[PYTHON] Réseau neuronal récursif: une introduction à RNN
Les réseaux de neurones récursifs (RNN) ont connu un grand succès dans le domaine du traitement du langage naturel et sont actuellement l'un des algorithmes les plus populaires. Cependant, je pense qu'il n'y a qu'un nombre limité de livres qui expliquent comment RNN fonctionne réellement et comment le construire, en avance sur sa popularité. Cet article s'est concentré sur cette partie et a été écrit avec mon ami Denny (auteur de WildML Blog).
Je voudrais maintenant expliquer le modèle de langage basé sur RNN. Le modèle de langage a deux utilisations. La première consiste à évaluer la probabilité qu'une phrase apparaisse réellement. Ce score est un critère de correction grammaticale et sémantique. De tels modèles sont utilisés, par exemple, dans la traduction automatique. Deuxièmement, le modèle de langage peut générer du nouveau texte (d'ailleurs, je pense personnellement que c'est une utilisation plus cool). De plus, bien qu'il soit en anglais, le [blog] d'Andrej Karpathy (http://karpathy.github.io/2015/05/21/rnn-effectiveness/) explique et développe un modèle de langage RNN au niveau des mots, donc cela prend du temps. Si vous en avez un, veuillez le lire.
Le lecteur suppose que les éléments rudimentaires concernant les réseaux de neurones sont supprimés. Sinon, [Construisons un réseau neuronal avec Python sans utiliser de bibliothèque](http://blog.moji.ai/2015/12/python% e3% 81% a7% e3% 83% a9 % e3% 82% a4% e3% 83% 96% e3% 83% a9% e3% 83% aa% e3% 83% bc% e3% 82% 92% e4% bd% bf% e3% 82% 8f% e3 % 81% 9a% e3% 81% ab% e3% 80% 81% e3% 83% 8b% e3% 83% a5% e3% 83% bc% e3% 83% a9% e3% 83% ab% e3% 83 Veuillez lire% 8d% e3% 83% 83% e3% 83% 88 /). Cet article explique et construit un modèle de réseau non récursif.
Qu'est-ce que RNN (Recurrent Neural Network)?
L'avantage de RNN est que vous pouvez utiliser des informations continues telles que des phrases. L'idée traditionnelle des réseaux neuronaux n'est pas le cas, en supposant que les données d'entrée (et les données de sortie) sont indépendantes les unes des autres. Mais cette hypothèse est souvent incorrecte. Par exemple, si vous voulez prédire le mot suivant, vous devez savoir quel était le mot précédent, n'est-ce pas? R dans RNN signifie Reccurent, ce qui vous permet de faire le même travail pour chaque élément continu, quel que soit le calcul précédent. En d'autres termes, RNN a la mémoire pour se souvenir des informations précédemment calculées. Théoriquement, RNN peut utiliser des informations textuelles très longues. Cependant, lorsque je le mets en œuvre, je ne peux me souvenir que des informations d'il y a quelques étapes (je vais approfondir cette question ci-dessous). Jetons maintenant un œil à un RNN général dans le tableau ci-dessous.
 A recurrent neural network and the unfolding in time of the computation involved in its forward computation. Source: Nature
A recurrent neural network and the unfolding in time of the computation involved in its forward computation. Source: Nature
Le graphique ci-dessus se développe à l'intérieur du RNN. Déployer signifie simplement écrire un réseau ordonné. Par exemple, si vous avez une phrase composée de 5 mots, le réseau étendu sera un réseau neuronal à 5 couches avec 1 couche et 1 mot. La formule de calcul du RNN est la suivante.
$ x_t $ est l'entrée pour l'étape $ t $. Par exemple, $ x_1 $ est un vecteur associé aux mots suivants: $ s_t $ est un élément caché lors de l'étape $ t $. C'est la mémoire du réseau. $ s_t $ est calculé en fonction de l'élément caché précédent. Et l'entrée dans cette étape est $ s_t = f (U x_x + W s_ {t-1}) $. Les fonctions $ f $ incluent tanh et ReLU Le type non linéaire de est courant. Le $ s_ {-1} $ nécessaire pour calculer le premier élément caché commence généralement à 0. $ o_t $ est la sortie à l'étape $ t $. Par exemple, si vous voulez prédire les mots suivants, $ o_t $ sera un vecteur de probabilités de prédiction ($ o_t = softmax (V s_t) $).
Ce que RNN peut faire
RNN a déjà connu de nombreuses réussites dans le domaine du traitement du langage naturel. Maintenant que nous avons un peu de compréhension de RNN, nous allons introduire l'un des RNN les plus utilisés, LSTM. LSTM est meilleur pour apprendre les relations à distance que RNN. Cependant, ne vous inquiétez pas, LSTM a fondamentalement la même structure d'algorithme que le RNN à construire cette fois. La seule différence est la façon dont les éléments cachés sont calculés. Nous prévoyons de couvrir LSTM à l'avenir, donc si vous êtes intéressé, veuillez vous inscrire à la newsletter par e-mail.
Modèle de langage et génération de phrases
Le modèle linguistique peut utiliser le mot précédent pour prédire la probabilité que le mot suivant apparaisse dans une série de mots. Il est utilisé pour la traduction automatique car il peut mesurer la fréquence d'apparition des phrases. Une autre bonne chose à propos de la capacité de prédire le mot suivant est que vous pouvez obtenir un modèle génératif qui peut générer de nouvelles phrases en échantillonnant à partir de la probabilité de sortie. Par conséquent, il est possible de générer diverses choses en fonction des données d'entraînement. Dans le modèle linguistique, les données d'entrée sont une séquence continue de mots. Et la sortie sera une séquence de mots prédits. Lors de l'entraînement du réseau, nous voulons que la sortie de l'étape $ t $ soit les mots suivants, nous définissons donc $ o_t = x_ {t + 1} $.
Bien qu'il soit en anglais, ce qui suit est une référence pour les articles sur les modèles linguistiques et la génération de texte.
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
Traduction automatique
La traduction automatique est similaire au modèle de langue en ce qu'elle prend des phrases dans la langue source (par exemple le japonais) comme entrée. Et le résultat est, par exemple, des phrases en anglais. La différence avec le modèle de langage réside dans le fait que le traitement des données de sortie commence après la lecture des données d'entrée complètes. Par conséquent, le premier mot de la phrase traduite nécessite des informations de phrase d'entrée complètes.
 RNN for Machine Translation. Image Source: http://cs224d.stanford.edu/lectures/CS224d-Lecture8.pdf
RNN for Machine Translation. Image Source: http://cs224d.stanford.edu/lectures/CS224d-Lecture8.pdf
Bien qu'il soit en anglais, ce qui suit est une référence pour les articles sur la traduction automatique.
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
Reconnaissance de la parole
En utilisant un signal acoustique continu provenant d'une source sonore comme entrée, un segment vocal continu est prédit de manière probabiliste.
Bien qu'il soit en anglais, ce qui suit est une référence pour les articles sur la reconnaissance vocale.
Génération de résumé d'image
Vous pouvez utiliser les réseaux de neurones convolutifs et RNN pour générer une vue d'ensemble d'une image sans étiquette. Comme vous pouvez le voir sur l'image ci-dessous, il est possible de générer un résumé avec une probabilité assez élevée.
Deep Visual-Semantic Alignments for Generating Image Descriptions. Source: http://cs.stanford.edu/people/karpathy/deepimagesent/
Train RNN
L'apprentissage de RNN est similaire à l'apprentissage d'un réseau de neurones traditionnel, mais pour RNN, nous utilisons un algorithme de rétropropagation légèrement différent. Comme les paramètres RNN sont utilisés à chaque étape du réseau, le gradient pas à pas utilise le calcul de l'étape précédente ainsi que le calcul de l'étape en cours. Par exemple, pour calculer le dégradé de $ t = 4 $, vous devez revenir en arrière de 3 étapes et ajouter les dégradés. C'est ce qu'on appelle la propagation en arrière dans le temps (BPTT). Si vous ne comprenez pas ce que cela signifie, ne vous inquiétez pas. J'écrirai les détails dans un prochain post. Pour l'instant, gardez à l'esprit que les RNN formés à l'aide du BPTT sont plus difficiles à former à mesure qu'ils sont éloignés. Un algorithme de type LSTM (un type de RNN) a été développé pour résoudre ce problème.
Application de RNN
Des efforts de recherche récents ont conduit à l'émergence de modèles RNN plus sophistiqués qui peuvent éliminer les lacunes des RNN traditionnels. J'expliquerai cela dans un prochain article, mais dans cet article, je vais vous donner une brève introduction.
Bidirectional RNN Dans RNN bidirectionnel, la sortie de $ t $ n'est pas calculée uniquement sur la base de l'élément immédiatement précédent, mais également sur l'élément suivant. Par exemple, lors de la prédiction de mots qui n'apparaissent pas dans la partie précédente, la probabilité doit être calculée en incluant ces derniers mots. Pensez donc à un RNN bidirectionnel comme un chevauchement de deux RNN. La sortie est calculée à partir de deux éléments cachés.

Deep (Bidirectional) RNN Le RNN profond est similaire au RNN bidirectionnel, sauf qu'il a plusieurs couches par étape. Si vous essayez de le mettre en œuvre, vous obtiendrez une meilleure capacité d'apprentissage (même si vous avez encore besoin de beaucoup de données d'apprentissage).
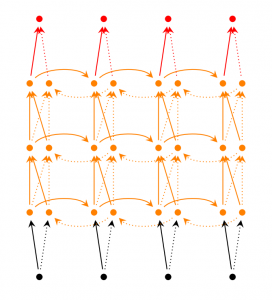
Réseau LSTM
Comme je l'ai un peu mentionné, le réseau LSTM est l'un des RNN les plus populaires de nos jours. LSTM a fondamentalement la même structure que RNN, mais conduit une fonction différente pour calculer les éléments cachés. La mémoire LSTM est appelée Cell et peut être considérée comme une boîte noire avec l'élément précédent $ h_ {t-1} $ et l'élément courant $ x_t $ comme entrées. Dans la boîte noire, sélectionnez la cellule à stocker en mémoire. Combinez ensuite l'élément précédent, l'élément actuel et l'entrée. En conséquence, il est possible d'extraire avec succès les relations entre des mots éloignés. LSTM est un peu difficile à comprendre, mais si vous êtes intéressé, il est en anglais, mais l'explication de here est facile à comprendre, alors veuillez vous y référer. regarde s'il te plait.
Recommended Posts