[PYTHON] Conseils et précautions lors de l'analyse des données
introduction
Pour noter les points à noter lors de l'analyse des données par vous-même
- ** Conseils pour l'analyse **
- ** Notes sur l'analyse **
Informations précédentes
Cette fois, je vais vous expliquer en utilisant les données utilisées dans le concours Kaggle.
Kaggle House Prices DataSet
Kaggle House Prices Kernel
Faites une note en utilisant.
Veuillez noter que nous ne nous soucions pas de la précision du modèle, etc. car nous la conservons pour Memo`
Contenu des données
Il y a 81 caractéristiques en tout, dont SalePrices est utilisée comme variable objective (cible) pour l'analyse.
Les variables explicatives sont autres que SalePrices.
Tips Tout d'abord, il vaut mieux faire cela pour les données
Prétraitement
Tout d'abord, lisez les données (DataFrame-> df) et effectuez ʻEDA (analyse exploratoire des données) `.
-. head (): Afficher au début des données, extraire 5 lignes si (5), la valeur par défaut est 5 --.info (): Récapitulatif des données (nombre de lignes, nombre de colonnes, nom de colonne de chaque colonne, type de données stockées dans chaque colonne, etc ....) -. describe (): Statistiques de base des données (min, max, 25% etc .....) -. shape [0], .shape [1]: vérifier le nombre de lignes et de colonnes de données
- .colonnes: récupère les noms de colonne des données -. isnull (). Sum (): Vérifiez le nombre de zones manquantes dans chaque colonne -. dtypes: Vérifiez le type de type de chaque colonne
# import
import pandas as pd
import matplotlib.pyplot as plt ## for drawing graph
## load Data
df = pd.read~~~~(csv , json etc...)
#Affichage supérieur des données
df.head()
#Affichage récapitulatif des données
df.info()
#Nombre de dimensions des données (combien de lignes et de colonnes)
print('There are {} rows and {} columns in df'.format(df.shape[0], df.shape[1]))
#Obtenir une colonne de données
df.columns
#Comptez le nombre de valeurs manquantes dans chaque colonne de données
df.isnull().sum()
#Confirmation du type de type de chaque donnée de colonne
df.dtypes
Vous pouvez obtenir les noms de colonnes avec df.columns, mais si vous conservez une liste de noms de colonnes en fonction du type de type, vous pourrez peut-être l'utiliser si vous y réfléchissez plus tard. Décrivez le code. Il est également possible de changer ʻinclude en type type (float64 etc ...) `.
obj_columns = df.select_dtypes(include=['object']).columns
numb_columns = df.select_dtypes(include=['number']).columns
exemple de tracé
Histogramme de chaque colonne (quantité de fonctionnalité)
La quantité de caractéristiques de chaque colonne est transformée en un histogramme. Cependant, cela ne peut gérer que des «données numériques». Puisqu'il ne peut pas être appliqué aux "données de chaîne de caractères", il sera décrit plus tard.
- .hist(bins=**, figsize=(,))
bins est le réglage de la finesse de la valeur de classe pour analyser la fréquence, et figsize est le réglage de la taille de la figure. Vous pouvez faire de nombreux autres arguments, veuillez donc vous référer à ce qui suit. official pyplot.hist document
df.hist(bins=50, figsize=(20,15))
plt.show()
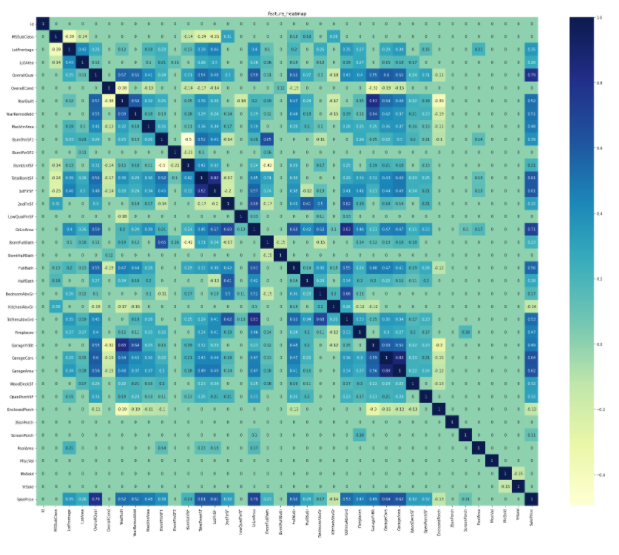
Carte thermique de matrice de corrélation
Dans l'apprentissage automatique, il est important de trouver la matrice de corrélation de chaque quantité de caractéristiques. Visualisez-le avec une carte thermique pour visualiser la matrice de corrélation.
- .heatmap(corr, annot=bool(True or False), cmap='***')
corr est la matrice de corrélation, annot définit la valeur dans la cellule, cmap spécifie la couleur de la figure Vous pouvez faire de nombreux autres arguments, veuillez donc vous référer à ce qui suit. official seaborn.heatmap document
import seaborn as sns ## for drawing graph
corr = train_df.corr()
corr[np.abs(corr) < 0.1] = 0 ## corr<0.1 => corr=0
sns.heatmap(corr, annot=True, cmap='YlGnBu')
plt.show()
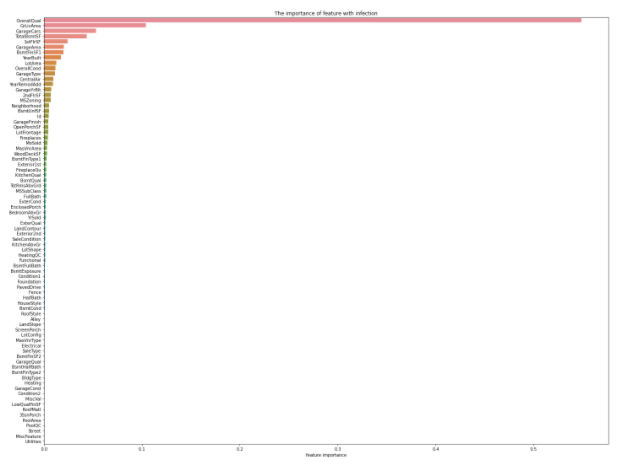
Estimer l'importance des fonctionnalités
Random Forest est utilisé pour calculer les caractéristiques importantes pour les SalePrices cibles. Afin de réaliser RandomForest, il est d'abord nécessaire de le diviser en «variable explicative et variable objective». ** Cette fois, toutes les variables autres que la cible (SalePsices) sont utilisées comme variables explicatives. ** **
-. drop ("***", axis = (0 ou 1)): Spécifiez une colonne qui n'est pas utilisée pour ***, ligne si axe = 0, colonne si 1. --RandomForestRegressor (n_estimators = **): n_estimators est le nombre d'apprentissage
from sklearn.ensemble import RandomForestRegressor
X_train = df.drop("SalePrices", axis=1)
y_train = df[["SalePrices"]]
rf = RandomForestRegressor(n_estimators=80, max_features='auto')
rf.fit(X_train, y_train)
ranking = np.argsort(-rf.feature_importances_) ##Dessiner par ordre décroissant d'importance
sns.barplot(x=rf.feature_importances_[ranking], y=X_train.columns.values[ranking], orient='h')
plt.show()
Distribution de chaque fonctionnalité (pour vérifier les valeurs aberrantes, etc.)
On dit que lorsque les quantités d'entités incluent des valeurs aberrantes lors de l'analyse de régression, cela est susceptible d'affecter la précision du modèle. Par conséquent, on considère que le traitement des valeurs aberrantes est indispensable pour améliorer la précision du modèle. Par conséquent, il est facile de visualiser et de confirmer le nombre de valeurs d'écart incluses dans chaque quantité d'entités.
Ici, des graphiques des 30 caractéristiques les plus importantes sont exécutés.
-. iloc [:,:]: extraire la valeur en spécifiant une ligne ou une colonne --sns.regplot: tracé en superposant les données 2D et les résultats du modèle de régression linéaire
X_train = X_train.iloc[:,ranking[:30]]
fig = plt.figure(figsize=(12,7))
for i in np.arange(30):
ax = fig.add_subplot(5,6,i+1)
sns.regplot(x=X_train.iloc[:,i], y=y_train)
plt.tight_layout()
plt.show()
point important
Vérifier si la cible (variable objectif) suit une distribution normale
Dans ces données, la cible est SalePrices. Dans l'apprentissage automatique, «si la variable objective suit une distribution normale» est important car cela affecte le modèle. Regardons donc la distribution des SalePrices. Dans cette figure, l'axe vertical montre le ratio et l'axe horizontal montre les SalePrices.
sns.distplot(y_train, color="red", label="real_value")
plt.legend()
plt.show()
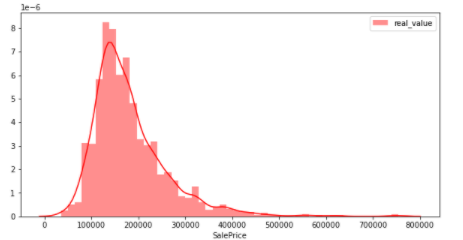
D'après la figure ci-dessus, on peut voir que la distribution est légèrement biaisée vers la gauche. Ce n'est pas une distribution normale (données dans lesquelles la plupart des valeurs numériques sont concentrées au centre lorsqu'elles sont représentées graphiquement et «distribuées» en forme de cloche symétrique). Par conséquent, les ** transformées logarithmiques et différentielles ** couramment utilisées sont indiquées ci-dessous afin que la variable objectif suive une distribution normale.
y_train2 = np.log(y_train)
y_train2 = y_train2.replace([np.inf, -np.inf], np.nan)
y_train2 = y_train2.fillna(0)
sns.distplot(y_train2, color="blue", label="log_value")
plt.legend()
plt.show()
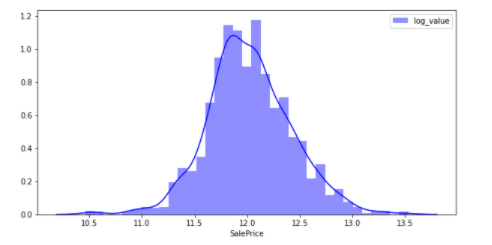
En effectuant une conversion logarithmique, le chiffre est proche d'une distribution normale.
y_train3 = y_train.diff(periods = 1)
y_train3 = y_train3.fillna(0)
sns.distplot(y_train3, color="green", label="diff_value")
plt.legend()
plt.show()
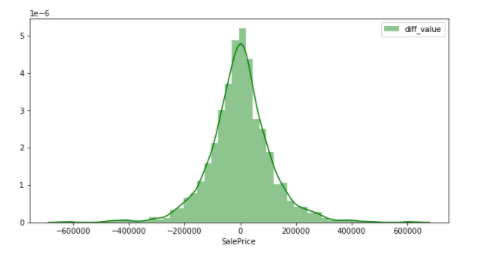
C'est un chiffre qui peut être considéré comme une distribution normale en effectuant une conversion de différence. En d'autres termes, on peut en déduire que la variable objective qui n'affecte pas facilement la précision du modèle est SalePrices qui a subi une conversion différentielle. De cette façon, ** Lorsque vous traitez avec des données, il est préférable de vérifier si les valeurs sont biaisées. ** ** Je voudrais écrire un prochain article comparant la précision du modèle quand il suit réellement la distribution normale et quand ce n'est pas le cas.
Résumé
Ce qui précède est un résumé de ce qu'il faut faire en premier lors de l'analyse des données. À l'avenir, j'aimerais écrire des articles sur la gestion des données de chaînes de caractères et la gestion des données de séries chronologiques, que j'ai mentionnées plus tôt, lors de l'analyse des données.
Recommended Posts