[PYTHON] Ich habe die Bildklassifizierung von AutoGluon ausprobiert
Einführung
Ich habe die Bildklassifizierung von AutoGluon (https://autogluon.mxnet.io/index.html) ausprobiert, einer AutoML-Bibliothek in der Umgebung von Google Colaboratory. Grundsätzlich ist der Inhalt ein Pluspunkt zum Inhalt des offiziellen Schnellstarts.
Umgebung
Es wird im Google Colaboratory durchgeführt.
Lauf
Google Colab-Einstellungen
Für die Bildklassifizierung wird das Deep Learning-Modell verwendet. Stellen Sie daher die Verwendung der GPU ein (siehe Abbildung unten).
Bibliotheksinstallation mit Google Colab
Wenn ich AutoGluon nur mit den oben genannten Einstellungen ausführe, wird eine Fehlermeldung angezeigt, wenn keine GPU vorhanden ist. Daher habe ich es unter Bezugnahme auf diesen Artikel installiert (https://qiita.com/tasmas/items/22cf80a4be80f7ad458e). Es gab keine besonderen Fehler und ich konnte es gut machen.
!pip uninstall -y mkl
!pip install --upgrade mxnet-cu100
!pip install autogluon
!pip install -U ipykernel
Starten Sie die Laufzeit nach der Ausführung neu.
Führen Sie Auto Gluon aus
Folgen Sie dem offiziellen Schnellstart. https://autogluon.mxnet.io/tutorials/image_classification/beginner.html
Importieren Sie zunächst die Bibliothek und laden Sie die Daten herunter. Die Daten sind die Bilddaten von Shopee-IET in Kaggle, und die Bilder wie Kleidung werden in vier Kategorien eingeteilt: "Babyhose", "Babyhemd", "Damen-Freizeitschuhe" und "Frauen-Chiff oben". Der Link zu Kaggle auf der Auto Gluon-Seite wurde jedoch unterbrochen. (Kaggle hat auch eine Seite, aber ich konnte die Daten nicht sofort finden. Sie wurden möglicherweise gelöscht, weil es sich um die Daten eines alten Wettbewerbs handelt.)
import autogluon as ag
from autogluon import ImageClassification as task
filename = ag.download('https://autogluon.s3.amazonaws.com/datasets/shopee-iet.zip')
ag.unzip(filename)
Laden Sie die Trainingsdaten bzw. die Bewertungsdaten.
train_dataset = task.Dataset('data/train')
test_dataset = task.Dataset('data/test', train=False)
Passen Sie einfach die Trainingsdaten an, um ein Modell für die Bildidentifikation zu erstellen. Wahnsinnig einfach ...
classifier = task.fit(train_dataset,
epochs=5,
ngpus_per_trial=1,
verbose=False)
Das Folgende ist das Standardausgabeergebnis zum Zeitpunkt der Anpassung. Anscheinend bringe ich ResNet 50. Schließlich gibt es Ihnen auch eine Lernkurve. Dieses Mal lernte ich nur 5 Epochen, also dauerte es nur ein paar Minuten.
scheduler_options: Key 'training_history_callback_delta_secs': Imputing default value 60
scheduler_options: Key 'delay_get_config': Imputing default value True
Starting Experiments
Num of Finished Tasks is 0
Num of Pending Tasks is 2
scheduler: FIFOScheduler(
DistributedResourceManager{
(Remote: Remote REMOTE_ID: 0,
<Remote: 'inproc://172.28.0.2/371/1' processes=1 threads=2, memory=13.65 GB>, Resource: NodeResourceManager(2 CPUs, 1 GPUs))
})
100%
2/2 [03:58<00:00, 119.19s/it]
Model file not found. Downloading.
Downloading /root/.mxnet/models/resnet50_v1b-0ecdba34.zip from https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/models/resnet50_v1b-0ecdba34.zip...
100%|██████████| 55344/55344 [00:01<00:00, 45529.30KB/s]
[Epoch 5] Validation: 0.456: 100%
5/5 [01:06<00:00, 13.29s/it]
Saving Training Curve in checkpoint/plot_training_curves.png
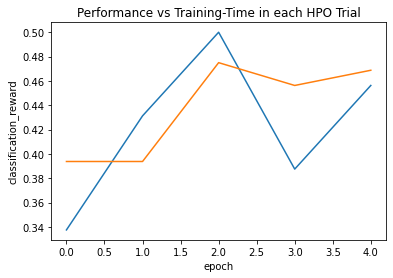
Die Genauigkeit zum Zeitpunkt des Lernens betrug etwa 50%. Ich denke, es kann nicht mit den aktuellen Einstellungen geholfen werden.
print('Top-1 val acc: %.3f' % classifier.results['best_reward'])
# Top-1 val acc: 0.469
Lassen Sie uns eine Vorhersage für bestimmte Bilddaten machen. Wenn Sie die Daten von "Baby Shirt" vorhersagen, wird es sicherlich als "Baby Shirt" klassifiziert.
image = 'data/test/BabyShirt/BabyShirt_323.jpg'
ind, prob, _ = classifier.predict(image, plot=True)
print('The input picture is classified as [%s], with probability %.2f.' %
(train_dataset.init().classes[ind.asscalar()], prob.asscalar()))
# The input picture is classified as [BabyShirt], with probability 0.61.
Bei der Berechnung der Genauigkeit anhand der Bewertungsdaten lag sie bei etwa 70%.
test_acc = classifier.evaluate(test_dataset)
print('Top-1 test acc: %.3f' % test_acc)
# Top-1 test acc: 0.703
Dies ist sehr praktisch, da Sie ein Modell in einem Augenblick wie diesem erstellen können Ich hatte das Gefühl, dass die Fit-Funktion wirklich wichtig ist, also habe ich einige Nachforschungen angestellt.
Ein wenig über Passform recherchieren
Argumente der Anpassungsfunktion
Dieses Mal habe ich die Anpassungsfunktion bei der Bildidentifikation verwendet. Der Quellcode (https://github.com/awslabs/autogluon/blob/15c105b0f1d8bdbebc86bd7e7a3a1b71e83e82b9/autogluon/task/image_classification/image_classification.py#L63) ist unten aufgeführt.
@staticmethod
def fit(dataset,
net=Categorical('ResNet50_v1b', 'ResNet18_v1b'),
optimizer=NAG(
learning_rate=Real(1e-3, 1e-2, log=True),
wd=Real(1e-4, 1e-3, log=True),
multi_precision=False
),
loss=SoftmaxCrossEntropyLoss(),
split_ratio=0.8,
batch_size=64,
input_size=224,
epochs=20,
final_fit_epochs=None,
ensemble=1,
metric='accuracy',
nthreads_per_trial=60,
ngpus_per_trial=1,
hybridize=True,
scheduler_options=None,
search_strategy='random',
search_options=None,
plot_results=False,
verbose=False,
num_trials=None,
time_limits=None,
resume=False,
output_directory='checkpoint/',
visualizer='none',
dist_ip_addrs=None,
auto_search=True,
lr_config=Dict(
lr_mode='cosine',
lr_decay=0.1,
lr_decay_period=0,
lr_decay_epoch='40,80',
warmup_lr=0.0,
warmup_epochs=0
),
tricks=Dict(
last_gamma=False,
use_pretrained=True,
use_se=False,
mixup=False,
mixup_alpha=0.2,
mixup_off_epoch=0,
label_smoothing=False,
no_wd=False,
teacher_name=None,
temperature=20.0,
hard_weight=0.5,
batch_norm=False,
use_gn=False),
**kwargs):
Weil ResNet50 standardmäßig in `` `net``` aufgerufen wurde, was eines der Argumente ist Sie können sehen, dass es früher aufgerufen wurde. Wenn Sie dann andere Modelle ausprobieren möchten, stellt sich die Frage, welches Modell Sie auswählen können.
Über das aufzurufende Modell
Wie auf der offiziellen Seite (https://autogluon.mxnet.io/tutorials/image_classification/hpo.html) beschrieben, glooncv model_zoo (https://gluon-cv.mxnet.io/model_zoo/classification.html) ) Scheint in der Lage zu sein, das Modell abzurufen. Die ab dem 4. September 2020 registrierten Modelle sind in der folgenden Abbildung dargestellt.
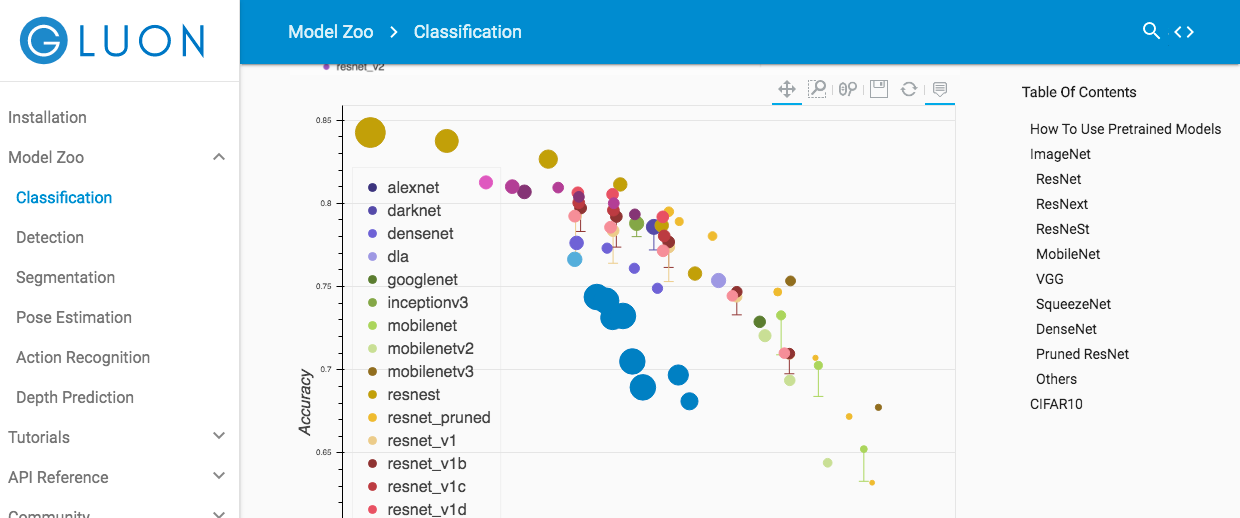
Zusätzlich zu dem oben erwähnten ResNet haben wir festgestellt, dass es einige trainierte Modelle wie MobileNet und VGG gibt. Die Modelle werden bereits in der Reihenfolge ihrer Genauigkeit angezeigt, daher ist die Auswahl meiner Meinung nach einfach.
Über mein eigenes Modell
Wenn Sie andererseits Ihr eigenes neuronales Netzwerk aufbauen möchten, können Sie es anscheinend mit `` `mxnet``` erstellen, das in der Basis von AutoGluon verwendet wird.
https://github.com/awslabs/autogluon/blob/15c105b0f1d8bdbebc86bd7e7a3a1b71e83e82b9/autogluon/task/image_classification/nets.py#L52
def mnist_net():
mnist_net = gluon.nn.Sequential()
mnist_net.add(ResUnit(1, 8, hidden_channels=8, kernel=3, stride=2))
mnist_net.add(ResUnit(8, 8, hidden_channels=8, kernel=5, stride=2))
mnist_net.add(ResUnit(8, 16, hidden_channels=8, kernel=3, stride=2))
mnist_net.add(nn.GlobalAvgPool2D())
mnist_net.add(nn.Flatten())
mnist_net.add(nn.Activation('relu'))
mnist_net.add(nn.Dense(10, in_units=16))
return mnist_net
Außerdem können Sie auch "Metrik" und "Optimierer" einstellen, sodass ich dachte, es wäre einfach, Deep Learning durchzuführen.
schließlich
Bei der Bildanalyse gab es ein Bild der Gebäudeberechnungslogik unter Verwendung von Tensorflow, Keras usw., aber wenn es möglich wird, ein Modell so einfach zu erstellen, wird es auf die Bilddatenverarbeitung angewendet (Rauschentfernung, Vergrößerung usw.). Ich dachte, es wäre sehr gut, weil die Zeit, die ich verbringen könnte, relativ zunehmen würde.
Da AutoGluon auf mxnet basiert, einer Bibliothek (oder Plattform) für Deep Learning, war ich überzeugt, dass AutoGluon auch die Verarbeitung natürlicher Sprache (NLP) unterstützt. Vielmehr scheint Auto Gluon-Tabular ein Plus-Alpha-Element zu sein.
Da AWS sowohl AutoGluon als auch mxnet unterstützt, möchte ich dies beenden und mich fragen, ob die Bibliotheken in diesem Bereich für AWS ML-Services verwendet werden.
Recommended Posts