[PYTHON] Comment utiliser xgboost: classification multi-classes avec des données d'iris
** xgboost ** est une bibliothèque qui gère ** GBDT **, qui est l'un des modèles d'arbre de décision. Nous avons résumé les étapes d'installation et d'utilisation. Il peut être utilisé dans différents langages, mais il décrit comment l'utiliser en Python.
Qu'est-ce que GBDT
--Un type de modèle d'arbre de décision
- Arbre d'amplification de pente
- Gradient Boosting Decision Tree
La forêt aléatoire est célèbre pour le même modèle d'arbre de décision, mais l'article suivant résume brièvement les différences. [Apprentissage automatique] J'ai essayé de résumer les différences entre les modèles d'arbre de décision - Qiita
Caractéristiques de GBDT
- Facile à obtenir une bonne précision
- Peut gérer les valeurs manquantes
- Les données numériques peuvent être traitées
Il est populaire dans la compétition d'apprentissage automatique Kaggle car il est facile à utiliser et précis.
[1] Comment utiliser
J'ai utilisé des données d'iris (données de variété Ayame), qui sont l'un des ensembles de données scikit-learn. Le système d'exploitation est Amazon Linux 2.
[1-1] Installation
Amazon Linux 2 que j'utilise est: La procédure d'installation pour chaque environnement est officiellement répertoriée. Installation Guide — xgboost 1.1.0-SNAPSHOT documentation
pip3 install xgboost
[1-2] Importer
import xgboost as xgb
[1-3] Acquisition des données d'iris
Il n'y a pas d'étapes spéciales. Obtenez des données d'iris et créez des pandas DataFrame et Series.
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_data = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_target = pd.Series(iris.target)
[1-4] Acquisition de données d'entraînement et de données de test
Encore une fois, il n'y a pas d'étapes spéciales et le scikit-learn train_test_split divise les données pour l'entraînement et les tests.
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(iris_data, iris_target, test_size=0.2, shuffle=True)
[1-5] Convertir en type pour xgboost
xgboost utilise «DMatrix».
dtrain = xgb.DMatrix(train_x, label=train_y)
DMatrix peut être créé à partir de ndarray ou de pandas'DataFrame de numpy, vous n'aurez donc aucun problème à gérer les données.
Les types de données pouvant être traitées sont officiellement détaillés. Python Package Introduction — xgboost 1.1.0-SNAPSHOT documentation
[1-6] Réglages des paramètres
Définissez divers paramètres.
param = {'max_depth': 2, 'eta': 1, 'objective': 'multi:softmax', 'num_class': 3}
La signification de chaque paramètre est la suivante.
| Le nom du paramètre | sens |
|---|---|
| max_depth | Profondeur maximale de l'arbre |
| eta | Taux d'apprentissage |
| objective | Objectif d'apprentissage |
| num_class | Nombre de cours |
Précisez le but d'apprentissage (retour, classification, etc.) dans «objectif». Puisqu'il s'agit d'une classification multi-classes, «multi: softmax» est spécifié.
Les détails sont officiellement détaillés. XGBoost Parameters — xgboost 1.1.0-SNAPSHOT documentation
[1-7] Apprentissage
num_round est le nombre d'apprentissage.
num_round = 10
bst = xgb.train(param, dtrain, num_round)
[1-8] Prévisions
dtest = xgb.DMatrix(test_x)
pred = bst.predict(dtest)
[1-9] Confirmation de l'exactitude
Vérifiez le taux de réponse correct avec ʻaccuracy_score` de scikit-learn.
from sklearn.metrics import accuracy_score
score = accuracy_score(test_y, pred)
print('score:{0:.4f}'.format(score))
# 0.9667
[1-10] Visualisation de l'importance
Visualisez les fonctionnalités qui ont contribué aux résultats de la prédiction.
xgb.plot_importance(bst)
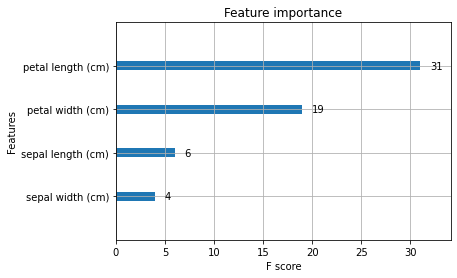
[2] Validation et arrêt précoce pendant l'apprentissage
La validation pendant l'apprentissage à l'aide des données de vérification et l'arrêt prématuré (interruption de l'apprentissage) peut être facilement effectuée.
[2-1] Division des données
Une partie des données d'entraînement sera utilisée comme données de vérification.
train_x, valid_x, train_y, valid_y = train_test_split(train_x, train_y, test_size=0.2, shuffle=True)
[2-2] Création de DMatrix
dtrain = xgb.DMatrix(train_x, label=train_y)
dvalid = xgb.DMatrix(valid_x, label=valid_y)
[2-3] Ajout de paramètres
Ajoutez "eval_metric" au paramètre de validation. Pour "eval_metric", spécifiez la métrique.
param = {'max_depth': 2, 'eta': 0.5, 'objective': 'multi:softmax', 'num_class': 3, 'eval_metric': 'mlogloss'}
[2-4] Apprentissage
Spécifiez les données à surveiller par validation dans evallist. Spécifiez «eval» comme nom des données de vérification et «entraînement» comme nom des données d'entraînement.
ʻEarly_stopping_rounds est ajouté comme argument de xgb.train. ʻEarly_stopping_rounds = 5 signifie que l'apprentissage sera interrompu si les métriques ne s'améliorent pas 5 fois de suite.
evallist = [(dvalid, 'eval'), (dtrain, 'train')]
num_round = 10000
bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=5)
# [0] eval-mlogloss:0.61103 train-mlogloss:0.60698
# Multiple eval metrics have been passed: 'train-mlogloss' will be used for early stopping.
#
# Will train until train-mlogloss hasn't improved in 5 rounds.
# [1] eval-mlogloss:0.36291 train-mlogloss:0.35779
# [2] eval-mlogloss:0.22432 train-mlogloss:0.23488
#
#~ ~ ~ Omis en chemin ~ ~ ~
#
# Stopping. Best iteration:
# [1153] eval-mlogloss:0.00827 train-mlogloss:0.01863
[2-5] Confirmation des résultats de la vérification
print('Best Score:{0:.4f}, Iteratin:{1:d}, Ntree_Limit:{2:d}'.format(
bst.best_score, bst.best_iteration, bst.best_ntree_limit))
# Best Score:0.0186, Iteratin:1153, Ntree_Limit:1154
[2-6] Prévisions
Faites des prédictions en utilisant le modèle avec les meilleurs résultats de vérification.
dtest = xgb.DMatrix(test_x)
pred = ypred = bst.predict(dtest, ntree_limit=bst.best_ntree_limit)
À la fin
Étant donné que DataFrame et Series de pandas peuvent être utilisés, le seuil semble être bas pour ceux qui ont fait de l'apprentissage automatique jusqu'à présent.
J'ai essayé la classification multi-classes cette fois, mais elle peut également être utilisée pour la classification binaire et la régression, de sorte qu'elle peut être utilisée dans diverses situations.
Recommended Posts