Note de lecture: Introduction à l'analyse de données avec Python
C'est un mémo que je me suis fait prendre en lisant l'introduction à l'analyse des données par Python. Je préfère courir avec Pycharm sur IPython. J'ajoute en lisant. Je suis un débutant dans la programmation elle-même, et je suis coincé à divers endroits, donc je l'écris comme référence pour ceux qui apprendront de la même manière plus tard et comme référence quand je l'oublierai.
environnement ・ Windows 10 (64 bits) ・ Python3.5 (Anaconda) ・ Pandas 0.18.1 ・ Analyse des données par Python, première édition, deuxième impression référence ・ Version anglaise du tableau correct / incorrect * Ce serait bien si O'Reilly Japan pouvait le traduire et le publier. Donc vous ne le ferez jamais. ・ 2016/06/11 J'ai remarqué que https://github.com/wesm/pydata-book N'est-il pas préférable de l'utiliser?
Chapitre 2
P.22, 23 usa.gov Fuseau horaire supérieur de l'apparence des données
Que vous l'exécutiez en IPython ou dans un environnement de développement intégré,
import matplotlib.pyplot as plt
import pandas as pd
Mis en œuvre. plt et pd sont la liberté personnelle, mais il existe une convention selon laquelle ils sont plt et pd. numpy est np.
Lors de l'affichage de graphiques dans un environnement de développement intégré
var=tz_counts[:10].plot(kind="barh", rot=0)
plt.show(var)
J'ai écrit ça et ça a marché.
Séparément
tz_counts[:10].plot(kind="barh", rot=0)
plt.show()
Mais ça semble bien. Si vous tracez avec plusieurs données puis plt.show (), plusieurs graphiques seront affichés en même temps.
Utilisez des sous-graphiques pour afficher plusieurs graphiques côte à côte. S'il s'agit d'un livre, il apparaîtra à la page 45. Pour plus d'informations sur matplotlib, voir ici.
P.37 pivot_table Dans pivot_table, les lignes et les cols apparaissent, mais à partir du 28 mai 2016, une erreur (TypeError: pivot_table () a un argument de mot clé inattendu'rows ') se produit. Selon ici ・ Lignes à indexer, ・ Cols en colonnes, Cela peut être évité en le modifiant. Cela résout le problème dans mon environnement. Une édition similaire est requise lorsque pivot_table apparaît après P.37 (P.44 et P.49).
- Comme indiqué dans la réponse vers la fin de ici, il a été changé pour utiliser l'index et les colonnes l'année dernière. Etat.
p.39 Description de get_top1000
À partir du 06/04/2016, il y aura un avertissement indiquant que group.sort_index doit être remplacé par group.sort_values. Je l'ai changé en valeurs tranquillement.
P.40 Dessin graphique de nom
J'utilise Pycharm au lieu d'IPython, mais comme dans le livre, où je crée un sous-ensemble et le trace, selon le livre,
subset = total_births[['John', 'Harry', 'Mary', 'Marilyn']]
var = subset.plot(subplots=True, figsize=(12, 10), grid=False, title = "Number of births per year")
plt.show(var)
Ensuite, ValueError: La valeur de vérité d'un tableau avec plus d'un élément est ambiguë. Utilisez a.any () ou a.all () s'affiche. Il doit y avoir une bonne raison pour laquelle cela est affiché, mais pour le moment, je ne comprends pas.
Pour le moment, en changeant plt.show (var) en plt.show (var.all ()), j'ai pu dessiner un graphique qui ressemble à un livre.
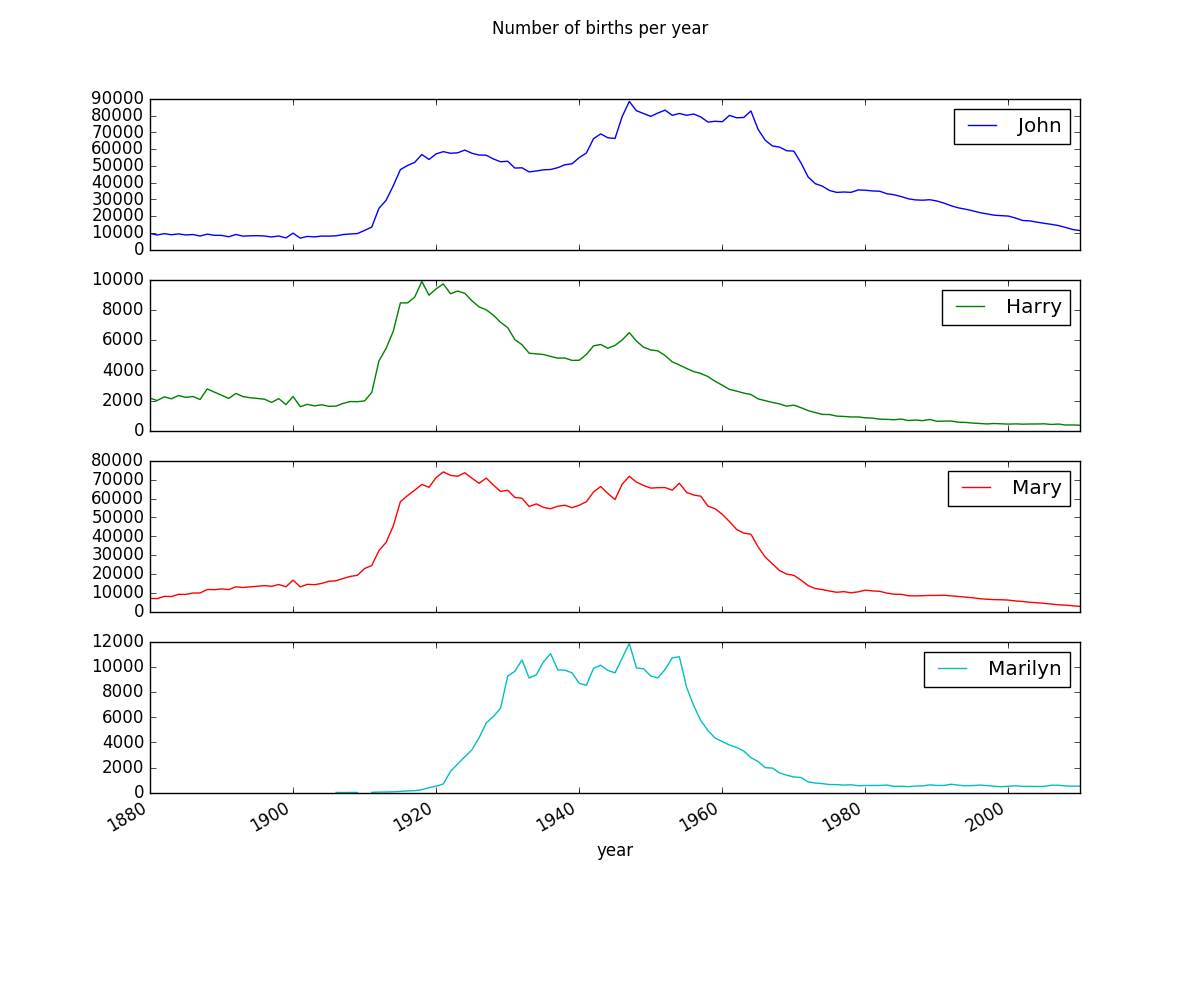
J'ai mis à jour le package individuellement le 2016/06/03 où ce graphique est affiché, et lorsque je l'ai ré-exécuté, une erreur s'est produite. Donc, comme il est rétrogradé lors de l'exécution de conda update --all
・ Hdf5 1.8.16-> 1.8.15.1
・ Numexpr 2.6.0-> 2.5.2
・ Numpy 1.11.0-> 1.10.4
Après cela, j'ai pu à nouveau afficher le graphique. Apparemment, il est acceptable de mettre à jour numpy et numexpr séparément, mais si vous définissez numpy sur 1.11.0 puis numexpr sur 2.6.0, SyntaxError: (erreur unicode) le codec 'unicodeescape' ne peut pas décoder les octets en position 2-3: Une erreur apparaît comme \ UXXXXXXXX d'échappement tronquée, donc il semble y avoir un problème avec cette combinaison.
P.41 Figure 2-6 Dessin de la somme de table1000.prop par année et par sexe
Puisque np.linspace (0, 1.2, 13) est décrit, il est nécessaire de ʻimport numpy as np`.
De plus, il semble que la tendance du ratio à diminuer soit plus remarquable lors du dessin du top 100 que lors du dessin du top 1000.
Pour le moment, l'importation est
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
Est-ce un bon sentiment de le garder?
P.43 get_quantile_count() En raison des changements dans les spécifications de l'API, il est nécessaire de décrire comme suit.
def get_quantile_count(group, q=0.5):
group = group.sort_values(by='prop', ascending=False)
return group.prop.cumsum().values.searchsorted(q) + 1
Group.prop.cumsum (). Values.searchsorted (q) est la partie modifiée.
chapitre 3
Autour de P.52 randn ()
Lors de l'exécution autre qu'IPython comme Pycharm, importez
import numpy as np
import pandas as pb
import matplotlib.pyplot as plt
Ensuite, randn () est décrit comme np.random.randn (). En P.61, np.random.randn () est utilisé, il peut donc être nécessaire de le modifier ici. Il est également décrit dans le tableau d'exactitude sur le site anglais.
- Dans le notebook Jupyter qui peut être téléchargé à partir de github, l'importation est import numpy.random en tant que randn. C'est un peu déroutant car la notation n'est pas unifiée, mais je me demande si ce livre ne concerne pas l'apprentissage de Python lui-même.
P.58 Bloc-notes HTML IPython
Maintenant, ça s'appelle Jupyter.
P.59 Utilisation d'IPython à partir d'éditeurs et d'EDI
Pycharm vous permet également de créer et d'exécuter des blocs-notes Jupyter. Il peut être créé de la même manière qu'un fichier .py. Jusqu'à présent, je n'ai trouvé aucun sens à Pycharm. Y a-t-il une fonction utile? Depuis le 06/04/2016, vous ne pouvez pas voir le résultat de % magic ou% reset? Même si vous l'exécutez depuis Pycharm.
Dans le cas de Pycharm, la version payante (Professional Edition) est nécessaire pour calculer la vitesse de traitement.
Chapitre 4
P.90 data Puisque les données apparaissent soudainement,
data = np.random.randn(2, 3)
Je l'ai interprété comme, et confirmé le processus de multiplication par 10 et de l'ajout. Inutile de dire qu'il fonctionne sur Pycharm, donc
def main():
data = np.random.randn(2, 3)
print('data is\n', data)
print('data*10 is\n', data * 10)
print('data+data is\n', data + data)
if __name__ == '__main__':
main()
Il est décrit comme. Il peut être plus facile d'utiliser IPython docilement ici.
P.95 Définition de numeric_strings
Il y a numeric_strings = np.array (['1.25', '- 9.6', '42'], dtype = np.string_), mais numeric_strings = np.array (['1.25', '- 9.6', '- 9.6', '42']) N'est-ce pas inutile?
Je ne sais pas pourquoi j'ose le préciser ici. Le résultat de numeric_strings.dtype changera.
P.99 Tableau tridimensionnel
Je suis resté coincé en disant que ʻarr3d [0] ʻest une matrice 2x3. Considérant la direction x (ligne) y (colonne) direction z,
J'ai compris que ʻarr3d [z] [x] [y] = arr3d [z, x, y] . Le résultat de np.shape (arr3d)` pourrait également être compris en l'interprétant comme (z, ligne, colonne).
Est-il naturel que l'ordre ne soit pas x, y, z? Est-il naturel de parler une autre langue? Je suis confus car c'est la première fois que je prends au sérieux un tableau 3D en Python.
P.101 Définition des noms
Comme décrit dans le livre
names = np.array(['Bob','Joe', 'Will', "Bob", "Will", "Joe", "Joe"], dtype='|S4')
Alors ça ne marche pas. En premier lieu, je ne comprends pas ce que je fais.
Pour le moment,
names = np.array(['Bob','Joe', 'Will', "Bob", "Will", "Joe", "Joe"])
Cela fonctionne normalement, alors je vais le faire. Il y a une traduction appropriée dans la définition de «données». Je ne sais pas pourquoi c'est ici et il n'y a rien d'autre.
P.106 arr = np.arange(16).reshape((2,2,4)) 2 = direction z 2 = x direction = ligne 4 = direction y = colonne Je pourrais le comprendre.
ʻArr.transpose ((1,0,2) `change ce qui était à l'origine de l'ordre de 0,1,2 à 1,0,2, c'est-à-dire si vous le considérez comme l'échange de l'axe z et de l'axe x, Le point de vue de ʻarr.transpose (1,0,2) ʻest
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])
J'ai compris ça.
p.107 swapaxes ʻArr.swapaxes (1,2) `peut être compris en pensant que l'axe des z = 0, l'axe des x = 1, l'axe des y = 2 et que l'axe des x et l'axe des y sont interchangés.
Il est étrange que ʻarr.swapaxes (2,1) ʻ ne soit pas la même chose, et considérant que arr est 2x2x3, par exemple, ʻarr.swapaxes (2,3) serait une erreur, ʻarr.swapaxes Je pensais que (2,2) ne change rien, mais cela ne devrait pas causer d'erreur, et quand je l'ai essayé, ça l'était, donc je ne pouvais pas le confirmer quelque part. J'ai fait.
P.108 randn
Je l'ai rencontré sur la page précédente, et il y avait une traduction dans l'apparence précédente, donc je pense qu'il n'y a pas de problème,
ʻSi vous importez numpy en tant que np, vous obtiendrez une erreur sauf si vous écrivez np.random.randn (8) `.
P.111 Diagramme des valeurs possibles de la fonction sqrt (x ^ 2 + y ^ 2)
Au début, je prévoyais de l'exécuter avec Pycharm, mais cela devenait de plus en plus gênant, et je me suis retrouvé coincé parce que je l'exécutais avec IPython (Juypter Notebook).
J'avais peur que le graphique ne soit pas affiché même si je le saisissais conformément au livre, mais c'était juste
Tout ce que j'avais à faire était plt.show ().
Cependant, je pensais que le graphique serait affiché en ligne comme Mathematica, donc le comportement était inattendu (⇒ Si vous entrez% matplotlib en ligne, il sera affiché en ligne). Aussi, c'est un peu surprenant de pouvoir insérer des formules au format TeX dans le titre du graphe.
En fin de compte, cela ressemble à ceci pour bien s'afficher sur le notebook Jupyter.
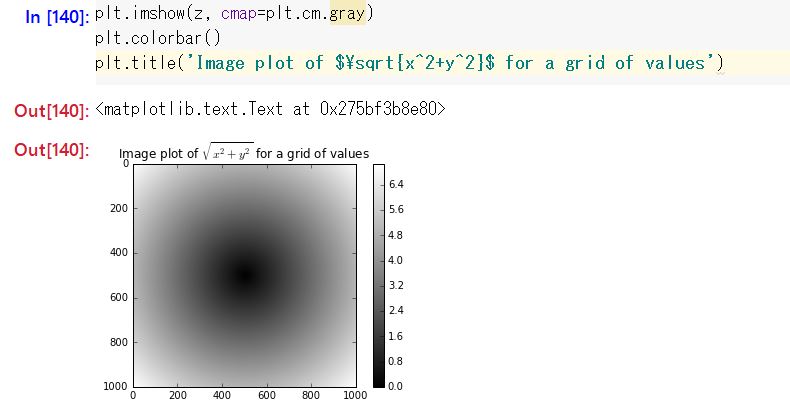
De plus, le graphique gris n'est pas intéressant, j'ai donc essayé de faire plt.imshow (z, cmap = plt.cm.magma). Si vous entrez une spécification de couleur inacceptable, une liste de spécifications de couleur acceptables s'affichera. J'ai donc essayé de la saisir de manière appropriée en y faisant référence.
P.112 np.where Il y a un endroit où il est mal imprimé comme np.whare.
P.116 Trier
La valeur initiale de l'axe de la fonction de tri est -1. Tiré de Documents officiels. Par conséquent, dans le cas d'un tableau à deux dimensions, la direction de la colonne est triée lorsque rien n'est spécifié.
P.121 mat.dot(inv(mat))
Le résultat de l'exécution de mat.dot (inv (mat)) ne correspond pas au livre.
Au début, je pensais que mat.dot (inv (mat)). Astype (np.float32) pouvait être utilisé pour convertir le type de données du tableau NumPy, mais cela ne ressemblait pas à ça, alors je l'ai multiplié par 1000. Arrondi à un entier (rint) puis divisé par 1000. Veuillez me dire la bonne manière.
np.rint(mat.dot(inv(mat)) *1000) /1000
array([[ 1., 0., 0., 0., -0.],
[ 0., 1., 0., -0., -0.],
[ 0., 0., 1., 0., 0.],
[ 0., 0., -0., 1., 0.],
[-0., -0., 0., -0., 1.]])
P.121 Produit de matrices
Dans le commentaire du livre, il y a une description que la notation est autre que np.dot, mais maintenant il semble être @.
Donc, je pense que vous pouvez calculer avec X.T @ X.
P.126 crossing_times = (np.abs(walks[hit30])>=30).argmax(1)
crossing_times = (np.abs (promenades [hit30])> = 30) .argmax (1), par exemple, crossing_times = (np.abs (promenades [hit30])) .argmax (1) , Ou crossing_times = promenades [hit30] .argmax (1) Je me suis demandé si ce n'était pas bon, mais
・ La valeur absolue est de 30 ou plus
・ Je veux le premier index de 30 ou plus, pas l'index avec la distance maximale.
C'est donc le contenu du livre, n'est-ce pas?
Je pense que le point à comprendre est que "dans le cas d 'un tableau de valeurs booléennes, l' index qui est True au tout début est retourné" à la page 124.
Chapitre 5
Résultat P.128 obj.index
Dans le cas des livres, c'est Int64Index ([0, 1, 2, 3]), mais quand je l'essaye à portée de main,
RangeIndex(start=0, stop=4, step=1)
Sera.
P.129 np.exp(obj2) Le résultat de index = d semble-t-il étrange? C'est environ 54,6, non?
P.134 Extraction de lignes et extraction de colonnes
frame2.ix ['three'] est la récupération de la ligne, et lors de la récupération de la ligne, utilisez ix,
Si vous n'utilisez pas ix, comme frame2 ['dette'], ce sera une récupération de colonne,
À propos de ce que vous devez retenir.
P.141 ffill, bfill ffill = remplir le devant bfill = remplir le dos Il est écrit qu'il s'agit de Remplir les valeurs vers l'avant et Remplir les valeurs vers l'arrière en anglais, donc cela s'est peut-être produit, mais cela semble être mal compris.
Il semble que le dictionnaire anglais puisse être interprété comme "look ahead (verb)" avec verbe + forward, il est donc plus facile de se souvenir d'expressions telles que remplir les trous en utilisant le recto et remplir les trous en utilisant le dos si c'est bfill. La recherche en avant est également interprétée comme une recherche en regardant en avant, n'est-ce pas?
P.144, 145 Lors de l'utilisation du découpage pour DataFrame
Si vous utilisez le découpage, comme ʻobj ['b': 'c'] , cela s'applique à la ligne. La même chose s'applique à la référence de valeur d'index data [: 2]`.
Si vous dites simplement data ['two'], cela fonctionne sur les colonnes. Lorsqu'il s'agit de trancher, il agit sur l'index. Je suis un peu confus.
J'ai vérifié d'autres choses en touchant le bloc-notes Jupyter.
-Data [: 3] est égal àdata.ix [: 3].
-Si vous voulez utiliser le découpage dans le sens des colonnes, utilisez data.ix [:,: 3]. Ceci est considéré comme l'une des méthodes d'expression de ʻobj.ix [:, val] `pour extraire les colonnes comme indiqué dans le tableau 5-6.
P.154 obj.order() l'ordre semble désormais obsolète. Un message a été affiché pour utiliser sort_values (). Sera-ce une erreur dans le futur?
P.155 frame.sort_index(by='b')
Cela semble également être actuellement obsolète. Certainement déroutant. De python
frame.sort_values (by = 'b') est recommandé.
p.155 frame.sort_index(by=['a', 'b']) Il vous sera également demandé de trier_values ici. Cela signifie qu'après le tri dans la colonne a, les mêmes valeurs sont triées dans la colonne b. Je veux un peu plus d'explications dans le livre.
P.158 df.sum(axis=1) L'ajout de seulement np.nan est écrit dans le livre pour qu'il devienne np.nan, mais pour autant que je l'ai essayé à partir du 06/07/2016, il devient 0.0. Le comportement est le même lorsque skipna = False. Sera-ce 0 quand il n'y a rien à ajouter? Cependant, quand je vérifie le dernier manuel des pandas, il dit "Exclure NA / valeurs nulles. Si une ligne / colonne entière est NA, le résultat sera NA", est-ce donc un bug?
P.159 Résultat de df.describe ()
Dans le livre, tous les articles ont des numéros, mais si vous l'essayez sous la main,
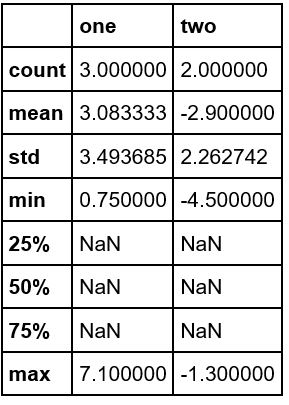 est. Les spécifications ont-elles changé à un moment donné? Même si vous regardez le Manuel, je ne suis pas sûr.
est. Les spécifications ont-elles changé à un moment donné? Même si vous regardez le Manuel, je ne suis pas sûr.
pp.160 import pandas.io.data as web Quand tu fais ça,
The pandas.io.data module is moved to a separate package (pandas-datareader) and will be removed from pandas in a future version.
Il sera affiché. Donc, pour le moment, j'ai fait conda install pandas-datareader.
l'importation est
import pandas.io.data as web
À
import pandas_datareader.data as web
Comme cela a fonctionné. Dans le manuel, j'ai écrit ʻimport pandas_datareader as pdr pour que cela fonctionne même si pdr.get_data_yahoo`, mais cela semble différent.
all_data.iteritems() La description ici semble être basée sur la série Python2. En Python3, la spécification de (dict) .items a été modifiée, donc la description ici est
price = DataFrame({tic : data['Adj Close']
for tic, data in all_data.items()})
volume = DataFrame({tic: data['Volume']
for tic, data in all_data.items()})
Ça semble bien. Peut-être que la réponse est ici http://stackoverflow.com/questions/13998492/iteritems-in-python Cela semble être inclus dans, mais je ne comprends pas très bien l'anglais.
P.162 Définition d'obj
Parce qu'il est difficile d'imiter et de saisir
obj=Series(list('cadaabbcc'))
Je veux que vous écriviez.
P.163 pd.value_counts(obj.values)
Puisqu'il compte la valeur, je me demande si je devrais simplement écrire pd.value_counts (obj). Pas d'erreur.
P.167 .dropna(thresh=3) J'étais un peu confus par l'idée du seuil, mais cela signifie que la valeur est définie sur un nombre autre que NaN. Quand je lis souvent P.166, c'est certainement le cas. Au contraire, j'étais un peu confus parce que je pensais que c'était le nombre de NaN. Au fait, il serait préférable de comprendre le fonctionnement de df.dropna (thresh = 3) en le définissant sur 2.
P.167 df.fillna({1:0.5, 3:-1}) Ce n'est pas dans la rangée 3, mais que faites-vous? 2 erreurs?
P.168 df.fillna(0,inplace=True)
Il dit _ = df.fillna (0, replace = True), mais _ = est-il une erreur d'édition? Vous n'en avez pas besoin.
P.169 Définition des données
C'est un problème de taper "un", "un" ...
data = Series(np.random.randn(10),index=[list('aaabbbccdd'),[1,2,3,1,2,3,1,2,2,3]])
Je veux que vous fassiez un échantillon.
Résultats de P.170 data.index
À portée de main
MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],
labels=[[0, 0, 0, 1, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 1, 2, 0, 1, 1, 2]])
devenu. S'agit-il d'un léger changement de spécification?
P.172 MultiIndex Cela dépend de l'importation, mais si vous importez comme décrit dans ce livre,
pd.MultiIndex.from_arrays([['Ohio','Ohio','Colorado'],['Green','Red','Green']],
names=['state','color'])
Donc, si vous n'écrivez pas pd, c'est inutile. Je me demande si je n'ai pas vérifié le contenu lors de la traduction.
P.176 pdata.swapaxes('items', 'minor') Le résultat juste avant cela est
<class 'pandas.core.panel.Panel'>
Dimensions: 4 (items) x 868 (major_axis) x 6 (minor_axis)
Items axis: AAPL to MSMT
Major_axis axis: 2009-01-02 00:00:00 to 2012-06-01 00:00:00
Minor_axis axis: Open to Adj Close
J'ai donc essayé pdata = pdata.swapaxes ('items', 'minor_axis'), mais il semble que peu importe que _axis soit présent ou non. Dans les deux cas, aucune erreur ne se produit.
Même dans la partie précédente, l'importation est
import pandas_datareader.data as web
est.
Chapitre 6
read_csv(), read_table() Bien que read_csv () et read_table () soient écrits séparément, il est possible de lire un fichier en spécifiant sep = de la même manière pour read_csv et read_table.
P.186 tot.order() tot.sort_values () est recommandé.
P.186 tot.add(piece['key'].value_counts(), fill_value=0)
for piece in chunker:
tot = tot.add(piece['key'].value_counts(), fill_value=0)
Cependant, la lecture du manuel Series add approfondira votre compréhension. http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.add.html
Si fill_values = 0 et que la valeur NA n'est pas traitée, le résultat de l'ajout de Series comprenant NA sera NA, et .add est utilisé dans le but d'empêcher le résultat d'agrégation d'être plein de NA.
P.187 sys.stdout
Préalablement,
import sys
Si vous ne le faites pas, cela ne passera pas. N'est-ce pas écrit en supposant que vous êtes familier avec le langage Python?
P.188 data.to_csv(sys.stdout, index=False, cols=['a','b','c'])
Manuel
http://pandas.pydata.org/pandas-docs/version/0.18.1/generated/pandas.DataFrame.to_csv.html
Un péché
data.to_csv(sys.stdout, index=False, columns=['a','b','c'])
Si vous ne le définissez pas sur, cela ne fonctionnera pas.
Une chose qui m'intéresse, c'est que lorsque vous dites «cols», vous n'obtenez pas d'erreur, vous prenez simplement et écrivez des colonnes autres que celle que vous voulez. Dois-je recevoir une erreur? punaise?
Contenu de P.188 tseries.csv
Dans l'environnement à portée de main, contrairement aux résultats du livre, il n'y a pas d'informations temporelles,
.csv
2000-01-01,0
2000-01-02,1
2000-01-03,2
2000-01-04,3
2000-01-05,4
2000-01-06,5
2000-01-07,6
est devenu.
P.189 print line En Python3, c'est print (line).
P.192 to_json, from_json Il y a une déclaration indiquant qu'il y a des tentatives d'implémentation de to_json et from_json. Selon le manuel, to_json semble être implémenté à partir du 8 juin 2016. Puisque from_json n'est pas décrit dans le manuel, il se peut qu'il ne soit pas encore implémenté.
P.192 urlib2
Il semble que les packages sont intégrés dans Python3 et que seul urllib est disponible.
De plus, vous ne pouvez pas simplement le modifier en from urllib import urlopen, vous devez le faire avec from urllib.request import urlopen. Ceci est également affecté par le passage de Python 2 à 3.
Référence: http://diveintopython3-ja.rdy.jp/porting-code-to-python-3-with-2to3.html
- L'effet de la différence entre Python 2 et 3 ici est qu'après avoir utilisé un programme qui convertit automatiquement la source, la différence doit être évaluée et publiée comme un tableau correct / incorrect.
P.198 Lecture de données binaires (données Pickle?)
pd.load()
Cependant, dans les derniers pandas,
pd.read_pickle('ch06/frame_pickle')
Il est devenu.
Référence: http://pandas.pydata.org/pandas-docs/stable/io.html#io-pickle
Chapitre 7
P.206 Pd.merge(df1, df2) Quand je l'essaye à portée de main, l'ordre des résultats est légèrement différent de ce qui est décrit dans le livre. Dans le livre, l'ordre est comme s'il était trié par clé, mais à portée de main, le résultat est qu'il est trié par df1 (data1).
P.208 Produit cartésien
C'est comme un ensemble de produits direct. Je l'ai entendu pour la première fois.
Référence: https://ja.wikipedia.org/wiki/%E7%9B%B4%E7%A9%8D%E9%9B%86%E5%90%88
Recommended Posts