[PYTHON] Entscheidungsbaum und zufälliger Wald
Was ist ein Entscheidungsbaum?
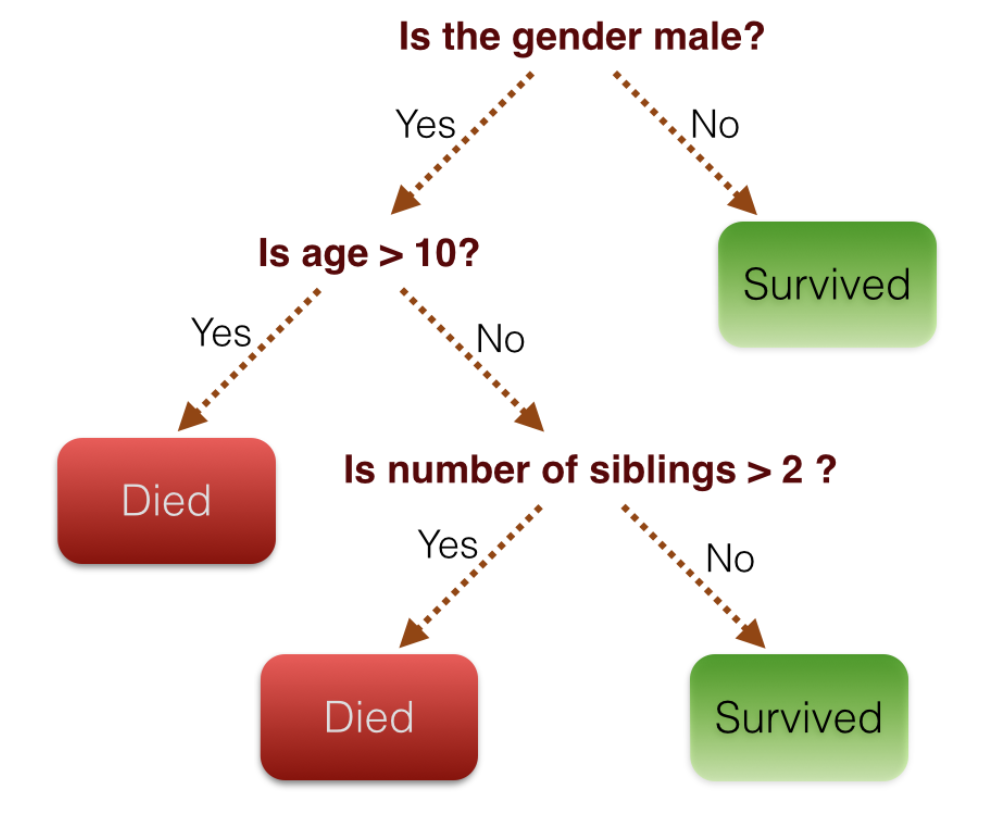
Eine Methode zur Berechnung der Wahrscheinlichkeit der Zugehörigkeit zur Zielvariablen durch Kombination mehrerer erklärender Variablen. Das folgende Bild berechnet die Wahrscheinlichkeit basierend darauf, ob es zu Bedingungen wie Ja / Nein gehört.
Was ist zufälliger Wald?
Random Forest ist eine der Ensemble-Lernmethoden (Klassifikatoren, die aus mehreren Klassifikatoren bestehen). Da mehrere Entscheidungsbäume gesammelt und verwendet werden, werden die Bäume gesammelt und als Wald verwendet.
Probieren Sie es aus (Entscheidungsbaum in sklearn)
Daten bereit
Bereiten Sie zufällig erstellte Daten vor.
{get_dummy_dataset.py}
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn
%matplotlib inline
from sklearn.datasets import make_blobs #Zum Generieren von Dummy-Daten
X, y = make_blobs(n_samples=500, centers=4, random_state=8, cluster_std=2.4)
# n_samples:Anzahl der Probenzentren:Anzahl der zufälligen Mittelpunkte_state:Startwertcluster_std:Variationsgrad
Datenübersicht
{display_dummy_dataset.py}
plt.figure(figsize =(10,10))
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='jet')
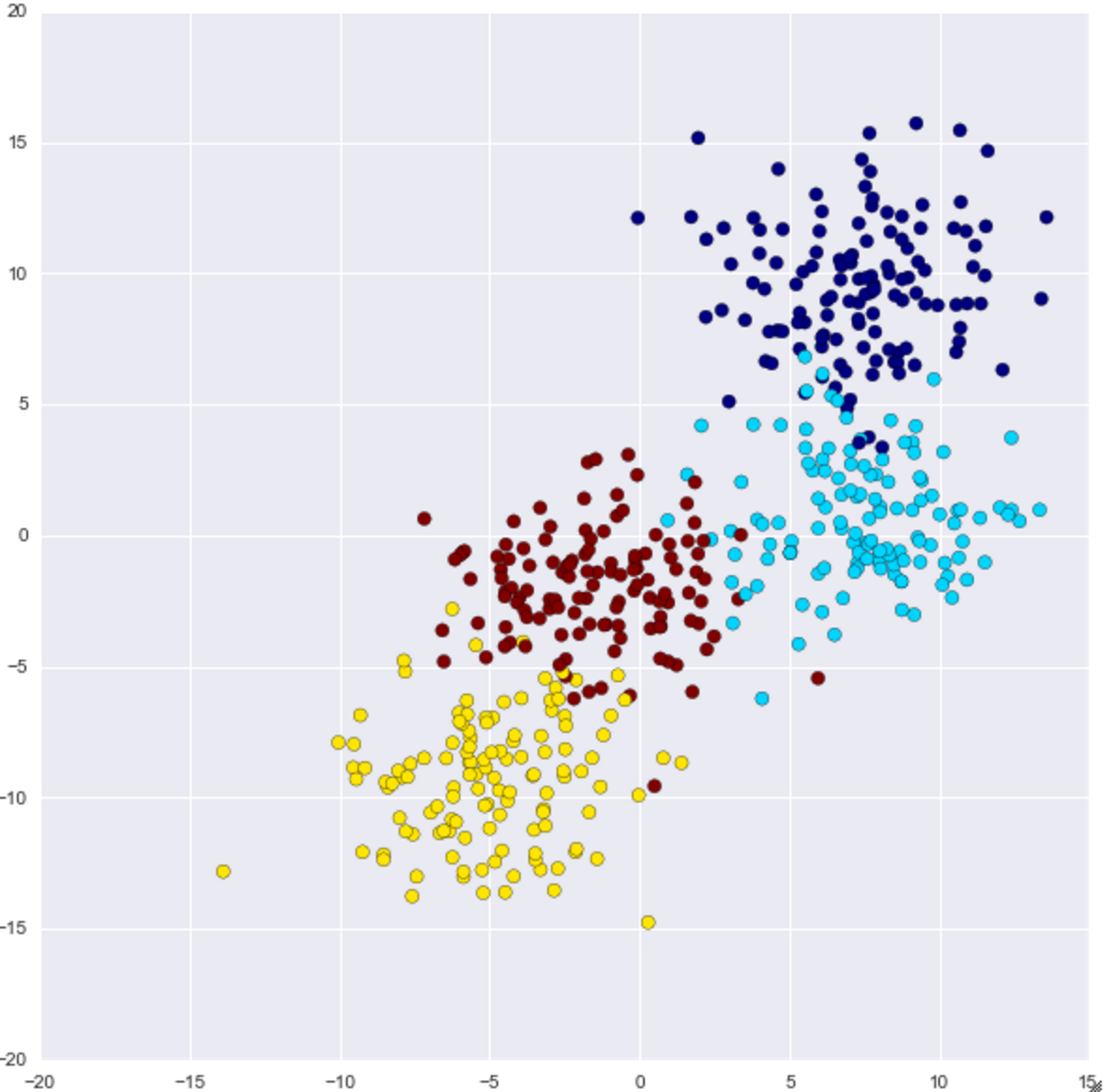
Die Verteilung von 500 Daten, die aus den vier Mittelpunkten generiert wurden, sieht folgendermaßen aus.
Probieren Sie den Entscheidungsbaum aus
Der Code für visualize_tree steht unten.
{do_decision_tree.py}
from sklearn.tree import DecisionTreeClassifier #Für Entscheidungsbaum
clf = DecisionTreeClassifier(max_depth=2, random_state = 0) #Instanzerstellung max_depth:Baumtiefe
visualize_tree(clf, X, y) #Ausführung zeichnen
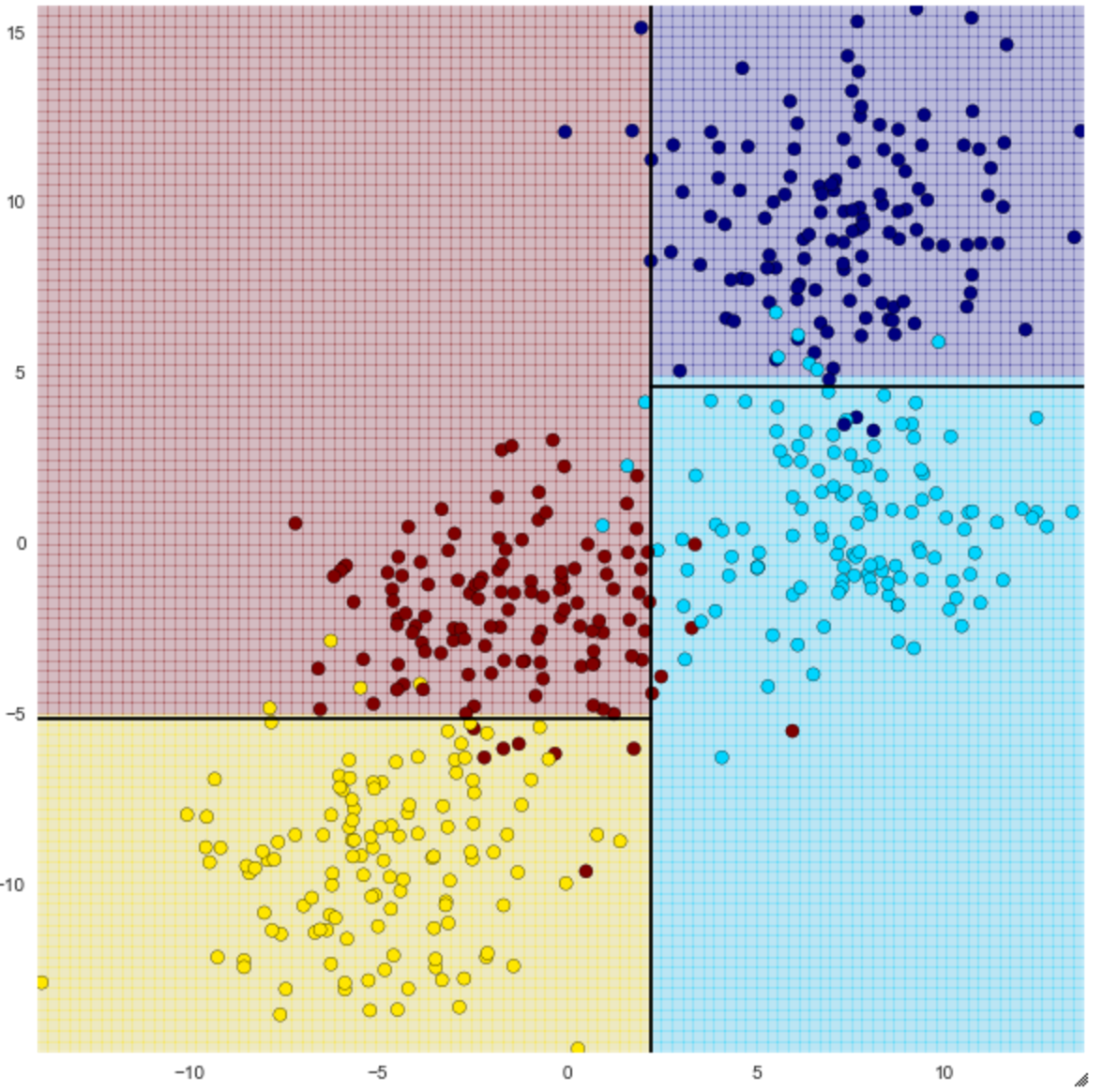
Sie können sehen, wie es mit geraden Linien in vier klassifiziert werden kann. Die Genauigkeit ändert sich abhängig von der Anzahl der Tiefen (max_depth) des Entscheidungsbaums. Wenn ich also max_depth auf 4 setze, sieht es wie folgt aus.
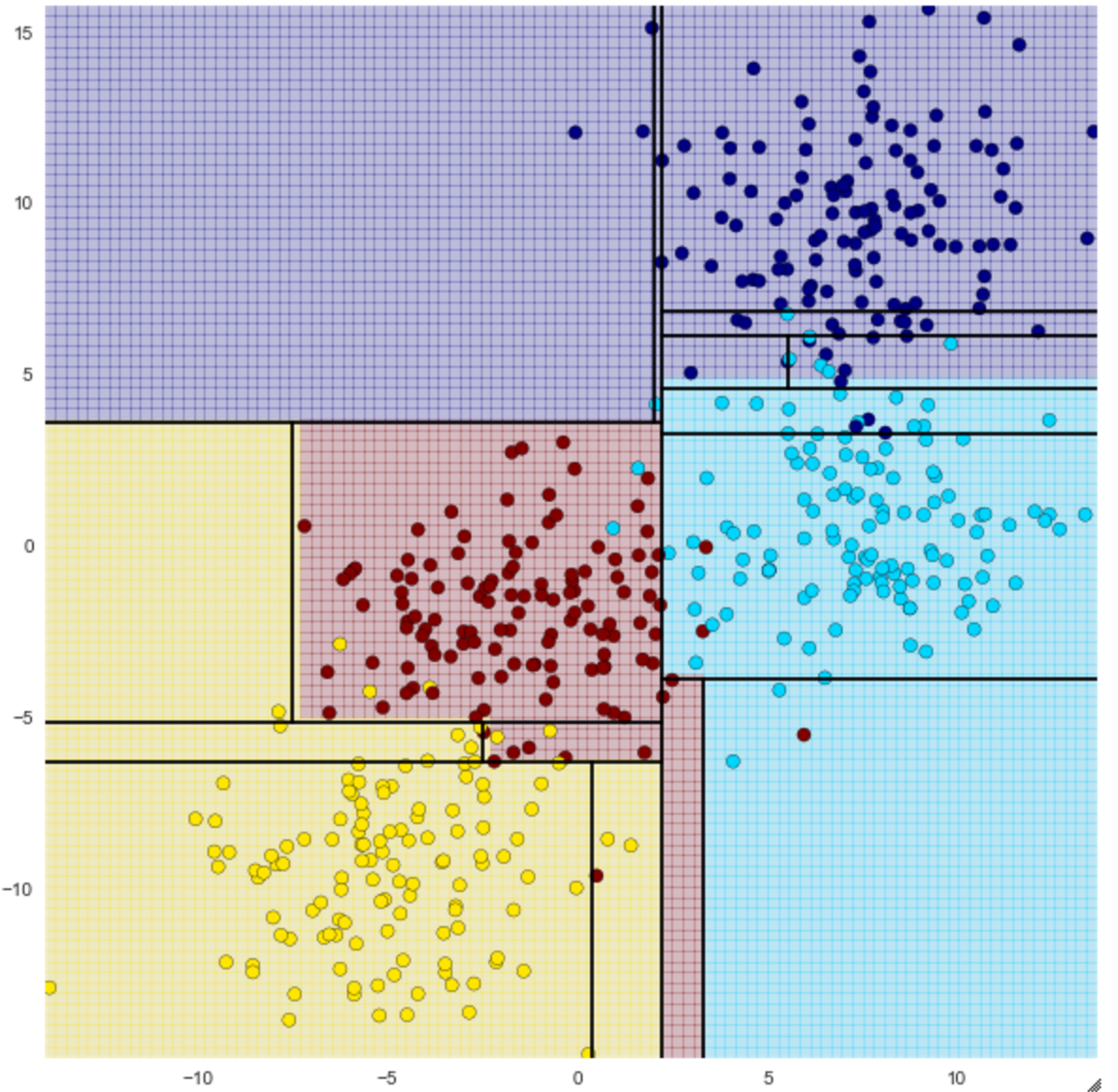
Ab Tiefe 2 können Sie sehen, dass Sie versuchen, eine feinere Klassifizierung vorzunehmen.
Je größer die Tiefe ist, desto genauer sind die Trainingsdaten, aber desto einfacher ist das Überlernen. Um dies zu vermeiden, versuchen Sie, eine zufällige Gesamtstruktur auszuführen.
Versuchen Sie es mit einem zufälligen Wald
{do_random_forest.py}
from sklearn.ensemble import RandomForestClassifier #Für zufälligen Wald
clf = RandomForestClassifier(n_estimators=100, random_state=0) #Instanzerstellung n_estimators:Angabe der Anzahl der zu treffenden Entscheidungsbäume
visualize_tree(clf, X, y, boundaries=False)
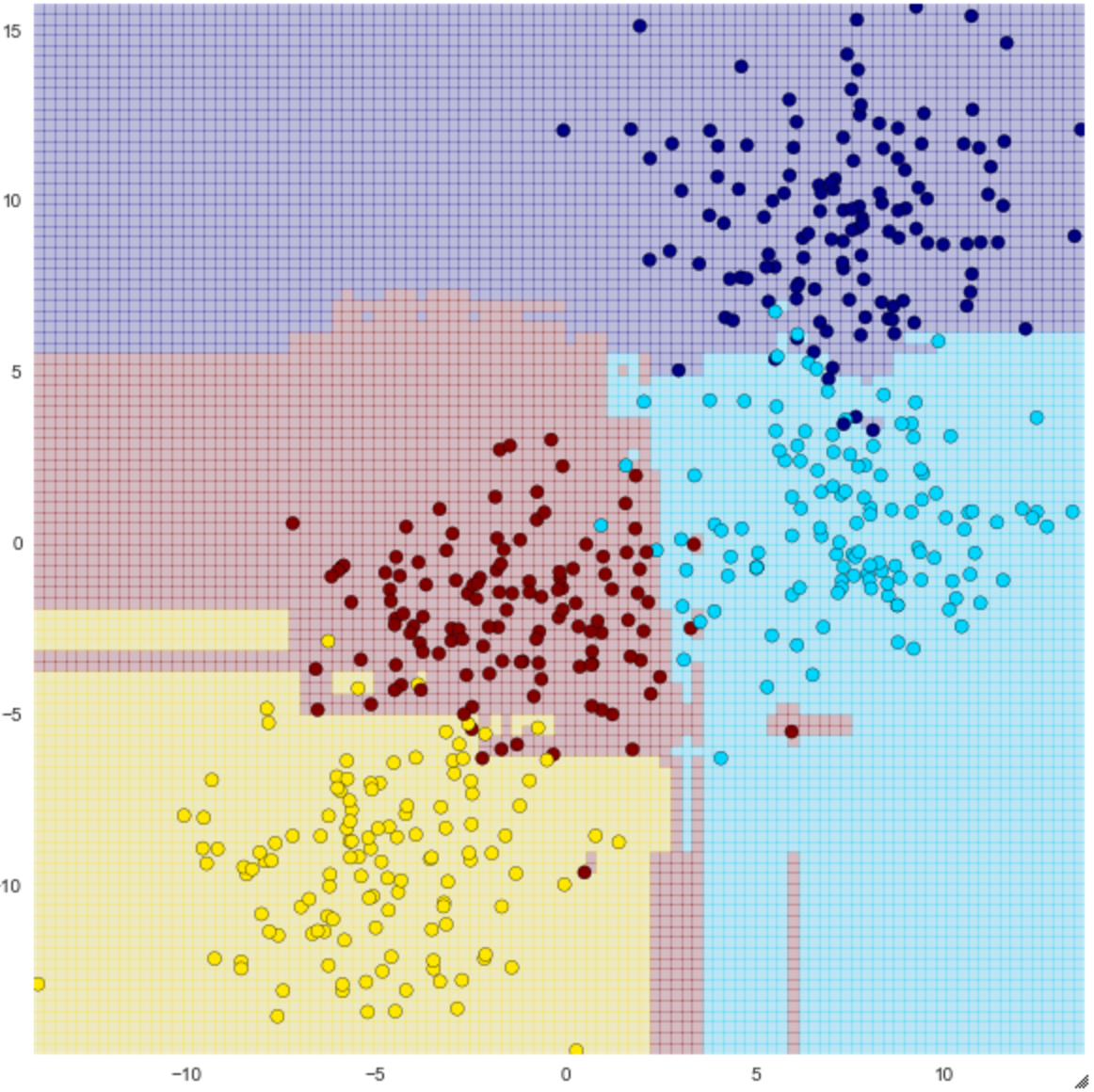
Es ist ersichtlich, dass die Klassifizierung keine einfache gerade Linie ist, aber sie scheint genauer zu sein als ein Entscheidungsbaum. Dies verhindert übrigens nicht immer ein Überlernen. Beispielsweise scheint der rote Kreis unten rechts in der obigen Abbildung keinen Wert zu haben, er ist jedoch mit Rot gruppiert.
Eine Funktion, die das Ergebnis visualisiert.
{visualize_tree.py}
#Versuchen Sie, einen Entscheidungsbaum zu zeichnen
def visualize_tree(classifier, X, y, boundaries=True,xlim=None, ylim=None):
"""Visualisierungsfunktion des Entscheidungsbaums.
INPUTS:Klassifizierungsmodell, X, y, optional x/y limits.
OUTPUTS:Visualisierung von Entscheidungsbäumen mit Meshgrid
"""
#Erstellen eines Modells mit fit
classifier.fit(X, y)
#Automatische Einstellung der Achse
if xlim is None:
xlim = (X[:, 0].min() - 0.1, X[:, 0].max() + 0.1)
if ylim is None:
ylim = (X[:, 1].min() - 0.1, X[:, 1].max() + 0.1)
x_min, x_max = xlim
y_min, y_max = ylim
#Erstellen Sie ein Netzgitter.
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),np.linspace(y_min, y_max, 100))
#Führen Sie Klassifikatorvorhersagen durch
Z = classifier.predict(np.c_[xx.ravel(), yy.ravel()])
#Mit Meshgrid geformt.
Z = Z.reshape(xx.shape)
#Durch Klassifizierung gefärbt.
plt.figure(figsize=(10,10))
plt.pcolormesh(xx, yy, Z, alpha=0.2, cmap='jet')
#Trainingsdaten zeichnen.
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='jet')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
def plot_boundaries(i, xlim, ylim):
'''
Zeichne einen Rand.
'''
if i < 0:
return
tree = classifier.tree_
#Rufen Sie rekursiv auf, um die Grenzen zu ziehen.
if tree.feature[i] == 0:
plt.plot([tree.threshold[i], tree.threshold[i]], ylim, '-k')
plot_boundaries(tree.children_left[i], [xlim[0], tree.threshold[i]], ylim)
plot_boundaries(tree.children_right[i], [tree.threshold[i], xlim[1]], ylim)
elif tree.feature[i] == 1:
plt.plot(xlim, [tree.threshold[i], tree.threshold[i]], '-k')
plot_boundaries(tree.children_left[i], xlim,
[ylim[0], tree.threshold[i]])
plot_boundaries(tree.children_right[i], xlim,
[tree.threshold[i], ylim[1]])
if boundaries:
plot_boundaries(0, plt.xlim(), plt.ylim())
Versuchen Sie eine Regression in einem zufälligen Wald
Zufällige Wälder können ebenfalls zurückkehren.
Verwenden Sie sin, um Daten vorzubereiten, die kleine Wellen in großen Wellen bewegen
{get_dummy_malti_sin_dataset.py}
from sklearn.ensemble import RandomForestRegressor
x = 10 * np.random.rand(100)
def sin_model(x, sigma=0.2):
"""Dummy-Daten bestehend aus großen Wellen + kleinen Wellen + Rauschen."""
noise = sigma * np.random.randn(len(x))
return np.sin(5 * x) + np.sin(0.5 * x) + noise
#Berechnen Sie y aus x
y = sin_model(x)
#Versuchen Sie es mit Plot.
plt.figure(figsize=(16,8))
plt.errorbar(x, y, 0.1, fmt='o')
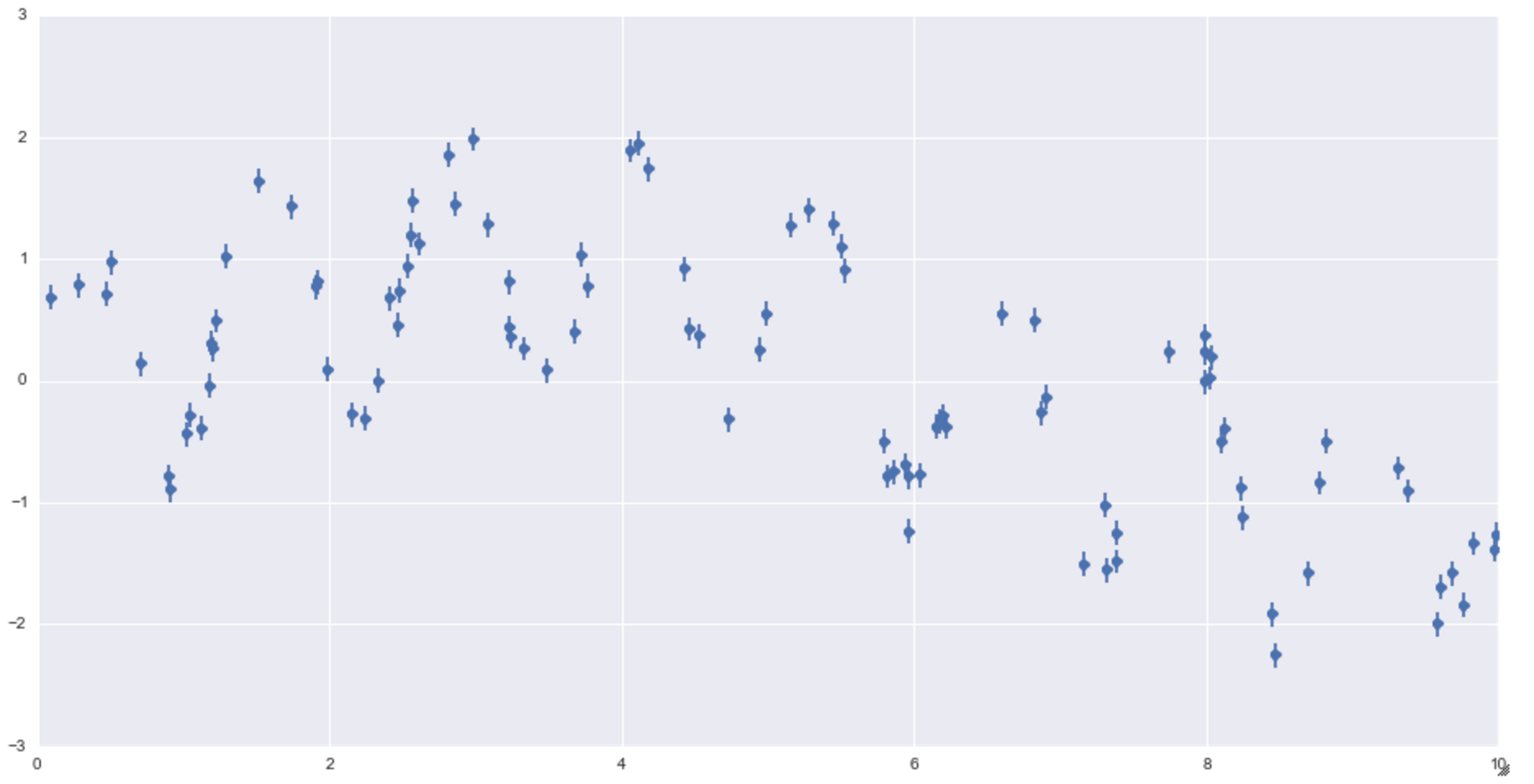
Wellenförmige Dummy-Daten. Es wird nach und nach kleiner.
Laufen Sie mit sklearn
{do_random_forest_regression.py}
from sklearn.ensemble import RandomForestRegressor #Für zufällige Waldregression
#Bereiten Sie 1000 Daten von 0 bis 10 zur Bestätigung vor
xfit = np.linspace(0, 10, 1000) #1000 Stück von 0 bis 10
#Zufällige Gesamtstrukturausführung
rfr = RandomForestRegressor(100) #Instanzgenerierung Geben Sie die Anzahl der Bäume auf 100 an
rfr.fit(x[:, None], y) #Ausführung lernen
yfit = rfr.predict(xfit[:, None]) #Vorausschauende Ausführung
#Holen Sie sich den tatsächlichen Wert für den Ergebnisvergleich.
ytrue = sin_model(xfit,0) #Führe xfit in die Wellenerzeugungsfunktion ein und erhalte das Ergebnis
#Überprüfen Sie das Ergebnis
plt.figure(figsize = (16,8))
plt.errorbar(x, y, 0.1, fmt='o')
plt.plot(xfit, yfit, '-r') #Voraussichtliche Handlung
plt.plot(xfit, ytrue, '-k', alpha = 0.5) #Richtige Antwortdarstellung
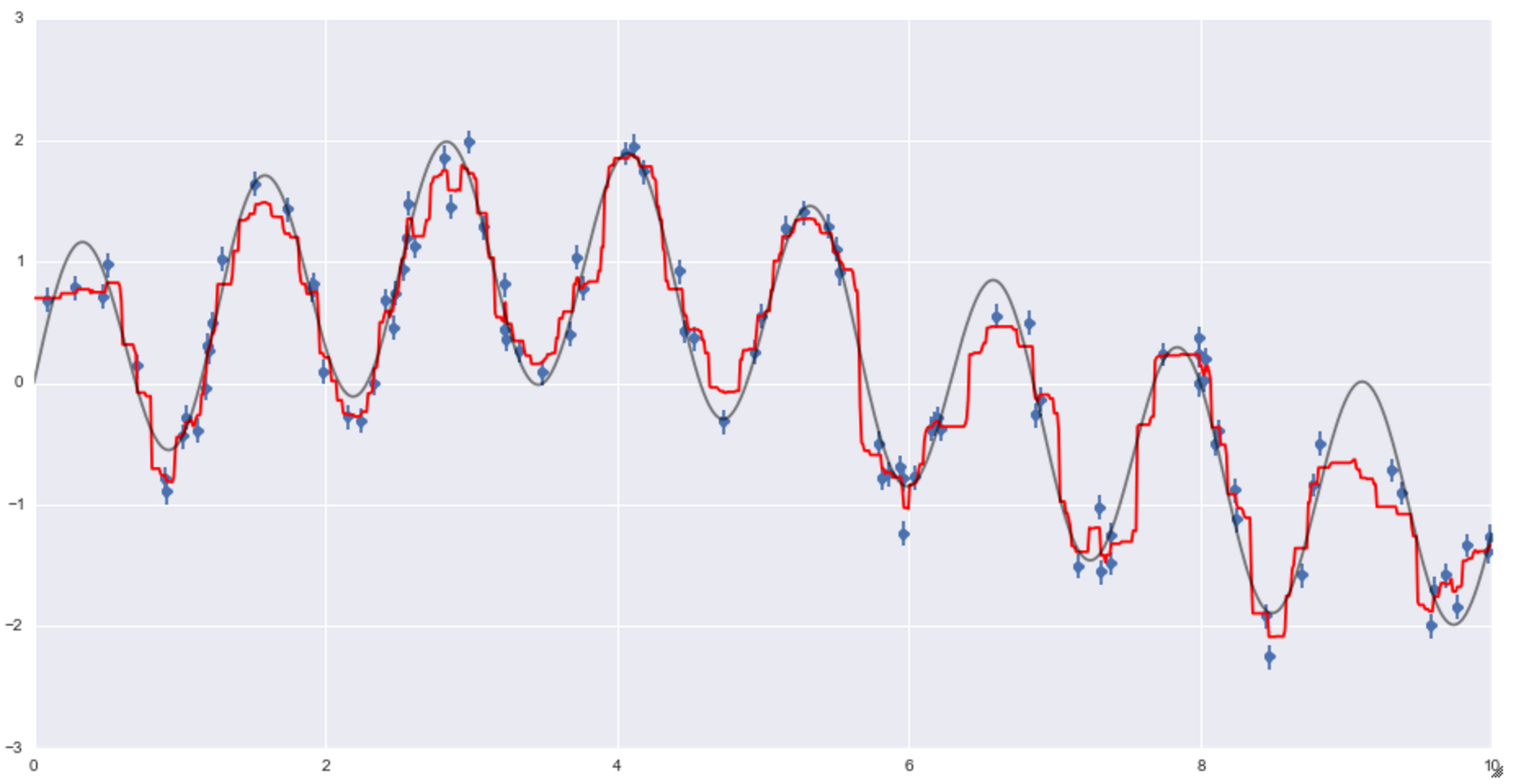
Sie können sehen, dass die rote Linie die Regressionslinie der Vorhersage ist und das Ergebnis einigermaßen gut zu sein scheint.
Recommended Posts