Scraping von Websites mit JavaScript in Python
Überblick
Ich habe Python verwendet, um eine Site zu kratzen, die DOM mit JavaScript erstellt. Notieren Sie sich daher die Prozedur.
Ungefähr habe ich eine Kombination aus Scrapy und Selenium gemacht.
Scrapy
Scrapy ist ein Framework für die Implementierung von Crawlern.
Implementieren Sie den Crawler als eine Klasse, die die vom Framework festgelegte Schnittstelle erfüllt, z. B. den Crawler als Unterklasse von * Spider *, die kratzenden Informationen als Unterklasse von * Item * und die Verarbeitung der kratzenden Informationen als Unterklasse von * Pipeline *.
Es wird ein Befehl namens * Scrapy * bereitgestellt, mit dem Sie eine Liste Ihrer Crawler anzeigen und starten können.
Selenium
Selenium ist ein Tool zur programmgesteuerten Steuerung des Browsers (ist das in Ordnung?). Es kann in verschiedenen Sprachen einschließlich Python verwendet werden. Es erscheint häufig im automatisierten Testkontext von Websites / Apps. Sie können damit JavaScript ausführen und HTML-Quellen, einschließlich dynamisch generierter DOMs, kratzen.
Ursprünglich schien es den Browser über JavaScript zu steuern, aber jetzt sendet es eine Nachricht direkt an den Browser, um den Browser zu steuern.
Als ich es in meiner Umgebung (OSX) ausprobierte, konnte ich es in Safari und Chrome nicht verwenden, ohne so etwas wie eine Erweiterung zu installieren. Sie können es so verwenden, wie es mit Firefox ist. Wenn Sie PhantomJS einschließen, können Sie ohne Fenster kratzen und es auf dem Server verwenden.
Warum Scrapy verwenden?
Sie können mit Selen allein ohne Scrapy kratzen,
- Mehrere Seiten parallel kratzen (Multithread? Prozess?), ――Wie viele Seiten gecrawlt wurden, wie oft der Fehler aufgetreten ist und das Protokoll gut organisiert ist.
- Vermeidet das Duplizieren von gecrawlten Seiten,
- Bietet verschiedene Einstellungsoptionen wie Crawling-Intervall,
- Kombinieren Sie CSS und XPath, um Informationen aus DOM zu erhalten (Kombination ist sehr praktisch!), --Crawl-Ergebnisse können in JSON oder XML ausgespuckt werden.
- Sie können einen Crawler mit einem schönen Programmdesign schreiben (ich denke, es ist besser, als es selbst zu entwerfen),
Das Verdienst, Scrapy zu verwenden, ist wie folgt.
Das Studieren des Frameworks war zunächst mühsam, daher habe ich den Crawler nur mit Selenium und PyQuery implementiert, aber wenn ich Protokolle und Fehlerbehandlung geschrieben habe Das Gefühl der Neuerfindung des Rades wurde stärker und ich blieb stehen.
Vor der Implementierung habe ich Scrapy-Dokumentation von Anfang an auf der Seite "Einstellungen" und um * Architekturübersicht * und * Downloader-Middleware * gelesen.
Verwenden Sie Scrapy und Selen in Kombination
Die ursprüngliche Geschichte ist dieser Stapelüberlauf.
Die Architektur von Scrapy sieht folgendermaßen aus (aus Scrapys Dokumentation).
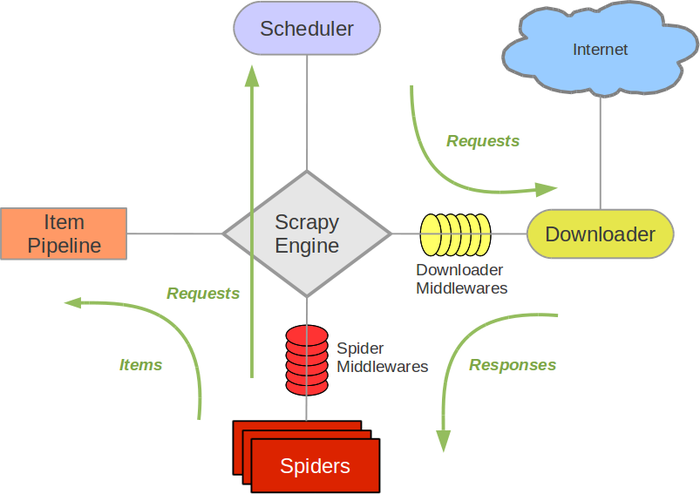
Passen Sie * Downloader Middlewares * an, damit Scrapy's Spider mit Selen kratzen kann.
Implementierung der Downloader Middleware
Downloader Middleware wird als normale Klasse implementiert, die * process_request * implementiert.
selenium_middleware.py
# -*- coding: utf-8 -*-
import os.path
from urlparse import urlparse
import arrow
from scrapy.http import HtmlResponse
from selenium.webdriver import Firefox
driver = Firefox()
class SeleniumMiddleware(object):
def process_request(self, request, spider):
driver.get(request.url)
return HtmlResponse(driver.current_url,
body = driver.page_source,
encoding = 'utf-8',
request = request)
def close_driver():
driver.close()
Wenn Sie diese Download-Middleware registrieren, ruft * Spider * * process_request * auf, bevor Sie die Seite durchsuchen. Weitere Informationen finden Sie hier (http://doc.scrapy.org/en/1.0/topics/downloader-middleware.html).
Da eine Instanz von * HtmlResponse * zurückgegeben wird, wird Download Middleware danach nicht mehr aufgerufen. Abhängig von der Prioritätseinstellung Standard-Donwload-Middleware (z. B. Parsing robots.txt) Beachten Sie, dass es nicht aufgerufen wird.
Oben verwende ich Firefox, aber wenn ich PhantomJS verwenden möchte, schreibe die Variable * driver * neu.
Laden Sie die Middleware-Registrierung herunter
Registrieren Sie * Selenium Middleware * in der * Spider * -Klasse, die Sie verwenden möchten.
some_spider.py
# -*- coding: utf-8 -*-
import scrapy
from ..selenium_middleware import close_driver
class SomeSpider(scrapy.Spider):
name = "some_spider"
allowed_domains = ["somedomain"]
start_urls = (
'http://somedomain/',
)
custom_settings = {
"DOWNLOADER_MIDDLEWARES": {
"some_crawler.selenium_middleware.SeleniumMiddleware": 0,
},
"DOWNLOAD_DELAY": 0.5,
}
def parse(self, response):
#Crawler-Verarbeitung
def closed(self, reason):
close_driver()
- DOWNLOADER_MIDDLEWARES * in * custom_settings * ist die Einstellung. Ich schreibe die Verarbeitung der * close * -Methode, um das zum Scraping verwendete Firefox-Fenster zu schließen.
Recommended Posts