[PYTHON] Ich habe Value Iteration Networks ausprobiert
Es ist der 12. Tag von Chainer Adventskalender 2016.
~~ Derzeit, am 11. um 18 Uhr, dauert es weitere 14 Stunden, bis wir die Implementierung abgeschlossen haben und mit dem Lernen in AWS \ (^ o ^) / ~~ beginnen
NEUER Code wurde veröffentlicht! (Hinweis: Ich habe verschiedene Dinge überarbeitet, es tut mir leid, wenn es nicht funktioniert. Ich plane, den Vorgang zu überprüfen, nachdem ich eine Lücke gesehen habe. Es tut mir leid, dass ich das Dokument nicht habe.) https://github.com/peisuke/vin
Über den Artikel
In diesem Artikel werde ich einen Kommentar zu dem Papier schreiben, das auf der NIPS 2016 (letzte Woche!) Mit dem Best Paper Award ausgezeichnet wurde. Dies ist eine Top-Konferenz für maschinelles Lernen und das Ergebnis der Implementierung in Chainer.
~~ Ich fing jedoch an, die Zeitung zu lesen, nachdem ich wusste, dass ich den Preis gewonnen hatte, also hatte ich einen Last-Minute-Zeitplan wie oben gezeigt und die experimentellen Ergebnisse sind noch nicht bekannt geworden ... Fügen Sie dem Papier also mehr Inhalt hinzu ... Auch wenn es etwas spät sein wird, werde ich die experimentellen Ergebnisse vielleicht definitiv veröffentlichen. ~~ Ich habe es geschafft, die experimentellen Ergebnisse zu veröffentlichen!
Hintergrund
Das in diesem Dokument behandelte Problem besteht darin, den Start und das Ziel auf der Karte festzulegen und den kürzesten Weg zu finden, wenn sich der Roboter in der Umgebung bewegt (siehe Abbildung unten). Natürlich gibt es solche Probleme schon lange, aber frühere Forschungen erfordern die Annahme, dass die Umgebung und die Robotermodelle bekannt sind. Tatsächlich ist es nicht möglich, das Modell des Roboters vollständig zu beschreiben, daher besteht das Ziel darin, durch Lernen dieses Bereichs nach einer Route ohne Modellierung suchen zu können.

Wenn der Roboter in der Umgebung arbeitet, muss die nächste Maßnahme unter Berücksichtigung zukünftiger Umweltveränderungen ergriffen werden. Die Wertiteration ist der Prozess des Addierens des Belohnungswerts des aktuellen Zustands (Erreichen des Zwecks, Annäherung an das Ziel usw.) und des Belohnungswerts des nächsten Zustands, der die Operation vorübergehend um einen Schritt vorangebracht hat. Indem Sie es wiederholen, können Sie herausfinden, wie gut der aktuelle Zustand des Roboters in der Zukunft ist und wie Sie sich als nächstes bewegen.
Es ist jedoch nicht einfach, den tatsächlichen Belohnungswert des aktuellen Status vorab zu berechnen. Dies liegt daran, dass Sie alle Schritte berechnen müssen, um das Ziel zu erreichen, da Sie endlich den Belohnungswert erhalten können. Dies kann erreicht werden, indem alle Änderungen in der Umgebung, in Robotermodellen usw. perfekt simuliert werden und ein großer Teil der Berechnungsverarbeitung ausgeführt wird. Es gibt jedoch nur sehr wenige Fälle, in denen dies möglich ist. Daher wird angenommen, dass die obigen Simulationen und eine große Anzahl von Berechnungen vermieden werden können, indem mithilfe von Deep Learning geeignete zukünftige Belohnungen für die Situation erlernt werden, und verschiedene Methoden wurden untersucht.
Eine der bekanntesten Methoden ist Deep Q-Network. Hierbei wird eine Methode namens Verstärkungslernen verwendet, bei der der Roboter Fehler bei der Ausführung seiner eigenen Bewegungen in der Umgebung macht und sich merkt, welche Maßnahmen in welcher Situation ergriffen werden sollten. Da Deep Q-Network jedoch Fehler bei der Implementierung einer bestimmten Umgebung macht, besteht das Problem, dass die Lernergebnisse nicht umgeleitet werden können, wenn sich die Umgebung ändert. Darüber hinaus kann es möglich sein, das Problem zu lösen, indem der Durchsetzungsfehler auf eine andere Umgebung übertragen wird. Es ist möglich, dass dies der Fall ist, aber es wurde in diesem Artikel berichtet, dass sich die Genauigkeit durch Experimente nicht verbessert hat. Als weiteres Mittel kann nun das Imitationslernen (Lernen durch Manet) erwähnt werden. Dies dient dazu, die zu ergreifenden Maßnahmen zu lernen, indem die Maßnahmen des Experten direkt nachgeahmt werden, ohne dass ein Fehler bei der Durchsetzung gemacht wird. Das Lernen wird einfacher, da Sie keine zusätzlichen Durchsetzungsfehler machen müssen. Auf der anderen Seite bleibt das Problem bestehen, dass es nicht gut auf Änderungen in der Umgebung angewendet werden kann.
Erstens ist es durchaus notwendig, die Umgebung ohne Informationen angemessen vorherzusagen, um die Bewegung basierend auf dem Lernen im Vorgriff auf die Zukunft unabhängig von der neuen Umgebung zu entscheiden, ohne manuell ein Modell des Roboters oder der Umgebung anzugeben. Es ist schwierig. Wenn so etwas getan werden kann, kann ein Roboter realisiert werden, der die Luft lesen und bedienen kann, ohne zu lernen und zu programmieren.
** Es scheint, dass es getan wurde. ** ** **
Deshalb. lesen. Aviv Tamar, Yi Wu, Garrett Thomas, Sergey Levine, and Pieter Abbeel, "Value Iteration Networks", NIPS 2016. Und der Autor ist auch ein solches Gesicht, S. Levine und P. Abbeel
Informationen zu Value Iteration Networks
Es tut mir leid, die Einführung ist länger geworden. Diese Forschung war enttäuschend, weil ich es auch versucht habe und gescheitert bin. Übrigens besteht das Wertiterationsnetzwerk einfach darin, (1) die Belohnung aus dem Eingabestatus durch CNN zu schätzen, (2) die Belohnung gemäß der von ihm ergriffenen Maßnahme an das CNN mit Gewichtsverteilung weiterzugeben und (3) zu schätzen. Die Struktur ist so, dass nur die Belohnung an der interessierenden Position herausgeschnitten wird und (4) die Operation durch vollständige Kopplung bestimmt wird. Die Formel ist schwer zu schreiben, deshalb werde ich sie weglassen.

In der obigen Abbildung im Papier multipliziert die Beobachtung $ \ phi (s) $ das Eingabebild mit CNN und fügt dies in die geschätzte Belohnung $ \ bar {R} $ ein. Außerdem ist $ \ bar {P} $ eine Konvertierung der Änderung des Status, wenn die Aktion $ a $ an den Status $ s $ übergeben wird. In diesem Problem wird die Statusänderung jedoch wie bekannt ignoriert. .. Das VI-Modul berechnet, wie viel Belohnung Sie sammeln, wenn Sie von einer bestimmten geschätzten Belohnungskarte wechseln, die später beschrieben wird. Die "Achtung" im nächsten Bild ist der Ausschnitt, auf dessen Seite des Bildes fokussiert werden soll. Beim normalen Deep Learning wird es häufig vom gesamten Bildschirm mit der FC-Ebene verbunden, dies ist jedoch schwierig, da die Parameter zunehmen. Wenn Sie jedoch wissen, auf welcher Seite des Bildschirms die gewünschten Informationen angezeigt werden, können Sie diese leicht berechnen, indem Sie nur auf diesen Bereich abzielen. In diesem Fall werden die Belohnungsinformationen zum Bestimmen der nächsten Bewegungsrichtung zur eigenen Position des Roboters hinzugefügt, sodass die Position $ s $ des Roboters als Ziel ausgewählt wird. Schließlich wird die FC-Schicht verwendet, um die Belohnungsinformationen mit den Verhaltensinformationen zu verbinden. Als Ergebnis wissen Sie, welche Aktion Sie ausführen müssen (rechts, links, oben, unten usw.). Die Softmax-Kreuzentropie vergleicht sie also mit der tatsächlichen Fahrtrichtung und berechnet die inverse Fehlerausbreitung.
Das VI-Modul sieht nun folgendermaßen aus:

Zunächst wird die Belohnung $ \ bar {R} $ als Eingabe für die Berechnung von $ \ bar {Q} $ zusammengefasst. $ \ bar {Q} $ berechnet, wie viel der Roboter für die Bewegung $ a $ belohnt wird, wenn die Bewegung $ a $ ausgewählt wird, einschließlich der aktuellen Belohnung. Wenn Sie den MAX Kanal für Kanal nehmen, erhalten Sie schließlich die Belohnung $ \ bar {V} $ für das beste Verhalten. Durch erneutes Berechnen des VI-Moduls basierend auf dieser Belohnung kann die Belohnung nacheinander weitergegeben werden.
Implementierung
Nachdem wir das Ganze behandelt haben, fahren wir mit der Implementierung fort. Dieses Dokument besteht aus separaten Programmen zur Datenaufbereitung, zum Lernen und zur Ergebnisanzeige. Hier werden nur die Lern- und Vorhersage-Teile beschrieben. ~~ Ich werde es bald auf Github hochladen. ~~ Hochgeladen.
Zunächst zur Netzwerkinitialisierung.
class VIN(chainer.Chain):
def __init__(self, k = 10, l_h=150, l_q=10, l_a=8):
super(VIN, self).__init__(
conv1=L.Convolution2D(2, l_h, 3, stride=1, pad=1),
conv2=L.Convolution2D(l_h, 1, 1, stride=1, pad=0, nobias=True),
conv3=L.Convolution2D(1, l_q, 3, stride=1, pad=1, nobias=True),
conv3b=L.Convolution2D(1, l_q, 3, stride=1, pad=1, nobias=True),
l3=L.Linear(l_q, l_a, nobias=True),
)
self.k = k
self.train = True
conv1 und conv2 sind die Umrechnungsgewichte von Kartendaten zu geschätzter Belohnung. Die Eingabe ist zweidimensional, das Bild, das das Hindernis auf der Karte beschreibt, wird Kanal 1 zugewiesen, und das Bild, das die Zielposition beschreibt, wird Kanal 2 zugewiesen. Die Ausgabe ist der Belohnungswert an jeder Position auf der Karte und eindimensional. conv3 ist das Gewicht zum Konvertieren vom Belohnungswert und conv3b ist das Gewicht zum Konvertieren des vom VI propagierten Belohnungswerts in den vorhergesagten Belohnungswert, der der Position x Bewegung entspricht. l3 ist das Gewicht, das durch Aufmerksamkeit erhalten wird, um den zukünftig vorhergesagten Belohnungswert an der Roboterposition in die endgültige Bewegung umzuwandeln. Als nächstes wird das Netzwerk unten aufgeführt.
def __call__(self, x, s1, s2):
h = self.relu(self.conv1(x))
r = self.conv2(h)
q = self.conv3(r)
v = F.max(q, axis=1, keepdims=True)
for i in xrange(self.k - 1):
q = self.conv3(r) + self.conv3b(v)
v = F.max(q, axis=1, keepdims=True)
q = self.conv3(r) + self.conv3b(v)
t = s2 * q.data.shape[3] + s1
q = F.reshape(q, (q.data.shape[0], q.data.shape[1], -1))
q = F.rollaxis(q, 2, 1)
t_data_cpu = chainer.cuda.to_cpu(t.data)
w = np.zeros(q.data.shape, dtype=np.float32)
w[six.moves.range(t_data_cpu.size), t_data_cpu] = 1.0
if isinstance(q.data, chainer.cuda.ndarray):
w = chainer.cuda.to_gpu(w)
w = chainer.Variable(w, volatile=not self.train)
q_out = F.sum(w * q, axis=1)
return self.l3(q_out)
Wenn Sie alles auf einmal schreiben, wird es schwierig sein, es nachzuholen, daher werde ich es erneut veröffentlichen, während ich es in Folgendes aufteile. Konvertieren Sie zunächst das Eingabebild in einen Belohnungswert. Dies ist eine normale CNN.
h = self.relu(self.conv1(x))
r = self.conv2(h)
Als nächstes kommt das VI-Modul. Indem Sie $ \ bar {Q} $ durch die Faltungsschicht conv3 finden und MAX für den Bewegungskanal (Achse = 1) nehmen, wird an jeder Position in der Karte die beste Bewegung ausgewählt. Der Belohnungswert zu diesem Zeitpunkt ist v. Im for-Satz werden der direkt aus der Karte geschätzte Belohnungswert und der propagierte Belohnungswert addiert und dieselbe Berechnung wie beim ersten durchgeführt.
q = self.conv3(r)
v = F.max(q, axis=1, keepdims=True)
for i in xrange(self.k - 1):
q = self.conv3(r) + self.conv3b(v)
v = F.max(q, axis=1, keepdims=True)
Der Achtungsteil, der die Anzahl der Parameter reduziert, indem nur der Teil in der Nähe Ihrer Position aus der erhaltenen Belohnungskarte verwendet wird, lautet wie folgt. Fügen Sie zunächst r und v hinzu, indem Sie $ \ hat {Q} $ verwenden, wodurch der Belohnungswert für jede Aktion als Belohnungskarte ausgegeben wird. Rufen Sie dann für jedes Datenelement im Stapel die Nummer auf der Karte ab, die Ihrem Standort entspricht. Es ist ein wenig knifflig, weil Sie mit Chainer keine Fancy Index-ähnlichen Dinge tun können, sondern eine Matrix w mit 1 an der Position, die Sie abrufen möchten, und 0 an anderen Stellen vorbereiten und unnötige Elemente löschen, indem Sie das Produkt für jedes Element nehmen. Der vorgeschriebene Belohnungswert wird durch Schrumpfen erhalten.
q = self.conv3(r) + self.conv3b(v)
t = s2 * q.data.shape[3] + s1
q = F.reshape(q, (q.data.shape[0], q.data.shape[1], -1))
q = F.rollaxis(q, 2, 1)
t_data_cpu = chainer.cuda.to_cpu(t.data)
w = np.zeros(q.data.shape, dtype=np.float32)
w[six.moves.range(t_data_cpu.size), t_data_cpu] = 1.0
if isinstance(q.data, chainer.cuda.ndarray):
w = chainer.cuda.to_gpu(w)
w = chainer.Variable(w, volatile=not self.train)
q_out = F.sum(w * q, axis=1)
Schließlich wird die Belohnung in eine Aktion und Ausgabe umgewandelt.
return self.l3(q_out)
Als nächstes die Datensatzklasse (dieser Code entspricht Chainer 1.10 oder höher)
class MapData(chainer.dataset.DatasetMixin):
def __init__(self, im, value, state, label):
self.im = np.concatenate(
(np.expand_dims(im, 1), np.expand_dims(value,1)),
axis=1).astype(dtype=np.float32)
self.s1, self.s2 = np.split(state, [1], axis=1)
self.s1 = np.reshape(self.s1, self.s1.shape[0])
self.s2 = np.reshape(self.s2, self.s2.shape[0])
self.t = label
def __len__(self):
return len(self.im)
def get_example(self, i):
return self.im[i], self.s1[i], self.s2[i], self.t[i]
Der Rest ist fast der gleiche wie bei der CIFAR-10-Probe. Ich werde es bald auf github hochladen, einschließlich Datengenerierung. ~~ Hochgeladen.
Versuchsergebnis
Jetzt ist es ein Experiment. Das Experiment wurde mit den gleichen Parametern wie in diesem Artikel versucht. Die Anzahl der Daten beträgt 5000 für jeden Kartentyp, 7 Starttypen werden zufällig für die Karte festgelegt und nur 1 Zieltyp ist für die Karte. Die Anzahl der Ziele ist gering, da anscheinend viel Rechenzeit erforderlich war, um die richtigen Antwortdaten zu berechnen. Von den 5000 Typen wurde 1/5 als Testdaten für Experimente verwendet. Das Experiment wird mit AWS durchgeführt und dauert in 30 Epochen etwa mehrere Stunden. Ich habe nicht verstanden, warum es am Anfang des Satzes als 14 Stunden angezeigt wurde, aber wenn ich cudnn separat hinzufügte, konnte es in wenigen Stunden ausgeführt werden.
Zunächst wird Testfall 1 gezeigt. Die Wand ist schwarz und der Bewegungsbereich ist weiß. Der blaue Punkt unten ist der Anfang und der hellblaue Punkt oben ist das Ziel. Die erkannte Route wird gelb angezeigt. Selbst wenn es einen Block gibt, der ihn auf dem Weg blockiert, können Sie sehen, dass er richtig umleitet und das Ziel erreicht.

Das Folgende ist die geschätzte Belohnungskarte. Sie können sehen, dass die Belohnung für den Wandbereich gesunken ist. Auf der anderen Seite scheint die Belohnung selbst in einem großen Bereich in dem von der Wand entfernten Bereich höher zu sein.
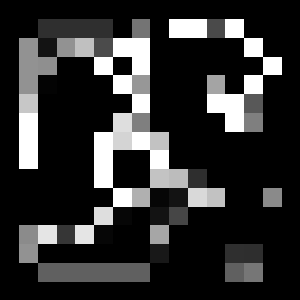
Schließlich gibt es ein Diagramm der zukünftigen Belohnungen, die vom VI-Modul ausgegeben werden. Sie können sehen, dass die Belohnung in der Nähe des Ziels hoch ist. Wenn Sie eine Route auswählen, können Sie das Ziel erreichen, indem Sie zur höheren Belohnung gehen.

Als nächstes folgt Testfall 2. Es ändert sich nicht viel, deshalb erkläre ich es kurz. Dies ist ein Kurs, der etwas größer umgeleitet werden muss, aber es scheint, dass die Route richtig erkannt werden kann.

Es scheint, dass Sie sowohl die Belohnungskarte als auch die zukünftige Belohnungskarte richtig erkennen können.


Zusammenfassung
Ich wollte ein bisschen quantitativer experimentieren, aber mir ist die Zeit ausgegangen, also bin ich vorerst damit fertig. Was den Eindruck betrifft, ist es ein Wort, dass VIN wirklich erstaunlich ist. Obwohl es die erste Karte ist, die ich sehe, kann die Route richtig geschätzt werden! Ich kann nicht sagen, wie groß das Problem an dieser Stelle skaliert werden kann, aber ich fand es eine sehr interessante Technik. Ich bin auch froh, dass es mit einem Schuss gut gelaufen ist.
Der Chainer ist immer noch einfach zu bedienen! Um Sonderfälle zu behandeln, möchte ich Sie jedoch bitten, den Fancy Index etwas weiter zu erweitern oder automatisch zu differenzieren.
Die übrigen Fragen sind übrigens die folgenden zwei Punkte.
- Obwohl die Trainingsdaten nur der kürzeste Weg sind, war es möglich, sogar die Belohnungen von nicht gelernten Bereichen wie Wänden zu lernen.
- Da es an die Wertiteration angepasst wurde, war es möglich zu lernen, obwohl VIM keine nichtlineare Aktivierungsfunktion enthielt. Ich denke, dass dies unverzichtbare Bedingungen für normales Deep Learning sind, aber aus irgendeinem Grund war es sehr seltsam, dass es funktioniert hat.
Übrigens scheint die Version, die der Autor basierend auf Theano implementiert, auch auf Github zu sein.
Recommended Posts