[PYTHON] Utilisez PyCaret pour prédire le prix des appartements d'occasion à Tokyo!
§ Qu'est-ce que PyCaret? </ strong>
Je voudrais présenter les étapes pour prédire le prix d'un condominium d'occasion en créant un modèle de prédiction à l'aide de PyCaret , qui est maintenant un sujet brûlant sur Twitter, etc. pense.
PyCaret vous permet d'effectuer une série d'étapes d'apprentissage automatique telles que la création d'un modèle prédictif, le réglage et la réalisation de prédictions avec un minimum de code Python. Ce sera.
Dans cet article, qu'est-ce que l'apprentissage automatique via Pycaret pour ceux qui sont sur le point de commencer l'apprentissage automatique? Je voudrais continuer tout en présentant cela. Veuillez noter qu'il peut y avoir des expressions qui diffèrent de la définition stricte, car nous mettons l'accent sur la compréhension sensuelle.
Désormais, avec ce PyCaret , vous pouvez exécuter divers processus nécessaires pour créer un modèle prédictif pour l'apprentissage automatique avec un code simple. C'est un excellent produit qui vous donne et combien il est pratique de l'utiliser! J'ai été surpris par. Et c'est gratuit </ strong>!
Mais cependant. Si vous ne comprenez pas la difficulté du processus d'apprentissage automatique en premier lieu, vous ne l'apprécierez peut-être pas.
§ Qu'est-ce que l'apprentissage automatique supervisé? </ strong>
Créer un modèle prédictif et améliorer sa précision est une tâche très difficile.
Tout d'abord, je voudrais passer en revue le travail nécessaire pour "l'apprentissage automatique supervisé" </ strong>.
Dans l'apprentissage automatique supervisé, une règle (modèle) est dérivée sur la base de données passées pour lesquelles le résultat (réponse) est connu, et le résultat à connaître est prédit en l'appliquant à la règle.
Par exemple, si vous avez un ensemble de conditions de propriété et de prix pour un condominium d'occasion dans le passé, vous pouvez prédire le prix si vous connaissez les conditions telles que l'emplacement de la gare la plus proche, le nombre de mètres carrés et le nombre d'années de construction. Laissez la machine faire cette règle en utilisant divers algorithmes. Il s'agit de l'apprentissage automatique.
Les étapes de l'apprentissage automatique supervisé sont grossièrement divisées comme suit.
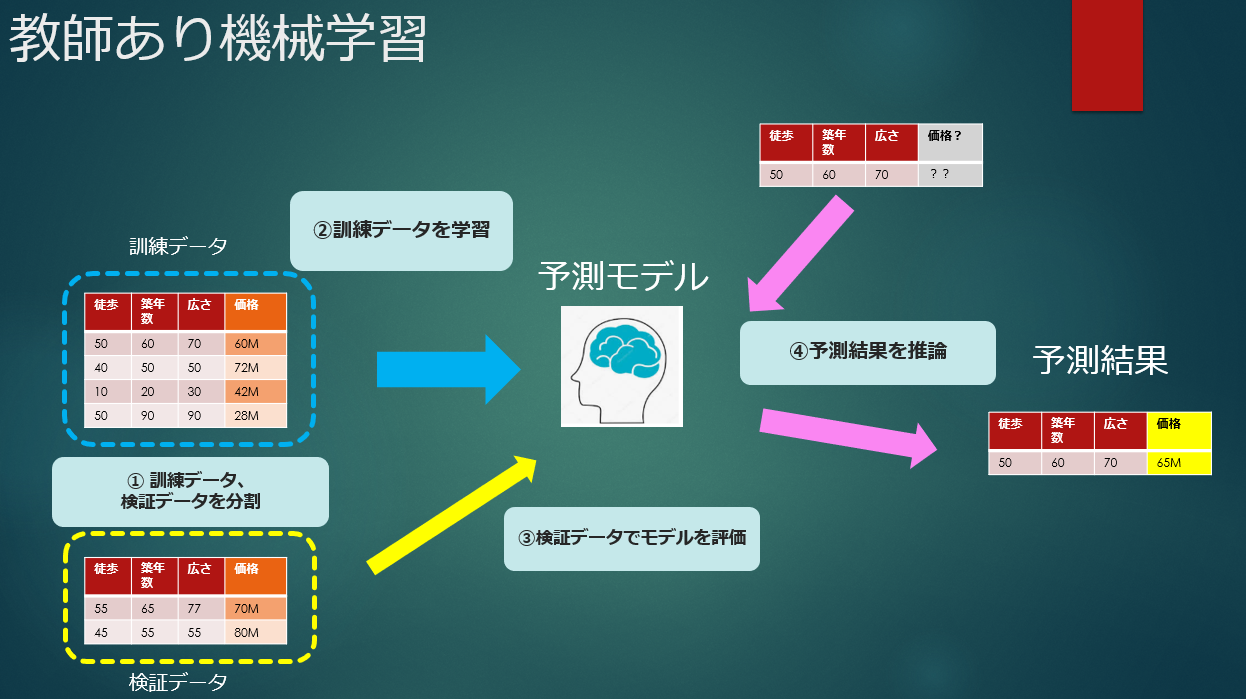
① Divisez les données en données d'entraînement et données de vérification </ b>
Divisez les données en données d'apprentissage et de validation pour valider le modèle avec des données qui ne sont pas utilisées pour entraîner le modèle. Si vous l'évaluez avec des données d'entraînement, c'est comme de la mise en conserve. Normalement, afin d'utiliser des données d'apprentissage et des données qui vérifient l'exactitude du modèle de manière uniforme et équitable, une division est effectuée et une alternance (validation croisée) est effectuée.
② Création du modèle (apprentissage) et réglage des hyper paramètres </ b>
Décidez de l'algorithme à utiliser pour la prédiction, apprenez à utiliser les données d'entraînement, créez un modèle et ajustez pour améliorer la précision.
③ Évaluation du modèle </ b>
Évaluez la précision du modèle créé par la formation et évaluez le niveau d'erreur qu'il contient et s'il est utilisable.
④ Prédiction de valeur inconnue </ b>
Lorsque l'évaluation est terminée, saisissez les données avec des résultats inconnus dans le modèle de prédiction pour obtenir les résultats de prédiction. Je ne connais que les conditions de l'appartement, mais je ne connais pas le prix, donc l'image est de le prédire.
§ Essayez en fait d'utiliser PyCaret.
Maintenant, exécutons ce flux en utilisant Pycart.
Tout d'abord, installons pycaret avec pip.
Cette fois, j'utilise pip d'Anaconda Powershell.
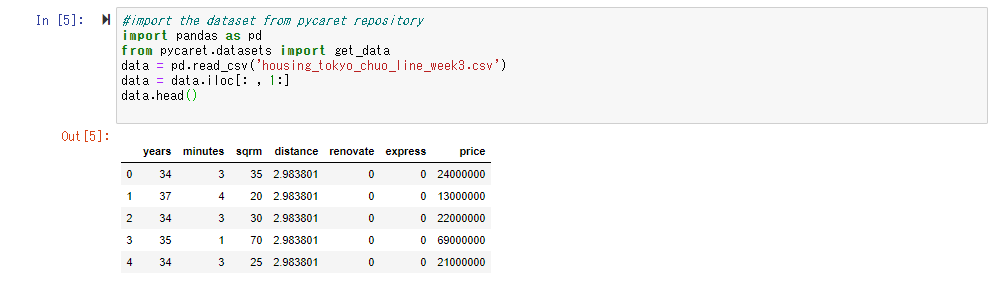
Tout d'abord, lisons les données. Cette fois également, le prix de l'appartement d'occasion le long de la ligne Tokyo / Chuo utilisé dans "Data Science Learning School Starting with Tableau" Utilisez les données comme données de l'enseignant. Les données elles-mêmes ont le contenu suivant.
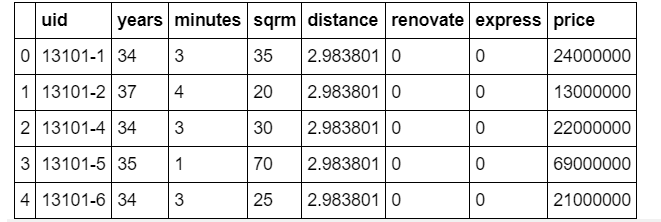
L'explication de chaque élément est la suivante.
| Nom de l'élément | Description | type de données |
| uid | ID unique de la propriété | Type de chaîne |
| years | Âge | type entier |
| minutes | Distance à pied (minutes) de la gare la plus proche | type entier |
| sqrm | Nombre de mètres carrés de propriété | type entier |
| distance | Distance directe entre la gare de Tokyo et la gare la plus proche (à quelle distance du centre-ville?) | virgule flottante |
| renovate | Indicateur remis à neuf ou non | Type entier (0 ou 1) |
| express | Drapeau pour voir si l'express s'arrête | Type entier (0 ou 1) |
| price | Prix de transaction (variable objectif) | Type entier (unité: 1 yen) |
Appelez Pycaret avec l'importation. Cette fois, c'est un modèle de régression qui devine le prix, alors importez depuis pycaret.regression.
Si vous définissez la variable objectif (variable que vous souhaitez prédire) sur le prix de l'appartement "prix" et exécutez la fonction Setup (), elle déterminera automatiquement si chaque champ est une chaîne numérique ou une colonne de catégorie, et s'il n'y a pas de différence, Exécutez la clé de retour.
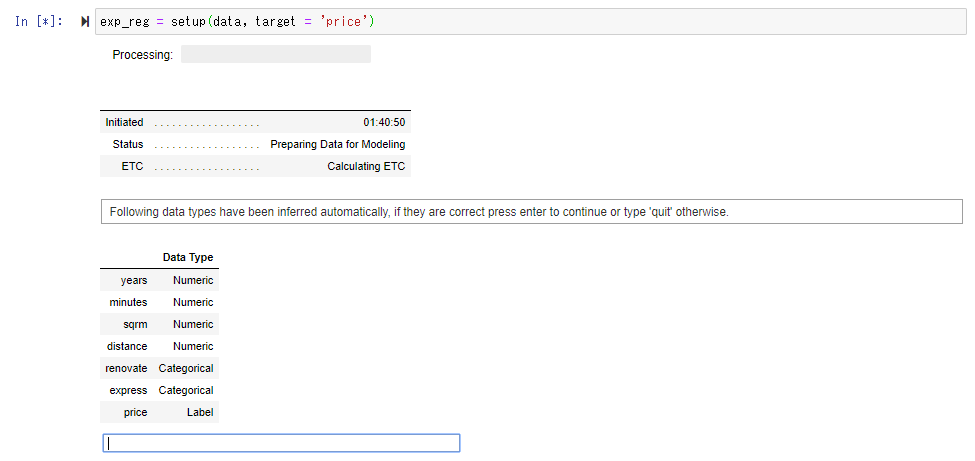
Effectuez le prétraitement nécessaire.


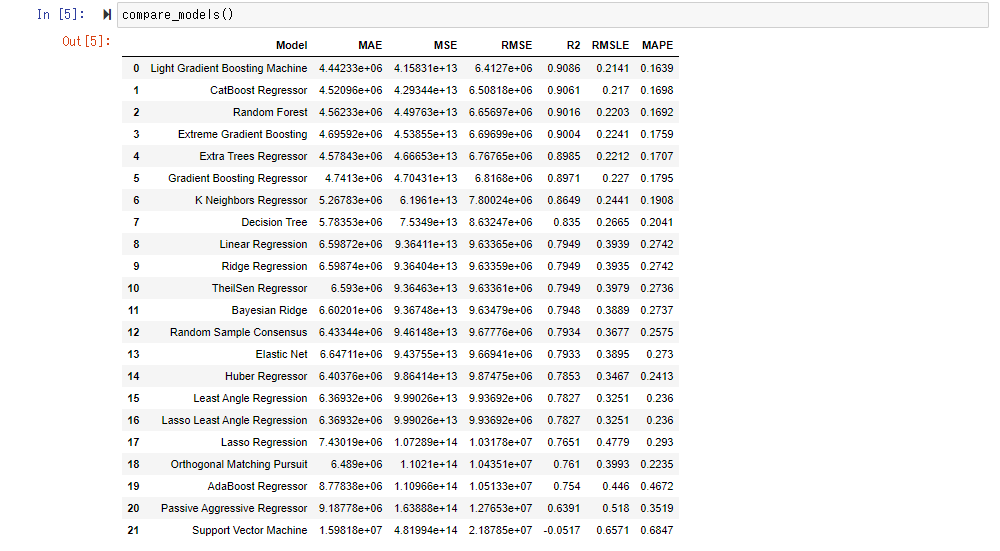
Évaluez et comparez divers modèles avec compare_model () et organisez-les par ordre de moindre erreur. En interne, la validation croisée (les données de l'enseignant et les données de vérification sont échangées uniformément et uniformément) est effectuée, et par défaut, Fold = 10 (les données sont divisées en 10 et les données de formation et les données de vérification sont échangées). Le score moyen est affiché.
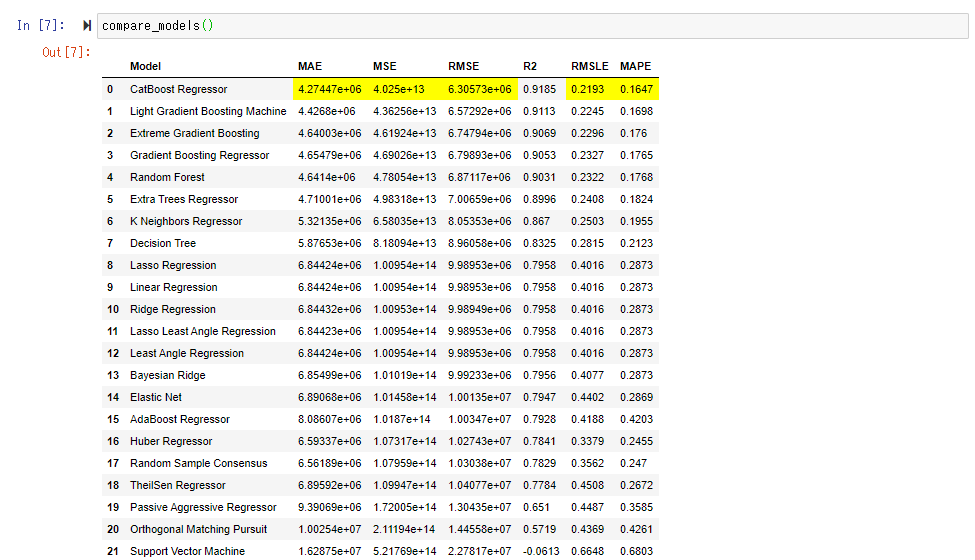
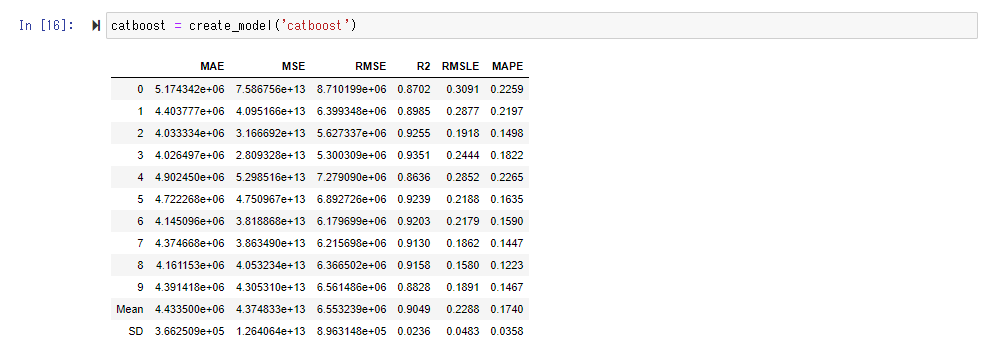
Cette fois, le score de " CatBoost Regressor " semble être bon. Étant donné que RMSE est de 6,3 millions, vous pouvez comprendre à peu près que l'erreur moyenne par appartement est d'environ 6,3 millions.
Exécutez la fonction create_model () pour utiliser le modèle réellement entraîné. Shift + Tab vous donnera un guide sur ce qu'il faut mettre dans l'argument, mais ici nous allons spécifier le "Cat Boost Regressor" avec le meilleur score.
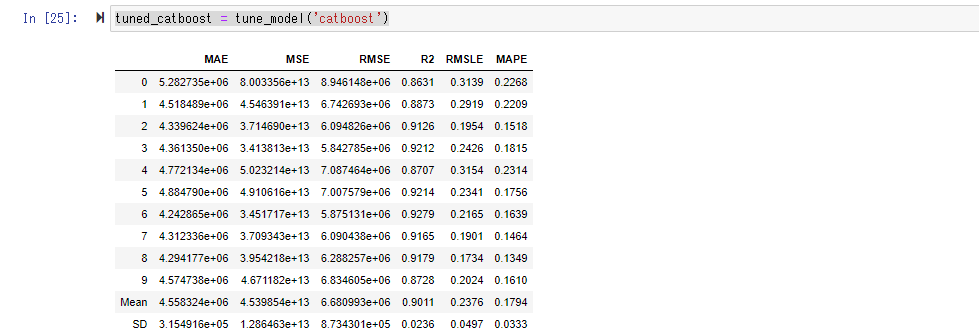
Lorsque vous créez un modèle avec tune_model (), les hyperparamètres (prédéterminés avant l'entraînement, paramètres par défaut pour le comportement du modèle) sont laissés à leurs valeurs par défaut. Trouvez l'hyperparamètre approprié dans la plage prédéfinie. Il semble que la recherche aléatoire soit utilisée ici comme la meilleure méthode de recherche de paramètres.
Visualisez et vérifiez la précision du modèle avec plot_model ().
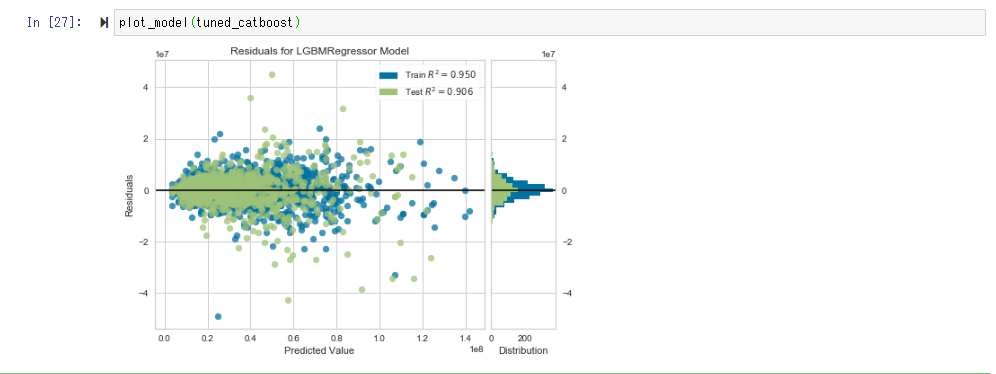
Avec Error Plot, si la prédiction et la mesure sont égales, la distribution s'approche de la ligne droite de y = x.
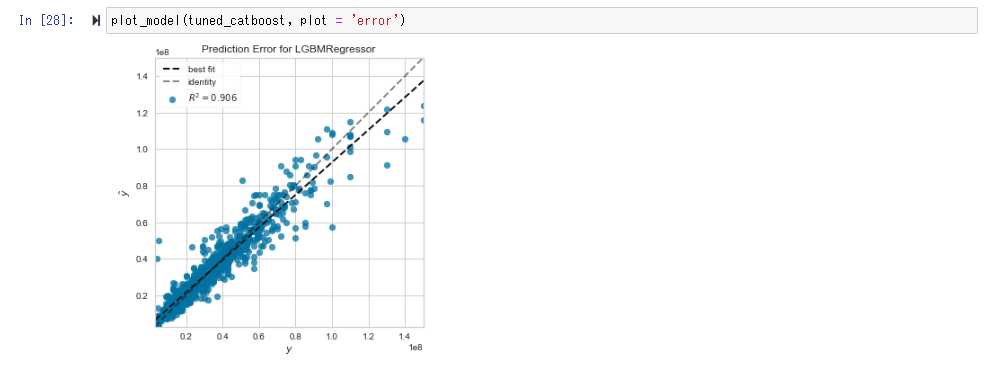
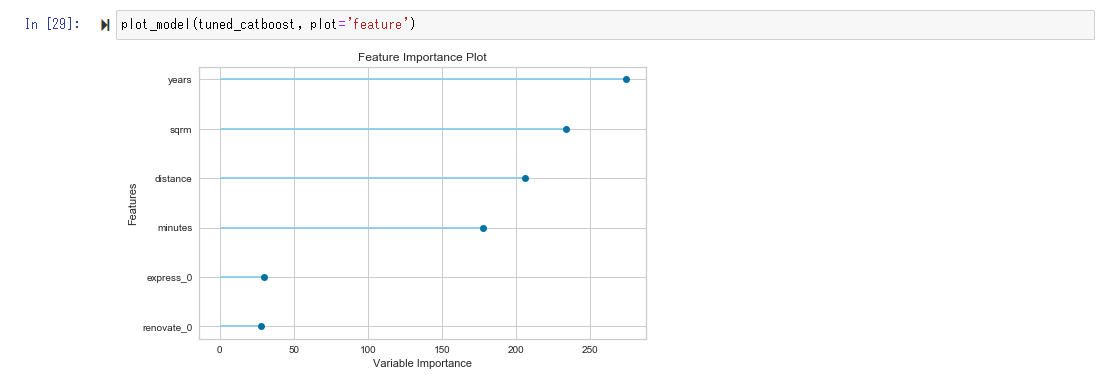
Le tracé de l'importance des caractéristiques vérifie quelles variables sont fortement impliquées dans la prédiction. Dans ce cas, vous pouvez voir que l'influence est forte par ordre d'âge (années), nombre de mètres carrés (m2), distance (distance directe de la gare de Tokyo à la gare la plus proche), minutes (minutes à pied de la gare la plus proche).
Enfin, exécutez finalize_model () pour finaliser le modèle. Vous pouvez voir les hyperparamètres optimisés en imprimant ici.

Maintenant que vous disposez d'un modèle formé, préparez les informations sur le prix des appartements extraites de la page immobilière sur le Web, qui est utilisée pour créer le modèle, et placez-les dans le bloc de données nommé "data_unseen".
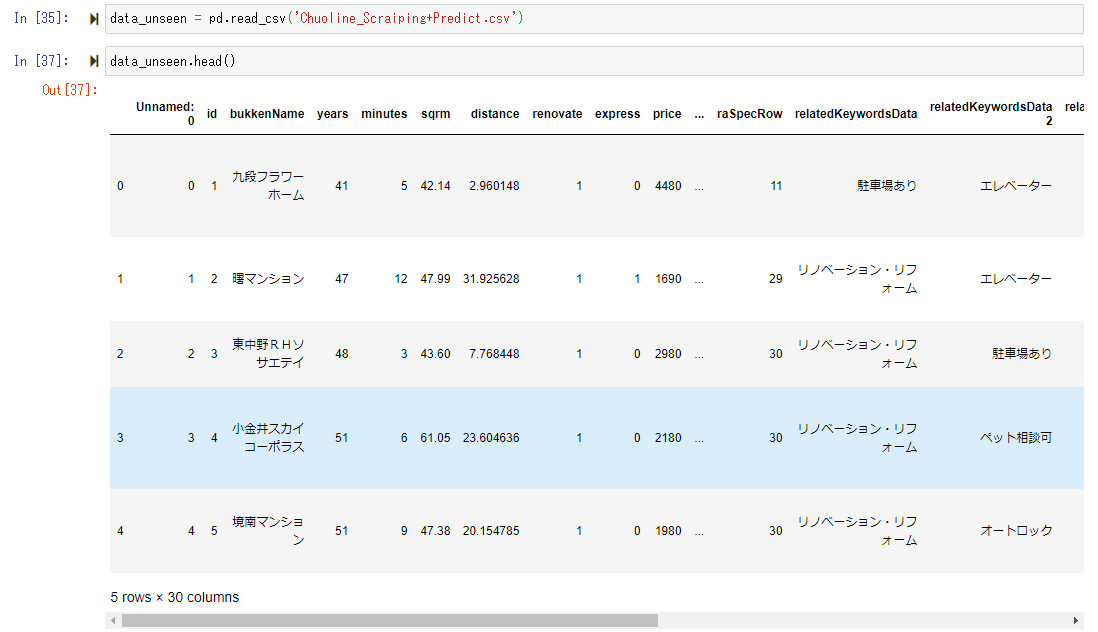
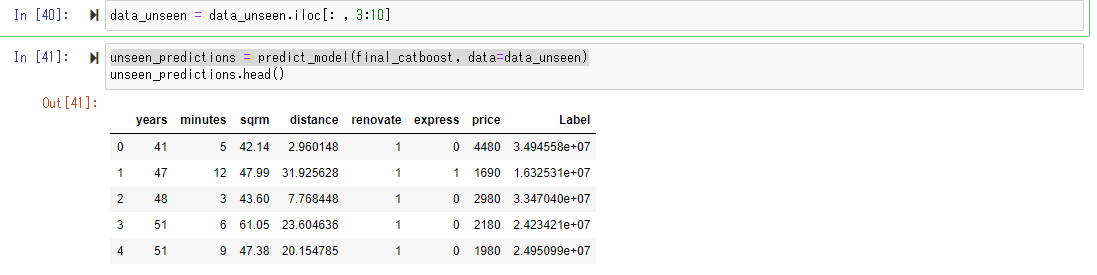
Mettons ce "unseen_data" dans le modèle de prévision que nous venons de créer et laissons-le prédire le prix.
Cette opération est très simple, découpez les variables explicatives sous la même forme que les données d'apprentissage, et utilisez la fonction predict_model () pour calculer la valeur prédite.
Ci-dessous, vous pouvez voir que la valeur prévue a été ajoutée en tant que "Libellé". A l'origine, pour les données inconnues, la variable objective «prix» est inconnue, mais cette fois il y a un prix d'un appartement qui a déjà été publié sur le Web, donc «prix» est inclus dans les données. (Cependant, l'unité d'information publique est de 10 000 yens.) En comparant le "prix" publié sur ce Web avec la valeur prédite "Label" prédite par le modèle de prédiction, c'est une valeur relativement bonne. Vous pouvez sentir que cela sort. (Environ 20 à 40 millions semblent se situer dans la fourchette des prix des appartements à Tokyo.)
Ces données peuvent être déposées en CSV, alors déposez-les en CSV puis connectez-vous à Taleau pour la visualisation.
Si vous comparez le prix "prix" publié sur le Web avec le "Libellé" calculé par le modèle de prévision, vous pouvez trouver des "propriétés au rabais" dont le prix réel est moins cher que la prévision, et vice versa. Hmm. (Ci-après, l'utilisation du prix estimé dans Tableau est la même que ce lien.)
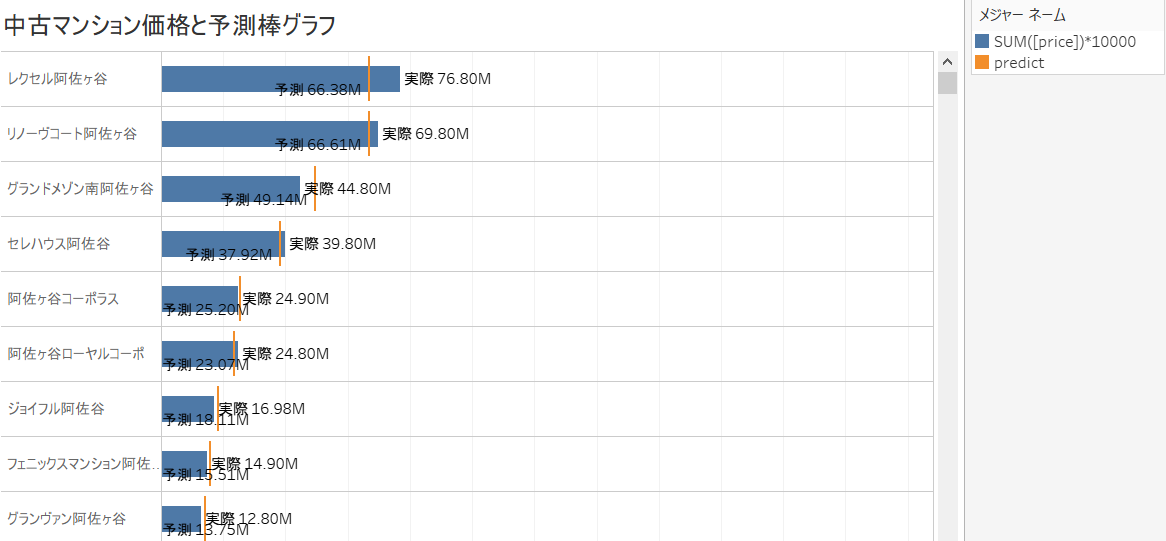
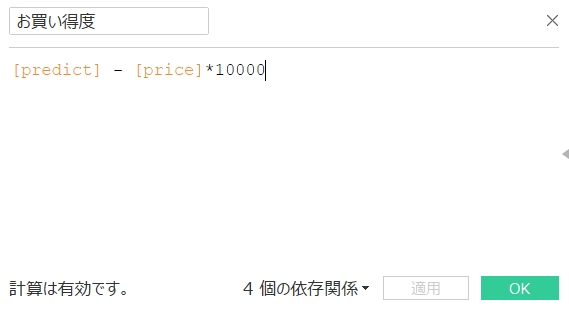
Si la bonne affaire est définie comme un champ calculé comme indiqué ci-dessous et que le prix prévu est supérieur au prix affiché, la bonne affaire est en fait plus élevée que prévu car elle est "moins chère que prévu!", Et inversement le prix prévu est inférieur au prix affiché. , En fait, c'est "plus haut que ce à quoi je m'attendais!", Donc je vais essayer de réduire le marché.
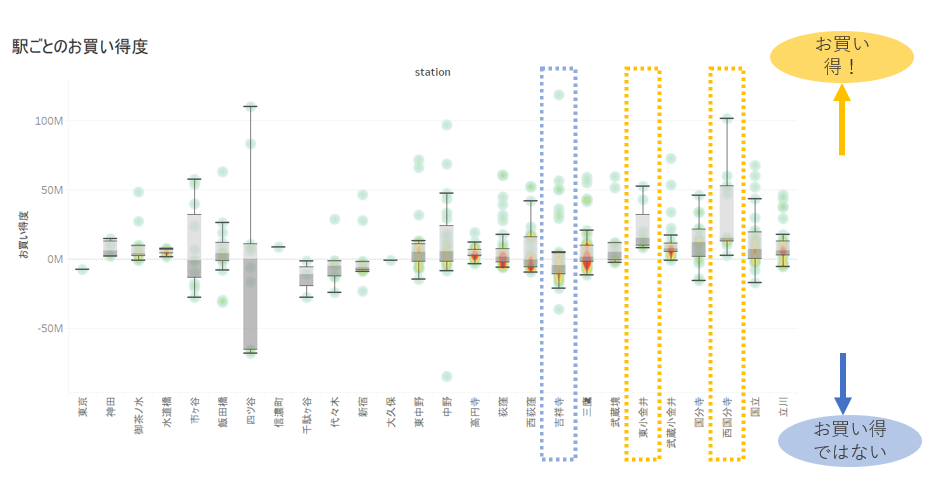
Si vous dessinez un diagramme de barbe pour chaque station et que vous le visualisez, ce sera comme suit.
Il y a des découvertes telles que Yotsuya a une gamme trop large et n'est pas fiable, Kichijoji a une bonne affaire, et Nishikokubunji a une bonne affaire.
Cela suggère qu'en plus de la variable explicative de la distance entre la gare de Tokyo et la gare la plus proche (à quelle distance du centre-ville), il n'y a pas d'explication à moins que de nouveaux facteurs tels que la «popularité de la gare la plus proche» ne soient pris en compte. Vous pouvez l'obtenir. (* Remarque: le fait qu'il s'agisse d'une véritable aubaine ou non dépend des valeurs individuelles, et l'article est écrit en supposant qu'il ne peut être jugé inconditionnellement.)
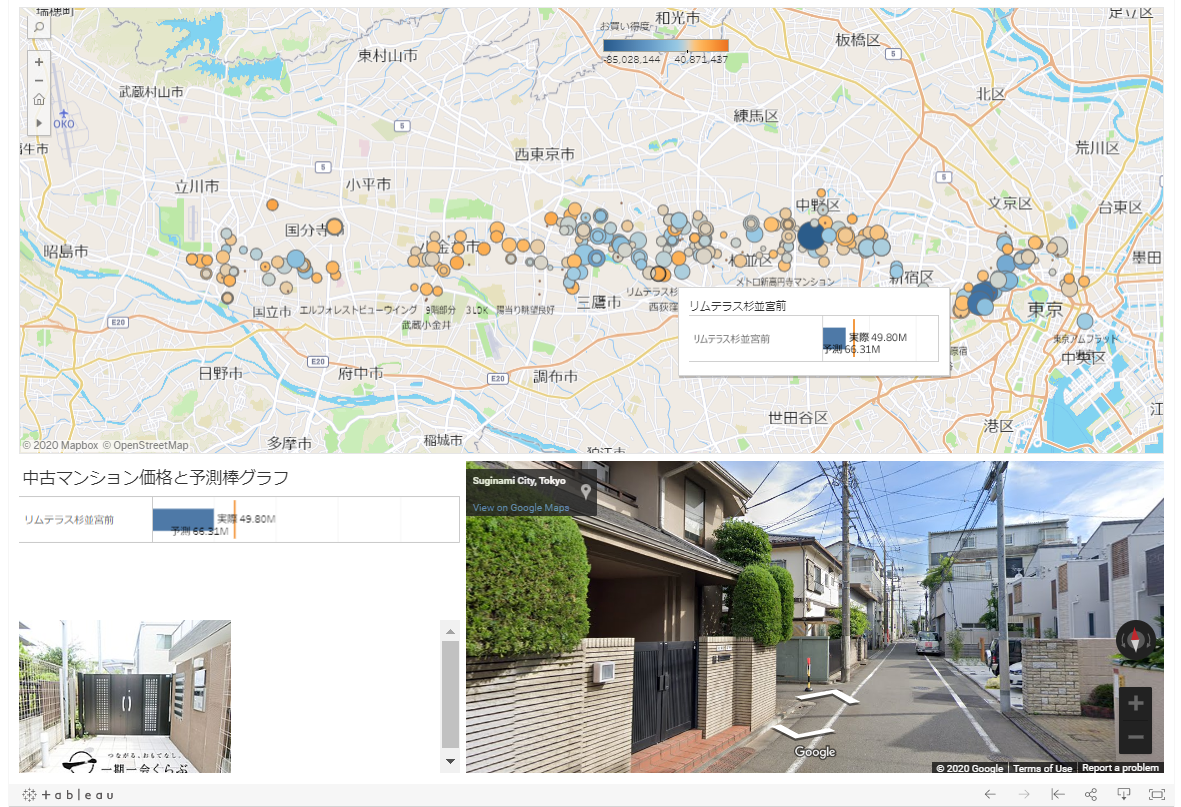
De plus, dans le cadre d'un développement ultérieur de l'utilisation des données, nous allons géocoder la latitude et la longitude à partir des données extraites et cartographier les propriétés des bonnes affaires sur la carte. Ci-dessous, l'orange signifie que la propriété est une bonne affaire, le bleu signifie que ce n'est pas une bonne affaire et la taille du cercle est le prix de la propriété. En cliquant sur le point de la propriété sur la carte, vous pouvez vérifier les informations d'image de la propriété et l'état de la ville environnante en coopération avec Google Street View. Bien sûr, il n'est pas publié ici, mais il est également possible d'afficher des informations sur la propriété dans le tableau de bord en créant un lien vers la page Web publiée.
Comme mentionné ci-dessus, avec PyCaret, le processus initialement requis pour la création de modèle dans l'apprentissage automatique est entièrement exécuté, vous pouvez donc facilement créer un modèle prédictif et des hyperparamètres sans avoir besoin de codage ou de débogage Python. Ce fut un choc de pouvoir régler (gratuitement).
Même si vous réglez Python pour plus de précision, vous pouvez réduire considérablement la charge de travail initiale en utilisant Pycaret comme point de départ.
Cependant, il semble qu'il soit encore nécessaire de comprendre la connaissance minimale des Pandas et la méthode de base de ce qui est mis en œuvre en tant que flux d'apprentissage automatique.
En outre, il est possible de doubler la valeur des données de prévision en visualisant les erreurs avec Tableau, etc., en les rassemblant avec la connaissance du domaine et en envisageant d'ajouter de nouvelles variables explicatives, et en utilisant les résultats de prédiction dans un tableau de bord interactif. N'est-ce pas possible?
En plus de l'ensemble, PyCaret semble être en mesure d'effectuer la classification, le clustering, la détection d'anomalies, le traitement du langage naturel et l'analyse d'association pour la régression que nous avons reprise cette fois, veuillez donc ajouter des exemples pratiques que vous utiliserez à l'avenir. je pense
Classification Regression Clustering Anomaly Detection Natural Language Processing Association Rule Mining
Veuillez essayer.
Les références:
Article Qiita:
Recommended Posts