[PYTHON] Finden des Beginns der Avenomics anhand der NT-Vergrößerung 1
Paarhandel mit NT-Vergrößerung
Pairs Trade ist eine bekannte Handelsmethode, bei der zwei Aktien verwendet werden, die sich ähnlich verhalten. Wenn es einen Unterschied zwischen den beiden Bewegungen gibt, ist dies eine Methode, um einen Gewinn zu erzielen, indem eine Position eingenommen wird, die den Unterschied ausfüllt, und dies wird auch von Hedgefonds durchgeführt.
Die Methode wird ausführlich in der kürzlich gelesenen "Zeitreihendatenanalyse, die sofort vor Ort verwendet werden kann" erläutert, und theoretisch scheint es eine Voraussetzung zu sein, dass der Paarhandel hergestellt wird, wenn beide eine republikanische Kointegrationsbeziehung haben. Zuerst wollte ich einen Backtest machen, um zu sehen, ob ich Gewinn machen kann. In Japan wird die NT-Vergrößerung als Material für den Paarhandel verwendet, aber wie einige von Ihnen vielleicht wissen, wird das Verhältnis der beiden Indizes Nikkei225 und Topix als NT-Vergrößerung (= Nikkei225 / Topix) bezeichnet. Es stellt sich die Frage, ob die Kombination von Indizes theoretisch ist, aber ich habe beschlossen, sie als beliebte Methode zu betrachten.
Während der Untersuchung sah ich eine große Veränderung im Trend, daher dachte ich unter dem Titel "Untersuchung des Beginns der Avenomics" darüber nach.
Historisches Diagramm und Streudiagramm
Erstens die Beobachtung von Zeitreihendaten.

Da sowohl Topix als auch Nikkei225 Aktienindizes sind, die aus den Aktienkursen des ersten Teils der Tokioter Börse berechnet werden, sind die Bewegungen ziemlich ähnlich. Die y-Achsenskala unterscheidet sich im Diagramm (Nikkei225-links, Topix-rechts), aber die Linien überlappen sich von 2005 bis 2009 fast. Sie können auch den Trend sehen, bei dem Nikkei225 seit etwa 2010 von der Topix-Linie aufgestiegen ist.
Als nächstes schauen wir uns Scatter Plot an.

In diesem Diagramm können wir sehen, dass sich das Diagramm in der Nähe von zwei geraden Linien befindet. Wenn man dies zusammen mit dem ersten Diagramm und dem historischen Diagramm betrachtet, kann man schließen, dass die gerade Linie mit der kleineren Steigung zunächst der Trend von NT war, sich jedoch im Laufe der Zeit in den Trend mit der größeren Steigung änderte. Basierend auf dieser Idee haben wir dann eine Regressionsanalyse durchgeführt. Übrigens ist das historische Diagramm der NT-Vergrößerung selbst wie folgt.

Regressionsanalyse durch Statistikmodelle
Dieses Mal haben wir eine lineare Regressionsanalyse durchgeführt, aber das Python-Modul verwendete ** StatsModels **. Aus den Zeitreihendaten von (Topix, Nikkei225) wurden Daten durch Einstellen von zwei Zeitintervallen extrahiert und jeweils eine Regression durchgeführt. Die Zeitintervalle sind 2005 / B ~ 2008 / E und 2012 / B ~ 2014 / E. Ersteres ist vor dem "Lehman-Schock", und letzteres ist die sogenannte "Abenomics" -Ära.
import statsmodels.api as sm
# ... pre-process ...
# Regression Analysis
index_s1 = pd.date_range(start='2005/1/1', end='2008/12/31', freq='B')
x1 = pd.DataFrame(index=index_s1); y1 = pd.DataFrame(index=index_s1)
x1['topix'] = mypair['topix'] # 2005 .. 2008/E
y1['n225'] = mypair['n225']
x1 = sm.add_constant(x1)
model1 = sm.OLS(y1[1:], x1[1:])
mytrend1 = model1.fit()
print mytrend1.summary()
index_s2 = pd.date_range(start='2012/1/1', end='2014/12/31', freq='B')
x2 = pd.DataFrame(index=index_s2); y2 = pd.DataFrame(index=index_s2)
x2['topix'] = mypair['topix'] # 2012 .. 2014/E
y2['n225'] = mypair['n225']
x2 = sm.add_constant(x2)
model2 = sm.OLS(y2[1:], x2[1:])
mytrend2 = model2.fit()
print mytrend2.summary()
# Plot fitted line
plt.figure(figsize=(8,5))
plt.plot(mypair['topix'], mypair['n225'], '.')
plt.plot(x1.iloc[1:,1], mytrend1.fittedvalues, 'r-', lw=1.5, label='2005-2008E')
plt.plot(x2.iloc[1:,1], mytrend2.fittedvalues, 'g-', lw=1.5, label='2012-2014E')
plt.grid(True)
plt.legend(loc=0)
Nachdem alle Daten im DataFrame-Objekt mit dem Namen mypair [['topix', 'n225']] in Pandas festgelegt wurden, wurde die obige Liste ausgeführt.
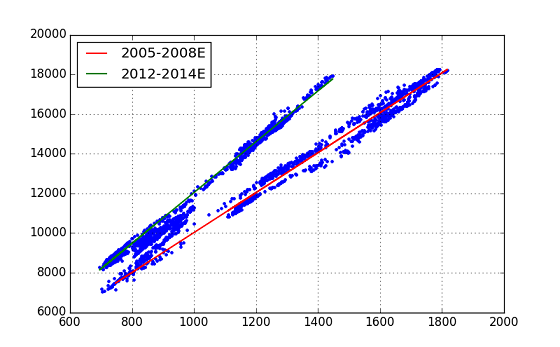
Ich konnte die beiden geraden Linien ordentlich anpassen. Es ist eine Bewertung der Regressionsanalyse, zeigt jedoch eine Zahl, die die Erwartungen übertrifft. (Beide Regressionsberechnungen haben gute Ergebnisse, aber ein Ergebnis wird angezeigt.)
>>> print mytrend1.summary()
OLS Regression Results (Early period, 2005-2008E)
==============================================================================
Dep. Variable: n225 R-squared: 0.981
Model: OLS Adj. R-squared: 0.981
Method: Least Squares F-statistic: 5.454e+04
Date: Sun, 21 Jun 2015 Prob (F-statistic): 0.00
Time: 17:11:26 Log-Likelihood: -7586.3
No. Observations: 1042 AIC: 1.518e+04
Df Residuals: 1040 BIC: 1.519e+04
Df Model: 1
==============================================================================
coef std err t P>|t| [95.0% Conf. Int.]
------------------------------------------------------------------------------
const -45.0709 62.890 -0.717 0.474 -168.477 78.335
topix 10.0678 0.043 233.545 0.000 9.983 10.152
==============================================================================
Omnibus: 71.316 Durbin-Watson: 0.018
Prob(Omnibus): 0.000 Jarque-Bera (JB): 30.237
Skew: -0.189 Prob(JB): 2.72e-07
Kurtosis: 2.256 Cond. No. 8.42e+03
==============================================================================
Warnings:
[1] The condition number is large, 8.42e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
Der Bestimmungskoeffizient R-squired beträgt 0,981, F-stat 5,454e + 04 p-Wert 0,00 (!). Wie oben erwähnt, ist die bedingte Zahl aus dem Programm zu groß, nicht wahr? von Warnung ist aufgetreten. (Dieses Mal habe ich diese Warnung nicht eingehend verfolgt ... Bitte geben Sie mir einen Rat.)
Die Gleichungen für die beiden aus dieser Regressionsanalyse (coef) erhaltenen Trendlinien lauten wie folgt. Period-1(2005-2008) : n225 = topix x 10.06 - ** 45.07 ** Period-2(2012-2014) : n225 = topix x 12.81 - 773.24
Es kann gesagt werden, dass sich der Index der NT-Vergrößerung von ** 10,06 ** auf ** 12,81 ** geändert hat. Eine Frage ist jedoch, warum diese große Änderung im historischen Diagramm von NT nicht sichtbar ist.

Da sich der Achsenabschnitt von Periode 1 zu Periode 2 änderte, fragte ich auch nach 'ntr2' (grüne Linie), die den Effekt beseitigte, aber es wurde gesagt, dass NT schrittweise sprang (von 10.06 auf 12.81). Es scheint nicht der Fall zu sein.
Die Schlussfolgerung aus der bisherigen Analyse lautet, dass ** "Avenomics zwischen 2009 und 2012 (früh) begann" **. Es ist kein ordentliches Ergebnis, aber es ist natürlich (aus diesem Ergebnis) zu glauben, dass dieser wirtschaftliche Trend bereits begonnen hat, zumindest im Dezember 2012, als Premierminister Abe sein Amt als Premierminister für die zweite Amtszeit antrat.
(Da die Schlussfolgerung nicht klar ist, habe ich die Klassifizierung mit scikit-learn next durchgeführt. Siehe Artikel "2".)
Verweise
- "Zeitreihendatenanalyse, die sofort vor Ort verwendet werden kann" (Daisuke Yokouchi (Autor), Yoshimitsu Aoki (Autor), Technical Review) http://gihyo.jp/book/2014/978-4-7741-6301-7
- "Python for Finance": (O'reilly Media) http://shop.oreilly.com/product/0636920032441.do --pandas document http://pandas.pydata.org/pandas-docs/stable/index.html --StatsModels-Dokument http://statsmodels.sourceforge.net/stable/
Recommended Posts