[PYTHON] Entscheidungsbaum (load_iris)
■ Einführung
Dieses Mal werden wir das Implementierungsdiagramm des Entscheidungsbaums zusammenfassen.
[Zielgruppe Leser]
・ Diejenigen, die den Basiscode im Entscheidungsbaum lernen möchten
・ Ich kenne die Theorie nicht im Detail, aber diejenigen, die die Implementierung sehen und ein Bild geben wollen usw.
1. Vorbereitung des Moduls
Importieren Sie zunächst die erforderlichen Module.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
## 2. Datenaufbereitung Verwenden Sie den Datensatz load_iris.
iris = load_iris()
X, y = iris.data[:, [0, 2]], iris.target
print(X.shape)
print(y.shape)
# (150, 2)
# (150,)
Teilen Sie in Zug- und Testdaten.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 123)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_train.shape)
# (105, 2)
# (105,)
# (45, 2)
# (45,)
Im Entscheidungsbaum werden einzelne Features unabhängig voneinander verarbeitet und die Datenteilung ist skalierungsunabhängig.
Es ist keine Normalisierung oder Standardisierung erforderlich.
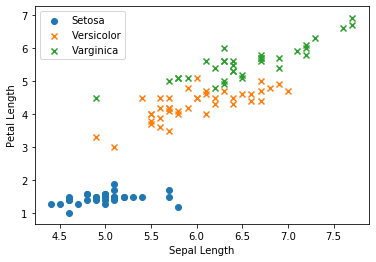
3. Datenvisualisierung
Zeichnen Sie vor dem Modellieren die Daten.
fig, ax = plt.subplots()
ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1],
marker = 'o', label = 'Setosa')
ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1],
marker = 'x', label = 'Versicolor')
ax.scatter(X_train[y_train == 2, 0], X_train[y_train == 2, 1],
marker = 'x', label = 'Varginica')
ax.set_xlabel('Sepal Length')
ax.set_ylabel('Petal Length')
ax.legend(loc = 'best')
plt.show()
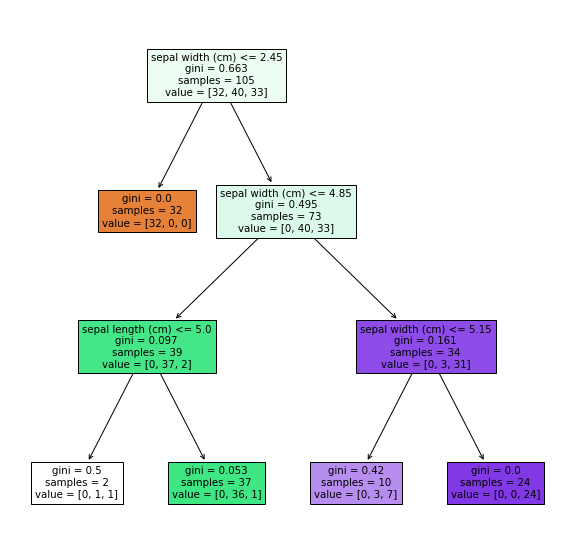
4. Erstellen Sie ein Modell
Erstellen Sie ein Modell des Entscheidungsbaums.
tree = DecisionTreeClassifier(max_depth = 3)
tree.fit(X_train, y_train)
'''
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',
max_depth=3, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
'''
Gleichzeitig werde ich es auch visualisieren.
fig, ax = plt.subplots(figsize=(10, 10))
plot_tree(tree, feature_names=iris.feature_names, filled=True)
plt.show()
5. Ausgabe des vorhergesagten Wertes
Machen Sie Vorhersagen für Testdaten.
y_pred = tree.predict(X_test)
print(y_pred[:10])
print(y_test[:10])
# [2 2 2 1 0 1 1 0 0 1]
# [1 2 2 1 0 2 1 0 0 1]
0:Setosa 1:Versicolor 2:Verginica
6. Leistungsbewertung
Finden Sie die richtige Antwortrate in dieser Klassifizierungsvorhersage.
print('{:.3f}'.format(tree.score(X_test, y_test)))
# 0.956
## ■ Endlich Dieses Mal haben wir basierend auf den obigen Schritten 1 bis 6 ein Modell des Entscheidungsbaums erstellt und ausgewertet. Wir hoffen, dass es Anfängern helfen wird.
## ■ Referenzen ・ [Neues Lehrbuch zur Datenanalyse mit Python](https://www.shoeisha.co.jp/book/detail/9784798158341)
Recommended Posts