[PYTHON] Visualisierung, wo bei der Klassifizierung der Datenanalyse eine Fehlklassifizierung auftritt
Identifizieren Sie, wo die Fehlklassifizierung aufgetreten ist, um die Genauigkeit der Datenanalyseergebnisse zu verbessern
Das ist das Thema dieser Zeit.
Daher werde ich heute die Verwirrungsmatrix verwenden, um zu visualisieren, wo die Fehlklassifizierung stattgefunden hat.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix
clf = DecisionTreeClassifier()
clf.fit(X_train, Y_train)
result = clf.predict(X_test)
cm = confusion_matrix(Y_test, result)
print(cm)
Wenn Sie den Iris-Datensatz verwenden, wird er wie in der folgenden Abbildung dargestellt angezeigt.
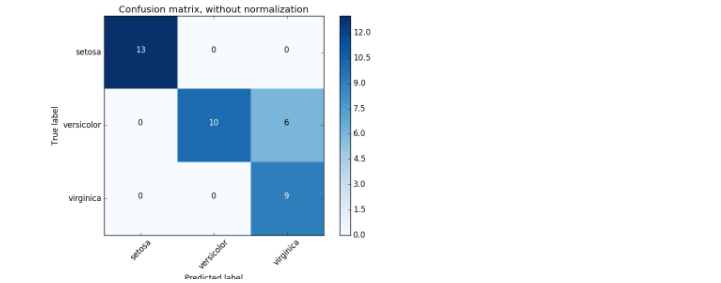 Auszug aus sklearn Offizielles Dokument
Auszug aus sklearn Offizielles Dokument
Es mag etwas klein und schwer zu erkennen sein, aber die y-Achse ist der wahre Wert, dh die korrekte Beschriftung, die x-Achse ist der vorhergesagte Wert und sie wird unter Verwendung eines maschinellen Lernmodells beschriftet. In der obigen Abbildung befindet sich rechts in der mittleren Reihe eine Fehlklassifizierung.
Wenn Sie dies erkennen, die Datenvorverarbeitung überprüfen und die Parameter des maschinellen Lernmodells neu anpassen, kann dies die Genauigkeit verbessern.
Recommended Posts