[PYTHON] Entscheidungsbaum (für Anfänger) -Code Edition-
Dieses Mal werden wir die Implementierung des Entscheidungsbaums (Klassifizierung) zusammenfassen.
■ Ablauf des Entscheidungsbaums
Fahren Sie mit den nächsten 7 Schritten fort.
- Vorbereitung des Moduls
- Datenaufbereitung
- Datenvisualisierung
- Erstellen Sie ein Modell
- Modellplot
- Klassifizierung vorhersagen
- Modellbewertung
1. Vorbereitung des Moduls
Importieren Sie zunächst die erforderlichen Module.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#Modul zum Lesen des Datensatzes
from sklearn.datasets import load_iris
#Modul zur Standardisierung (verteilte Normalisierung)
from sklearn.preprocessing import StandardScaler
#Modul, das Trainingsdaten und Testdaten trennt
from sklearn.model_selection import train_test_split
#Modul, das den Entscheidungsbaum ausführt
from sklearn.tree import DecisionTreeClassifier
#Modul zum Zeichnen des Entscheidungsbaums
from sklearn.tree import plot_tree
2. Datenaufbereitung
Dieses Mal werden wir den Iris-Datensatz verwenden, um drei Typen zu klassifizieren.
Holen Sie sich zuerst die Daten, standardisieren Sie sie und teilen Sie sie dann auf.
#Laden des Iris-Datensatzes
iris = load_iris()
#Teilen Sie in objektive Variable und erklärende Variable (Merkmalsbetrag)
X, y = iris.data[:, [0, 2]], iris.target
#Standardisierung (verteilte Normalisierung)
std = StandardScaler()
X = std.fit_transform(X)
#Teilen Sie in Trainingsdaten und Testdaten
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 123)
Um das Plotten zu vereinfachen, haben wir die Funktionen auf zwei eingegrenzt. (Sepal Länge / nur Blütenblattlänge)
Bei der Standardisierung beispielsweise wird der Einfluss der Merkmalsgrößen (erklärende Variablen) groß, wenn es zweistellige und vierstellige Merkmalsgrößen gibt. Die Skala wird ausgerichtet, indem der Durchschnitt für alle Merkmalsgrößen auf 0 und die Varianz auf 1 gesetzt wird.
In random_state ist der Startwert fest und das Ergebnis der Datenteilung wird jedes Mal gleich gesetzt.
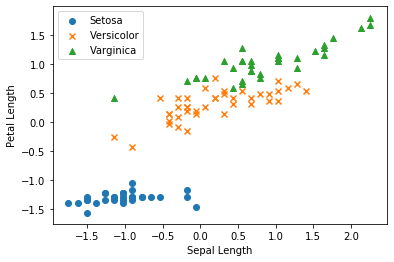
3. Datenvisualisierung
Zeichnen wir die Daten, bevor wir sie nach SVM klassifizieren.
#Erstellen von Zeichnungsobjekten und Nebenhandlungen
fig, ax = plt.subplots()
#Setosa Handlung
ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1],
marker = 'o', label = 'Setosa')
#Versicolor Handlung
ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1],
marker = 'x', label = 'Versicolor')
#Varginica Grundstück
ax.scatter(X_train[y_train == 2, 0], X_train[y_train == 2, 1],
marker = 'x', label = 'Varginica')
#Einstellungen für die Achsenbeschriftung
ax.set_xlabel('Sepal Length')
ax.set_ylabel('Petal Length')
#Legendeneinstellungen
ax.legend(loc = 'best')
plt.show()
Diagramm mit Merkmalen, die Setosa entsprechen (y_train == 0) (0: Sepal Länge auf der horizontalen Achse, 1: Blütenblattlänge auf der vertikalen Achse) Plot mit Merkmalen (0: Sepal Länge auf der horizontalen Achse, 1: Blütenblattlänge auf der vertikalen Achse) entsprechend Versicolor (y_train == 1) Diagramm mit Merkmalen (0: Sepal Länge auf der horizontalen Achse, 1: Blütenblattlänge auf der vertikalen Achse) entsprechend Varginica (y_train == 2)
Ausgabeergebnis
4. Erstellen Sie ein Modell
Erstellen Sie zunächst eine Ausführungsfunktion (Instanz) des Entscheidungsbaums und wenden Sie diese auf die Trainingsdaten an.
#Erstellen Sie eine Instanz
tree = DecisionTreeClassifier(max_depth = 3)
#Erstellen Sie ein Modell aus Trainingsdaten
tree.fit(X_train, y_train)
max_depth ist ein Hyperparameter
Sie können es selbst anpassen, während Sie sich die Ausgabewerte und Diagramme ansehen.
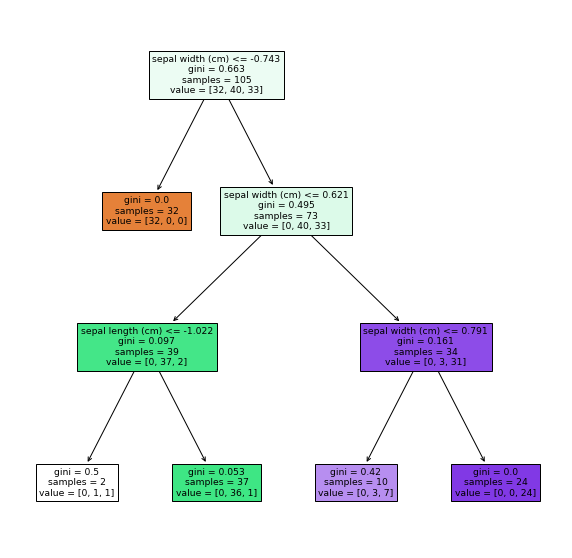
5. Modellplot
Da konnte ich aus den Trainingsdaten ein Modell des Entscheidungsbaums erstellen Zeichnen und überprüfen Sie, wie die Klassifizierung erfolgt.
#Stellen Sie die Größe des Diagramms ein
fig, ax = plt.subplots(figsize=(10, 10))
# plot_Verwenden Sie die Baummethode (Argumente: Instanz des Entscheidungsbaums, Liste der Funktionen)
plot_tree(tree, feature_names=iris.feature_names, filled=True)
plt.show()
In vielen Fällen wird es mit GraphViz geplottet, aber da es installiert und über den Pfad geleitet werden muss, Dieses Mal werden wir mit der Methode plot_tree zeichnen.
Ausgabeergebnis
6. Klassifizierung vorhersagen
Nachdem das Modell vollständig ist, lassen Sie uns die Klassifizierung vorhersagen.
#Klassifizierungsergebnisse vorhersagen
y_pred = tree.predict(X_test)
#Geben Sie den vorhergesagten Wert und den richtigen Antwortwert aus
print(y_pred)
print(y_test)
Ausgabeergebnis
y_pred: [2 2 2 1 0 1 1 0 0 1 2 0 1 2 2 2 0 0 1 0 0 2 0 2 0 0 0 2 2 0 2 2 0 0 1 1 2
0 0 1 1 0 2 2 2]
y_test: [1 2 2 1 0 2 1 0 0 1 2 0 1 2 2 2 0 0 1 0 0 2 0 2 0 0 0 2 2 0 2 2 0 0 1 1 2
0 0 1 1 0 2 2 2]
0:Setosa 1:Versicolor 2:Verginica
7. Modellbewertung
Da es diesmal drei Arten der Klassifizierung gibt, werden wir anhand der richtigen Antwortrate bewerten.
#Richtige Antwortrate ausgeben
print(tree.score(X_test, y_test))
Ausgabeergebnis
Accuracy: 0.9555555555555556
Aus dem oben Gesagten konnten wir die Klassifizierung in Setosa, Versicolor und Verginica bewerten.
■ Endlich
Im Entscheidungsbaum erstellen und bewerten wir das Modell basierend auf den obigen Schritten 1 bis 7.
Dieses Mal habe ich für Anfänger nur die Implementierung (Code) zusammengefasst. Mit Blick auf das Timing in der Zukunft möchte ich einen Artikel über Theorie (mathematische Formel) schreiben.
Danke fürs Lesen.
Referenzen: Neues Lehrbuch zur Datenanalyse mit Python (Hauptlehrmaterial für den Test zur Analyse der Zertifizierung von Python 3-Ingenieuren)
Recommended Posts