[PYTHON] Comment gérer les données déséquilibrées
Ceci est l'article sur le 10ème jour du calendrier de l'Avent du Docomo Advanced Technology Research Institute.
Je m'appelle Kaneda de Docomo. Dans cet article, nous expliquerons les bases des méthodes d'évaluation et des méthodes de création de modèles pour les données déséquilibrées qui sont souvent rencontrées dans l'analyse de données réelles. De plus, dans la seconde moitié de l'article, nous menons des expériences pour approfondir notre compréhension des données déséquilibrées. Je pense qu'il y a de nombreux points qui ne peuvent être atteints, mais merci.
1. Qu'est-ce que les données déséquilibrées?
Données telles que ** exemple positif 1%, exemple négatif 99% **. Non limité à la classification binaire, il peut être traité en classification multi-classes. Cet article se concentre sur les classifications binomiales les plus courantes (où il existe des cas minoritaires positifs et négatifs).
2. Méthode d'évaluation
La clé pour construire un modèle à partir de données déséquilibrées est de décider comment évaluer le modèle. Si la méthode d'évaluation n'est pas décidée, vous ne saurez pas quel objectif vous devez viser. Dans le cas de données déséquilibrées, il convient de noter qu'il existe des indicateurs d'évaluation qui ne peuvent pas être interprétés de la même manière que d'habitude.
Comment évaluer
En conclusion, je pense qu'il vaut mieux ** tracer une courbe Precision-Recall (ci-après appelée courbe PR) **. En plus de cela, il est important de considérer l'équilibre entre Précision et Rappel requis pour chaque paramètre de problème, définir un seuil approprié et effectuer la classification binaire finale. Lors du réglage des paramètres du modèle, il est recommandé d'utiliser la zone sous la courbe PR (ci-après dénommée PR-AUC) comme indice d'évaluation.
Dans ce qui suit, nous expliquerons pourquoi les courbes PR et PR-AUC devraient être utilisées pour prédire les données déséquilibrées.
Réponses correctes et incorrectes en classification binaire
| Positif | Négatif | |
|---|---|---|
| Positif | TP: True Positive | FN:False Negative |
| Négatif (valeur vraie) | FP: False Positive | TN: True Negative |
Cette table est appelée matrice mixte et est indispensable lorsque l'on considère l'indice d'évaluation de la classification binaire. Puisqu'il est correct de prédire qu'un exemple positif est un exemple positif et qu'un exemple négatif est un exemple négatif, un modèle avec de nombreux TP et TN et peu de FN et de PF est un bon modèle.
À ce stade, envisagez de donner la priorité à la réduction des fausses prédictions de FN et de FP. En général, lorsque vous prévoyez des données déséquilibrées, accordez-vous souvent la priorité à la réduction du FN? La raison en est que si le cas positif de la minorité est mal évalué, même si le cas négatif de la majorité est légèrement jugé à tort comme le cas positif, on considère que le cas positif est sûrement considéré comme le cas correct. C'est parce que (bien sûr, cela dépend de la configuration du problème). ** Dans le contexte du problème auquel vous êtes confronté actuellement, il est important de savoir si FN ou FP doit être priorisé dans la classification binar finale. ** **
Indice d'évaluation typique
Sur la base de ce qui précède, examinons les index d'évaluation typiques dans la classification binaire.
Accuracy = (TP+TN)/(TP+FP+TN+FN)
La précision est l'indicateur le plus évident, mais il est difficile à utiliser pour prédire des données déséquilibrées. En effet, la précision peut facilement être proche de la valeur maximale de 1 simplement en construisant un modèle qui prédit tous les exemples négatifs de la majorité. De toute évidence, un tel modèle n'est pas celui que vous recherchez, il serait donc inapproprié d'utiliser la précision comme indicateur.
Precision = TP/(TP+FP)\\
Recall = TP/(TP+FN)
Viennent ensuite la précision et le rappel. Celles-ci sont généralement considérées comme étant dans une relation de compromis, et lorsque la précision est élevée / faible, le rappel est faible / élevé. Maintenant, réfléchissons à nouveau aux FN et FP pour déterminer lequel devrait être priorisé. Plus tôt, j'ai expliqué que vous vouliez souvent réduire FN lors de la prédiction de données déséquilibrées, mais dans ce cas, vous devriez viser à augmenter le rappel qui inclut FN dans le dénominateur. Cependant, si vous voulez simplement que Recall soit la valeur maximale de 1, vous devrez créer un modèle qui prédit tous les positifs minoritaires, par opposition à l'exemple de précision. ** Par conséquent, il n'est pas nécessaire d'utiliser uniquement Précision ou Rappel comme indice d'évaluation, et il est nécessaire d'évaluer de manière exhaustive le modèle à partir des deux indices d'évaluation. ** **
Cependant, il arrive souvent que vous souhaitiez combiner les deux mesures Précision et Rappel en une seule. L'indice d'évaluation qui est souvent utilisé à ce moment-là est la valeur F1 introduite ci-dessous.
F-measure = 2Recall*Precision/(Recall+Precision)
La valeur F1 est calculée à partir de la moyenne harmonisée de précision et de rappel. Intuitivement, un modèle avec une valeur F1 élevée aura une haute précision et rappel. Veuillez noter que la valeur F1 évalue la précision et le rappel de la même manière, et n'est pas un index qui donne la priorité à la précision ou au rappel [^ 1].
À propos du seuil
Avant de procéder à l'introduction du prochain indice d'évaluation, j'expliquerai le concept de seuils en classification binaire. Pour prédire si un modèle est positif ou négatif, un score tel que "80% de probabilité d'être positif" est d'abord calculé, et si le score est supérieur au seuil (par exemple, 50%), il est positif et s'il est inférieur, il est négatif. Un traitement réputé est effectué. Etant donné que le résultat de la prédiction change considérablement en modifiant ce seuil, il est nécessaire de décider quel seuil doit être utilisé lors de l'exécution effective d'une classification binaire.
Les quatre types d'indices d'évaluation introduits précédemment sont tous des indices calculés après avoir déterminé le seuil. Par conséquent, s'il est décidé à l'avance que «50% est le seuil», je pense que le modèle peut être construit de telle sorte que la valeur F1 calculée lorsque le seuil est de 50% soit la plus élevée. Cependant, il existe de nombreux cas où ** il est seulement nécessaire de classer correctement avec l'un des seuils (le seuil n'est pas fixé à une valeur spécifique) **, et dans ce cas, un indice d'évaluation ne nécessitant pas de seuil est utilisé.
Indice d'évaluation qui ne nécessite pas de seuil
L'aire sous la courbe ROC (ROC-AUC) et l'aire sous la courbe PR (PR-AUC) sont des indices d'évaluation qui ne nécessitent pas de seuil.
--ROC-AUC: zone sous la courbe dessinée lors du traçage de la relation entre le rappel et le taux de faux positifs FPR tout en modifiant le seuil (figure de gauche) --PR-AUC: Zone sous la courbe dessinée lors du traçage de la relation entre Précision et Rappel tout en modifiant le seuil (figure de droite)
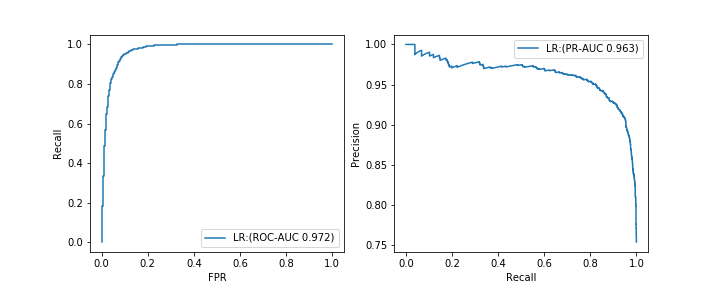
La formule de calcul du taux de faux positifs FPR est la suivante.
FPR = FP/(FP+TN)
Je pense que l'AUC fait souvent référence à ROC-AUC. Je vais omettre l'explication détaillée, mais tous les indicateurs ont des propriétés de base similaires, et plus la valeur maximale de 1 est proche, meilleur est le modèle. De plus, étant donné que les deux sont calculés sur la base de deux indices d'évaluation comme la valeur F1, nous ne considérons généralement pas comme bon un modèle dénué de sens qui prédit tous comme des exemples positifs ou négatifs. Cependant, dans le cas de ** prédiction de données déséquilibrées, ROC-AUC peut ne pas être une mesure appropriée. ** **
Il est difficile d'expliquer la raison avec précision, mais comme une compréhension facile à comprendre de moi-même, ** ROC-AUC évalue "Est-il possible de prédire correctement les exemples positifs comme exemples positifs et les exemples négatifs comme exemples négatifs?" D'autre part, PR-AUC considère uniquement "si le bon exemple peut être correctement prédit comme le bon exemple" comme point d'évaluation. ** Dans le cas d'une prédiction de données déséquilibrée, il est facile de prédire la majorité des cas négatifs comme des cas négatifs, et ROC-AUC, qui l'utilise comme point d'évaluation, ** la plupart des cas positifs sont des cas positifs. Même si vous ne pouvez pas le prédire, ** la simple création d'un modèle qui prédit la majorité des cas négatifs comme négatifs entraînera probablement des valeurs finales plus élevées. D'un autre côté, PR-AUC considère uniquement si un exemple positif peut être prédit comme un exemple positif, donc peu importe à quel point un exemple négatif est prédit comme un exemple négatif, il ne sera pas évalué du tout.
Cependant, cela ne signifie pas que PR-AUC est supérieur à ROC-AUC. ** Pour prédire des données déséquilibrées, il est important de bien prédire les exemples minoritaires (je pense que c'est souvent le cas). Par conséquent, **, PR-AUC est considéré comme un indice d'évaluation approprié.
En fait, quand il y avait un modèle A avec un PR-AUC de 0,5 et un modèle B avec un PR-AUC de 0,4, "La performance globale vue avec le PR-AUC est meilleure avec le modèle A, mais un rappel spécifique À ce moment-là, la précision du modèle B est plus élevée. »Donc ** Ne vous en tenez pas autant à une valeur d'AUC, considérez l'équilibre requis entre précision et rappel, tracez une courbe PR et final Je pense qu'il est bon de vérifier la qualité d'un modèle typique. ** **
3. Comment construire un modèle
Dans ce qui suit, nous présenterons des contre-mesures générales pour les données déséquilibrées. Dans cet article, je présenterai brièvement uniquement le plan.
Traitement sur données
Le moyen le plus simple est de réduire les données majoritaires (sous-échantillonnage) ou d'augmenter les données minoritaires (suréchantillonnage). Il est également possible de combiner ces deux. En cas de sous-échantillonnage, il existe une méthode utilisant le clustering pour éviter les biais d'échantillonnage. En outre, lors du suréchantillonnage, un algorithme appelé SMOTE est célèbre.
Si vous ajustez les données par échantillonnage, la valeur de score de sortie sera déformée, donc si la valeur de score elle-même est importante, vous devrez corriger la valeur [^ 2]. Si la valeur du score elle-même n'est pas importante et qu'il est important de la diviser en cas positifs et négatifs, aucune correction n'est nécessaire.
Traitement pour l'algorithme
Lors de la formation du modèle, nous résolvons en interne le problème de minimisation de la fonction objective. À ce stade, en ajustant la sanction pour avoir mal jugé le cas négatif qui est la majorité et la sanction pour avoir mal évalué le cas positif qui est la minorité, il est possible de prédire correctement le cas positif qui est la minorité. ..
Supplément: utilisation de l'apprentissage d'ensemble
Lorsque l'on réduit la majorité des données négatives par sous-échantillonnage, on s'attend à ce que la tendance des données négatives change en fonction de la façon dont elles sont réduites. Il existe de nombreuses façons de garder la tendance des données inchangée, mais on dit qu'une méthode qui combine l'apprentissage d'ensemble est un bon moyen de la gérer [^ 3].
Supplément: détection d'anomalies
S'il y a trop de différence dans le nombre de données entre les exemples positifs et négatifs, il est possible de considérer les exemples positifs minoritaires comme anormaux puis d'appliquer l'algorithme de détection d'anomalies (omis dans cet article). ..
4. Expérience
Expérimentez pour mieux comprendre les données déséquilibrées. Dans cette expérience, des données déséquilibrées sont créées à partir de nombres aléatoires qui suivent une distribution normale et évaluées à l'aide de divers modèles. La quantité de données est de 500 pour les cas positifs (y = 1) et de 10000 pour les cas négatifs (y = 0). La quantité de caractéristiques est bidimensionnelle pour souligner la facilité de visualisation.
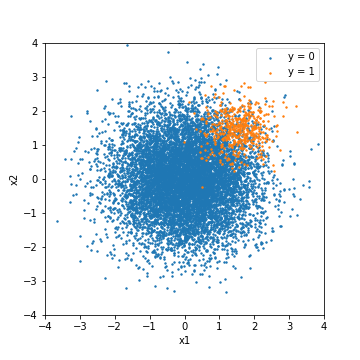
En tant que condition expérimentale minimale, les données d'apprentissage et les données de test sont séparées par 8: 2, et les données de test sont prédites après un simple réglage des paramètres. Dans cette expérience, à des fins de comparaison, le résultat du réglage basé sur la valeur F1 et le résultat du réglage basé sur PR-ROC [^ 4] sont décrits respectivement.
#Lors du réglage avec la valeur f1
GridSearchCV(model, params, scoring="f1")
# PR-Lors du réglage avec AUC
GridSearchCV(model, params, scoring="average_precision")
Lors du fractionnement d'un ensemble de données, essayez de le fractionner tout en maintenant l'équilibre entre les exemples positifs et négatifs [^ 5].
# scikit-apprendre le train_test_Lors de l'utilisation de la fonction Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y)
Retour logistique
Pas d'action
Le premier est le résultat de la prédiction d'une régression logistique normale sans aucune ingéniosité particulière.
--Tuning avec la valeur F1
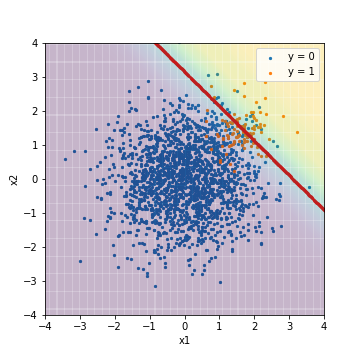
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR@F1 | 0.960 | 0.642 | 0.430 | 0.515 | 0.975 | 0.632 |
La couleur d'arrière-plan indique la valeur du score, et la couleur jaune indique qu'il s'agit d'un exemple positif et la couleur violette indique qu'il s'agit d'un exemple négatif. La ligne rouge est le seuil et les valeurs de Précision, Précision, Rappel et F1 sont calculées à partir des résultats de la classification basée sur ce seuil. Comme prévu, le résultat a été traîné par le cas négatif de la majorité.
ROC-AUC est une valeur incroyable de 0,975.
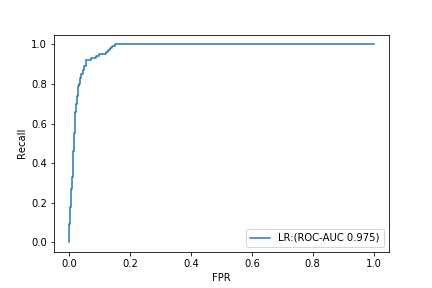
D'autre part, PR-AUC est de 0,632.
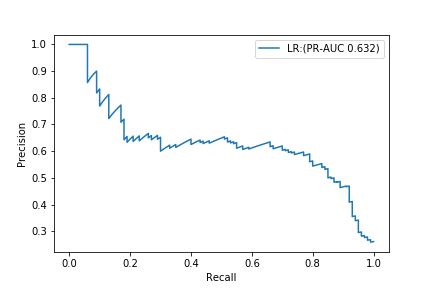
Si vous ne regardez que ROC-AUC, vous penserez que vous avez fait un modèle terriblement bon, mais si vous vérifiez la courbe PR, vous constaterez que ce n'est pas un très bon modèle.
--Tuning avec PR-AUC
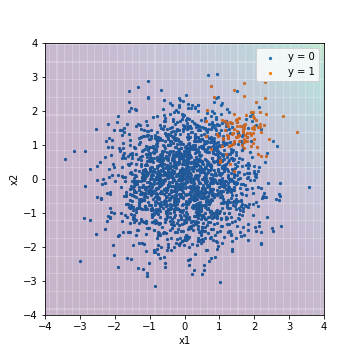
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR@PR-AUC | 0.950 | 0.000 | 0.000 | 0.000 | 0.975 | 0.632 |
Par rapport au résultat du réglage avec la valeur F1, vous pouvez voir que la couleur d'arrière-plan est devenue violette dans l'ensemble (cela a abouti à un exemple négatif). Dans ce résultat, toutes les données sont en dessous du seuil, et les valeurs sont calculées après avoir prédit que tous les indicateurs basés sur le seuil sont des exemples négatifs. D'autre part, les valeurs de ROC-AUC et PR-AUC sont les mêmes que le résultat du réglage avec la valeur F1. En effet, ROC-AUC et PR-AUC ne sont pas les valeurs absolues des scores, mais sont des indicateurs qui évaluent si les résultats de prédiction sont triés par ordre de score, avec des exemples positifs en haut et des exemples négatifs en bas. En d'autres termes, on peut déduire que ces deux types de résultats ont presque le même ordre lorsque les résultats de prédiction sont triés par ordre de score, bien que les valeurs absolues des scores aient changé.
Traitement pour l'algorithme
Vient ensuite le résultat de la régression logistique avec traitement appliqué à l'algorithme. Avec scikit-learn, tout ce que vous avez à faire est de définir le paramètre class_weight.
#Lors de l'application du traitement à l'algorithme
clf = LogisticRegression(class_weight="balanced")
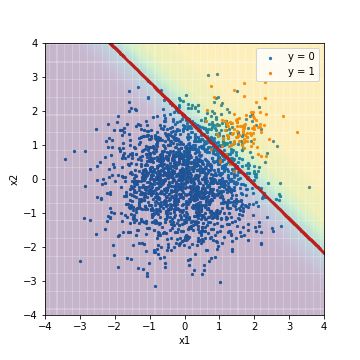
--Tuning avec la valeur F1
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR_weight@F1 | 0.901 | 0.329 | 0.950 | 0.488 | 0.975 | 0.633 |
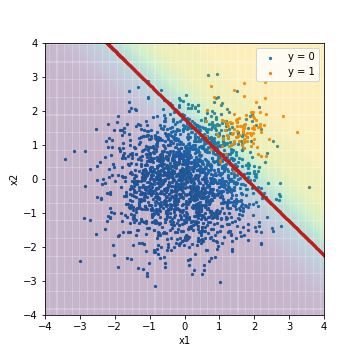
--Tuning avec PR-AUC
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR_weight@PR-AUC | 0.887 | 0.301 | 0.950 | 0.457 | 0.975 | 0.631 |
Par rapport au résultat de la régression logistique normale réglée précédemment avec la valeur F1, vous pouvez voir que l'emplacement du seuil se déplace considérablement vers le bas à gauche afin de prédire correctement l'exemple correct. Parallèlement à cela, Recall augmente fortement. D'autre part, ROC-AUC et PR-AUC ne sont pas très différents. Dans ce cas également, on considère que l'ordre dans lequel les résultats de prédiction sont triés dans l'ordre des scores n'a pas changé, comme dans le cas d'une régression logistique normale.
Traitement sur données
Enfin, il est le résultat d'une régression logistique avec traitement appliqué aux données. Nous utilisons une technique appelée SMOTE Tomek implémentée dans déséquilibré-learn, une bibliothèque de prédiction de données déséquilibrées. Il s'agit d'une méthode qui combine le sous-échantillonnage et le sous-échantillonnage. En appliquant SMOTETomek, les données d'entraînement, qui étaient à l'origine de 400 cas positifs et 7600 cas négatifs, seront de 7439 pour les cas positifs et négatifs.
--Tuning avec la valeur F1
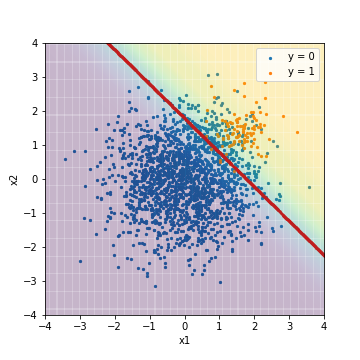
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR_sampling@F1 | 0.891 | 0.308 | 0.950 | 0.466 | 0.975 | 0.632 |
--Tuning avec PR-AUC
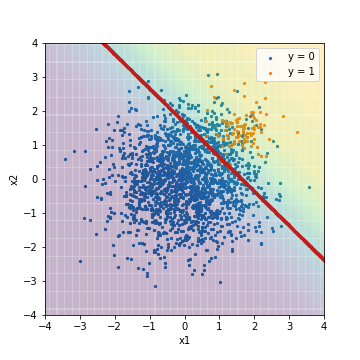
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR_sampling@PR-AUC | 0.873 | 0.279 | 0.970 | 0.433 | 0.975 | 0.632 |
Le résultat est presque le même que celui de la régression logistique appliquant le traitement de l'algorithme. Il n'y a pas de grande différence entre chaque indice.
Les résultats de la régression logistique sont les suivants. Dans cet exemple, évalué du point de vue de PR-AUC, nous pouvons voir que tous les modèles ont les mêmes performances.
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| LR@F1 | 0.960 | 0.642 | 0.430 | 0.515 | 0.975 | 0.632 |
| LR@PR-AUC | 0.950 | 0.000 | 0.000 | 0.000 | 0.975 | 0.632 |
| LR_weight@F1 | 0.901 | 0.329 | 0.950 | 0.488 | 0.975 | 0.633 |
| LR_weight@PR-AUC | 0.887 | 0.301 | 0.950 | 0.457 | 0.975 | 0.631 |
| LR_sampling@F1 | 0.891 | 0.308 | 0.950 | 0.466 | 0.975 | 0.632 |
| LR_sampling@PR-AUC | 0.873 | 0.279 | 0.970 | 0.433 | 0.975 | 0.632 |
Pour SVM (noyau RBF)
Ensuite, j'ai fait une comparaison similaire avec le modèle non linéaire SVM (noyau RBF). La ligne rouge du seuil n'est pas représentée ici.
Pas d'action
Le premier est le résultat de la prédiction d'un SVM normal sans aucune mesure spéciale.
--Tuning avec la valeur F1
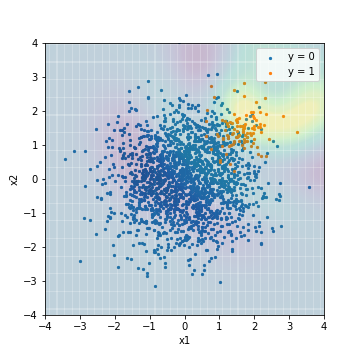
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM@F1 | 0.964 | 0.656 | 0.590 | 0.621 | 0.966 | 0.629 |
--Tuning avec PR-AUC
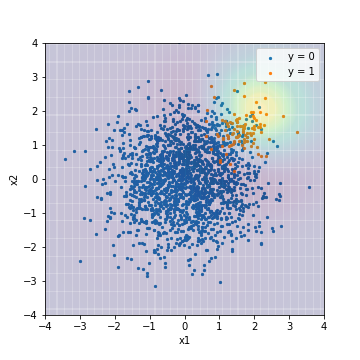
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM@PR-AUC | 0.950 | 0.000 | 0.000 | 0.000 | 0.934 | 0.650 |
Contrairement au résultat de la régression logistique, il existe une nette différence dans le résultat selon qu'il est réglé avec la valeur F1 ou PR-AUC. Le score, lorsqu'il est réglé avec PR-AUC, devrait diminuer radialement à partir du coin supérieur droit du centre de l'exemple, ce qui semble être un résultat raisonnable pour ce modèle qui ne traite pas des données déséquilibrées. .. Au contraire, le score lorsqu'il est réglé avec la valeur F1 semble un peu artificiel. ** Les SVM réellement réglés avec PR-AUC ont une PR-AUC plus élevée que tous les modèles de régression logistique, tandis que les SVM réglés avec la valeur F1 ont une PR-AUC plus faible que tous les modèles de régression logistique. Je vais. ** Sur cette base, on pense que l'indice d'évaluation au moment du réglage est important lors de la construction d'un modèle avec une expressivité riche.
Traitement pour l'algorithme
Vient ensuite le résultat du SVM ajusté pour l'algorithme.
clf = SVC(class_weight="balanced")
--Tuning avec la valeur F1
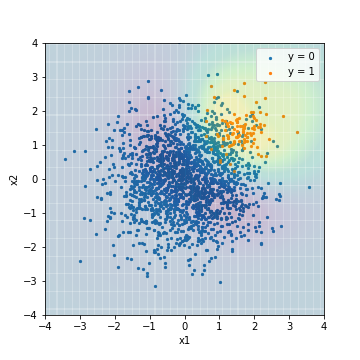
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM_weight@F1 | 0.904 | 0.339 | 0.970 | 0.503 | 0.976 | 0.575 |
--Tuning avec PR-AUC
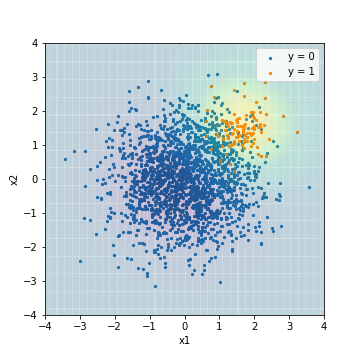
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM_weight@PR-AUC | 0.050 | 0.050 | 1.00 | 0.095 | 0.978 | 0.639 |
Dans tous les résultats, on peut voir que le modèle est entraîné pour prédire l'exemple correct plus correctement que le résultat normal de la prédiction SVM. D'autre part, le PR-AUC de SVM réglé avec la valeur F1 est de 0,575, ce qui est le pire jamais enregistré.
Traitement sur données
Enfin, c'est le résultat de SVM qui a appliqué le traitement aux données.
--Tuning avec la valeur F1
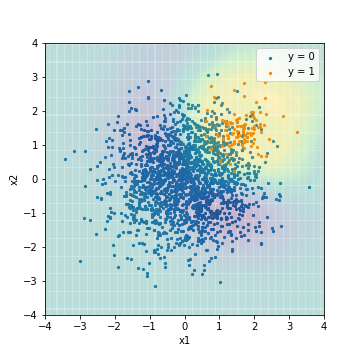
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM_sampling@F1 | 0.903 | 0.338 | 0.990 | 0.504 | 0.968 | 0.473 |
--Tuning avec PR-AUC
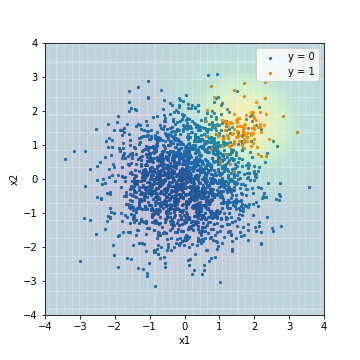
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM_sampling@PR-AUC | 0.877 | 0.289 | 1.0 | 0.448 | 0.978 | 0.637 |
La tendance générale était similaire au résultat de l'application du traitement SVM à l'algorithme. D'autre part, le PR-AUC du modèle réglé avec la valeur F1 est devenu encore pire à 0,473.
Le résultat de SVM est le suivant. Dans cet exemple, lors de l'évaluation du point de vue de PR-AUC, il a été constaté que les performances diminuent considérablement à moins que PR-AUC ne soit défini comme l'indice d'évaluation lors du réglage. On pense que cela est dû au fait que SVM est un modèle hautement expressif, donc comparé aux modèles linéaires tels que la régression logistique, il s'agit d'un modèle spécialisé dans l'indice d'évaluation utilisé pour le réglage.
| Accuacy | Precision | Recall | F1 | ROC-AUC | PR-AUC | |
|---|---|---|---|---|---|---|
| SVM@F1 | 0.964 | 0.656 | 0.590 | 0.621 | 0.966 | 0.629 |
| SVM@PR-AUC | 0.950 | 0.000 | 0.000 | 0.000 | 0.934 | 0.650 |
| SVM_weight@F1 | 0.904 | 0.339 | 0.970 | 0.503 | 0.976 | 0.575 |
| SVM_weight@PR-AUC | 0.050 | 0.050 | 1.00 | 0.095 | 0.978 | 0.639 |
| SVM_sampling@F1 | 0.903 | 0.338 | 0.990 | 0.504 | 0.968 | 0.473 |
| SVM_sampling@PR-AUC | 0.877 | 0.289 | 1.0 | 0.448 | 0.978 | 0.637 |
Comparaison de la courbe PR
Enfin, les courbes PR des 6 types de modèles (réglés avec PR-AUC) testés dans cette expérience sont arrangées.
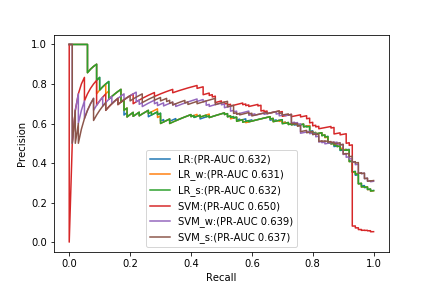
En comparaison avec PR-AUC seul, le meilleur modèle est un SVM normal qui ne traite de rien, mais lorsque le rappel est élevé, la précision du SVM baisse fortement, et il vaut mieux utiliser un autre modèle. Je vais. À partir de ce résultat, vous pouvez voir qu'il est difficile de sélectionner un modèle approprié avec PR-AUC seul. Encore une fois, je pense qu'il est important de considérer l'équilibre entre la précision et le rappel à partir de la courbe ** PR et de trouver le modèle le plus performant pour ce problème. ** **
Résumé
- Dessinons une courbe PR!
référence
- Données déséquilibrées - Exemple d'implémentation d'un défaut de courbe ROC
- Différence de comportement entre la courbe PR et la courbe ROC dans les données de déséquilibre
- Indice d'évaluation de l'apprentissage automatique qui peut être compris à partir de zéro! Taux d'ajustement-taux de rappel / courbe ROC et AUC
- Discussion sur la différence entre la courbe ROC et la courbe PR
[^ 1]: Il existe également un indice appelé valeur Fβ, qui est une généralisation de la valeur F1. Vous pouvez ajuster la priorité de Précision et Rappel en ajustant la valeur de β. [^ 2]: Biais de probabilité de prédiction dû au sous-échantillonnage [^ 3]: Imbalanced-learn, une bibliothèque de prédiction de données non équilibrées, fournit une classe pratique appelée BalancedBaggingClassifier pour implémenter cette méthode. [^ 4]: La précision moyenne spécifiée dans le paramètre de notation est une approximation de PR-ROC. Référence: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.average_precision_score.html [^ 5]: GridSearchCV est divisé en couches (tout en maintenant l'équilibre) par défaut pour la classification binaire.
Recommended Posts