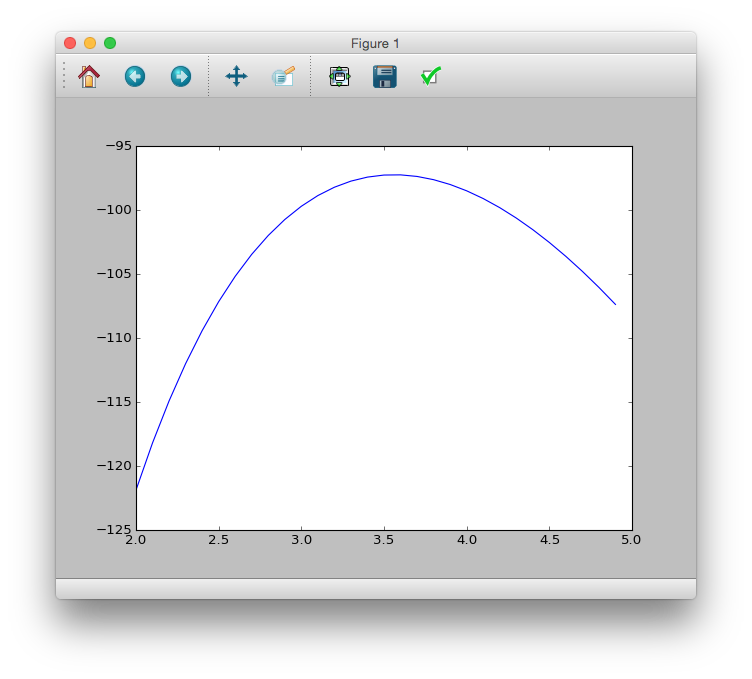
Log de vraisemblance $ \ log L (\ lambda) $ est une fonction monotone croissante de vraisemblance $ L (\ lambda) $ Lorsque la probabilité logarithmique est maximale, la probabilité est également maximale.
En regardant le graphique, vous pouvez voir que la probabilité la plus élevée se situe autour de $ \ lambda = 3,5 $.
La valeur maximale spécifique peut être la valeur maximale de la vraisemblance logarithmique (= lorsque la pente devient 0).
En d'autres termes
\begin{eqnarray*}
\frac{\partial \log L(\lambda)}{\partial \lambda} = \sum_i \left\{ \frac{y_i}{\lambda} - 1 \right\} = \frac{1}{\lambda} \sum_i y_i - 50 &=& 0 \\
\lambda &=& \frac{1}{50}\sum_i y_i \\
&=& \frac{Tout y_je somme}{Le nombre de données}(=Exemple de moyenne de données) \\
&=& 3.56
\end{eqnarray*}
Le $ lambda $ qui maximise la vraisemblance logarithmique et la vraisemblance est appelé ** l'estimation la plus probable **, et le $ \ lambda $ évalué par le $ y_i $ spécifique est appelé ** l'estimation la plus probable **. ..
Généralisation
Soit $ p (y_i | \ theta) $ la probabilité que les données d'observation $ y_i $ soient générées à partir de la distribution de probabilité avec $ \ theta $ comme paramètre. Probabilité, vraisemblance logarithmique
\begin{eqnarray*}
L(\theta | Y) &=& \prod_i p(y_i | \theta) \\
\log L(\theta | Y) &=& \sum_i \log p(y_i | \theta)
\end{eqnarray*}
Il devient.
Comment choisir une distribution de probabilité
Considérez les points suivants.
―― La quantité que vous voulez expliquer est-elle discrète ou continue? ―― Quelle est la fourchette du montant que vous souhaitez expliquer? ―― Quelle est la relation entre la moyenne de l'échantillon et la variance de l'échantillon du montant que vous voulez expliquer?
À titre d'exemple de la distribution utilisée dans le modèle statistique des données de dénombrement:
- ** Distribution de Poisson **: Les données sont une valeur discrète, plage au-dessus de zéro, pas de limite supérieure, distribution moyenne $ \ approx $
- ** Distribution binaire **: Les données sont une valeur discrète, plage finie $ \ {0, 1, 2, \ dots, N } $ au-dessus de zéro, la variance est une fonction de la moyenne
Pour une distribution continue
- ** Distribution normale **: les données sont continues, la plage est $ [- \ infty, + \ infty] $, la variance est déterminée indépendamment de la moyenne
- ** Distribution gamma **: les données sont une valeur continue, la plage est $ [0, + \ infty] $, la variance est une fonction de la moyenne
- ** Distribution uniforme **: les données sont une valeur continue, bornée
Vient ensuite le Modèle linéaire généralisé (GLM).
Recommended Posts