[PYTHON] Enquête sur l'utilisation du machine learning dans les services réels
Je comprends comment fonctionne l'apprentissage automatique, mais comment est-il utilisé dans les services réels? Je me demande si l'environnement d'apprentissage achète seul un GPU. Ou le cloud est-il le courant dominant?
Je pense que tout le monde s'est déjà posé des questions sur comment l'utiliser dans la pratique et comment le développer. J'ai franchi le pas et répondu à un questionnaire lorsque j'étais en charge du cours pour ceux qui se demandaient et pensaient l'utiliser dans la pratique.
La cible était les personnes qui utilisent l'apprentissage automatique dans la pratique, et nous avons pu obtenir 32 réponses (merci à ceux qui ont répondu!) Veuillez noter qu'il peut y avoir un biais d'échantillonnage car les réponses ont été sollicitées sur Twitter / Facebook. Ci-dessous, je voudrais publier les résultats avec mes conclusions.
- Je voulais publier les résultats du questionnaire brut, mais j'ai omis le lien vers les données brutes car les réponses de forme libre incluaient des informations de confidentialité.
Q1. Veuillez me dire l'utilisation de l'apprentissage automatique.
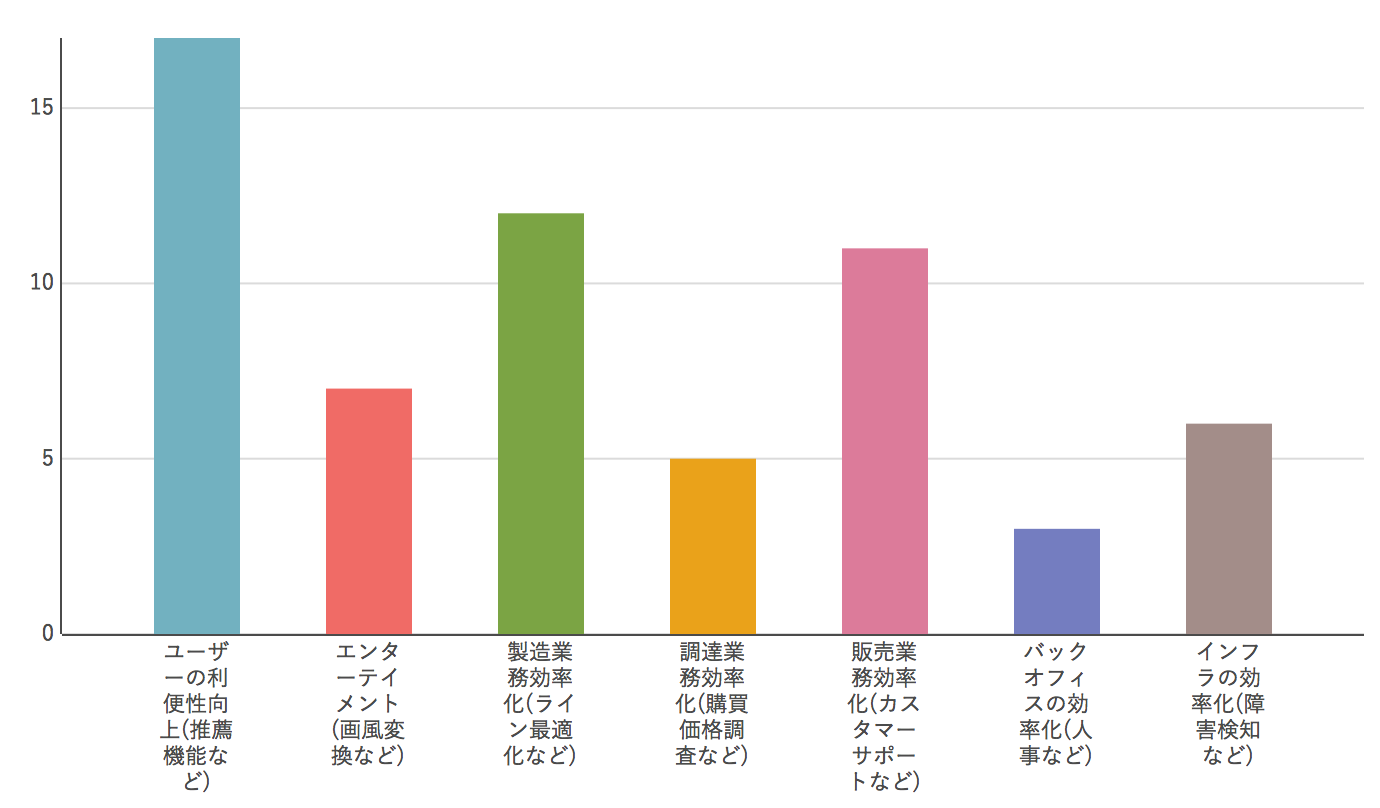
C'était une question à poser, "Dans quel but utilisez-vous l'apprentissage automatique en premier lieu?" C'était un chiffre convaincant car il existe de nombreux cas où il est utilisé pour améliorer les recommandations et le support client, mais il était surprenant que l'amélioration des opérations de fabrication ait également augmenté considérablement. J'avais l'impression qu'il y avait beaucoup de (vraies) solutions vendues ici, mais elles n'ont pas encore été mises en pratique, donc j'ai été personnellement surpris qu'elles se développent jusqu'à ce point.
Q2. Veuillez me dire comment fournir l'apprentissage automatique aux clients.
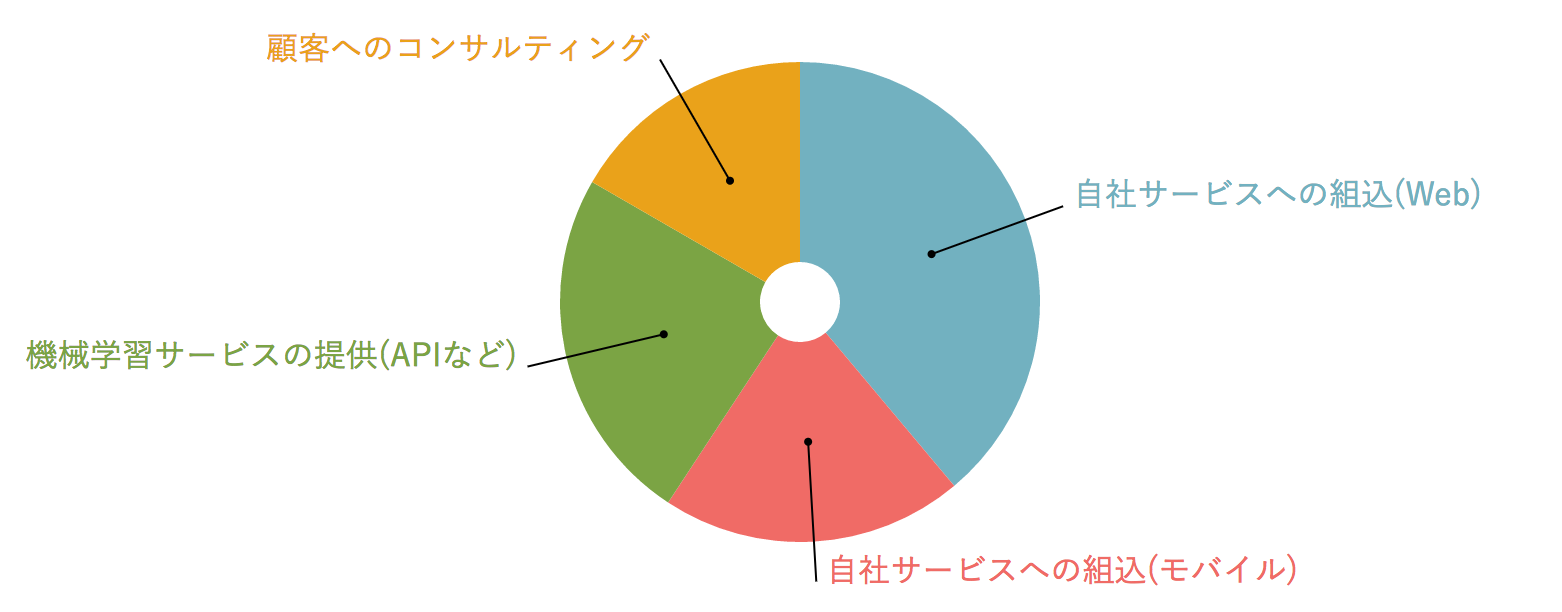
C'était une question pour confirmer qu'il existe différentes formes de fourniture, que l'on peut qualifier d'apprentissage automatique. On peut supposer que l'intégration dans le service interne est la première, et il existe de nombreuses utilisations pour «l'utiliser pour améliorer le service interne». Personnellement, je pensais qu'il y avait de nombreuses formes comme la consultation en machine learning, mais cela n'a pas grandi beaucoup.
Q3. Veuillez nous indiquer le domaine de l'apprentissage automatique que vous utilisez.

C'était une question à poser au domaine de la technologie utilisée. Les images et le langage naturel sont toujours deux tours géantes, mais ce que je voulais confirmer ici, c'était à quel point les technologies dites de «système de génération» telles que GAN et Neural Conversational Model sont utilisées dans les services réels. Il n'y a pas encore beaucoup d'exemples de résultats, et il s'est avéré que l'utilisation du système de reconnaissance est l'objectif principal. Ce qui était surprenant, c'est qu'il y avait environ 5 cas d'apprentissage par renforcement. Système de bandit de publicité ou de contrôle de robot ... Je ne sais pas car je n'en ai pas pris beaucoup, mais j'aimerais l'utiliser en pratique.
Q4. Veuillez nous parler de l'environnement utilisé pour l'apprentissage automatique.

Où est fait tout cet apprentissage automatique? C'était une question pour confirmer cela. Le résultat est en grande partie notre propre environnement! Après tout, si vous l'utilisez sérieusement dans le service, il semble qu'il vaut mieux construire l'environnement fermement. Cependant, comme chaque entreprise se concentre sur l'environnement GPU, le ratio peut changer à l'avenir.
Q5. Veuillez me dire où obtenir les données pour l'apprentissage automatique.
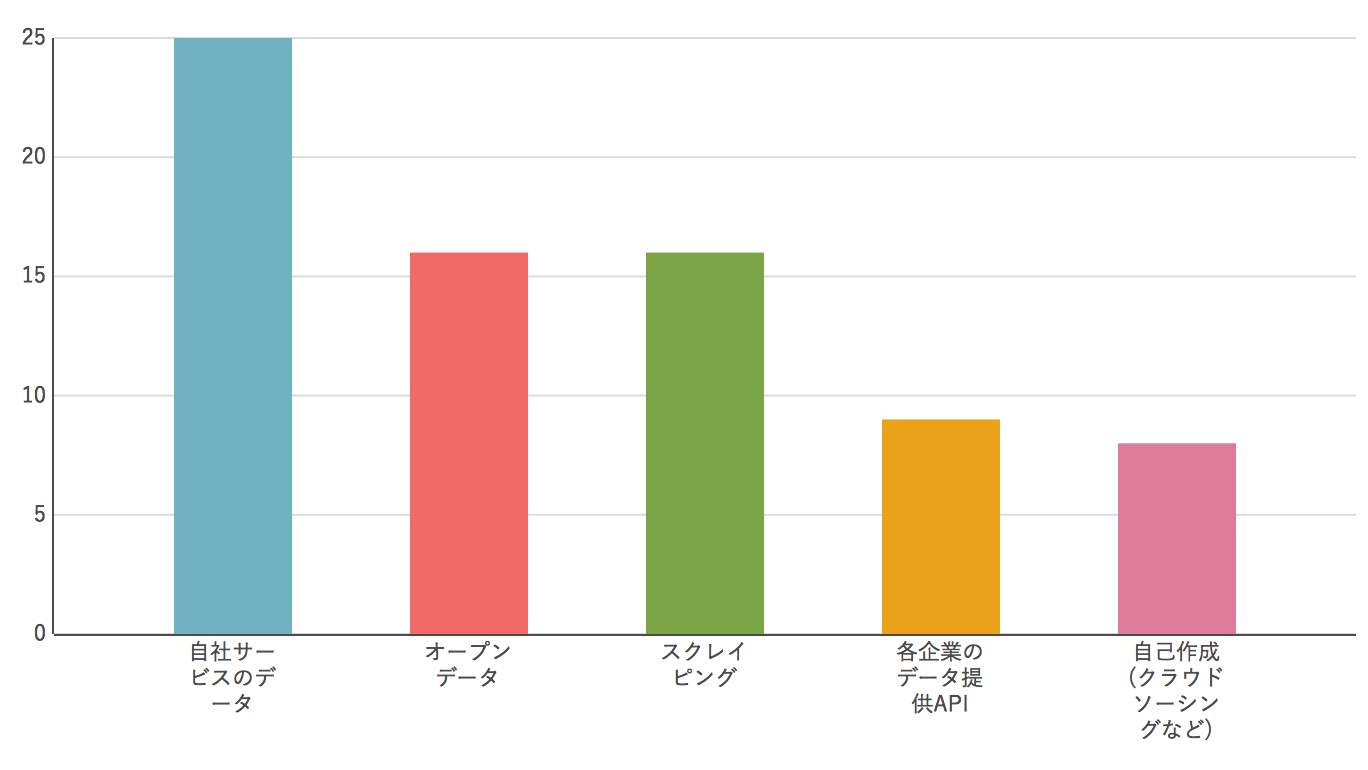
C'était une question pour confirmer le gros problème de l'apprentissage automatique, "Comment préparer les données?". Non seulement les données internes, mais aussi les données ouvertes et le scraping se portent plutôt bien. Au début, bien sûr, nous partons de l'endroit où il n'y a pas de données, donc savoir quel type de données publiques est disponible et (même si je ne peux pas le faire ouvertement) la technologie de grattage est important pour collecter des données. ..
Q6. Veuillez nous parler des événements douloureux liés à l'apprentissage automatique.
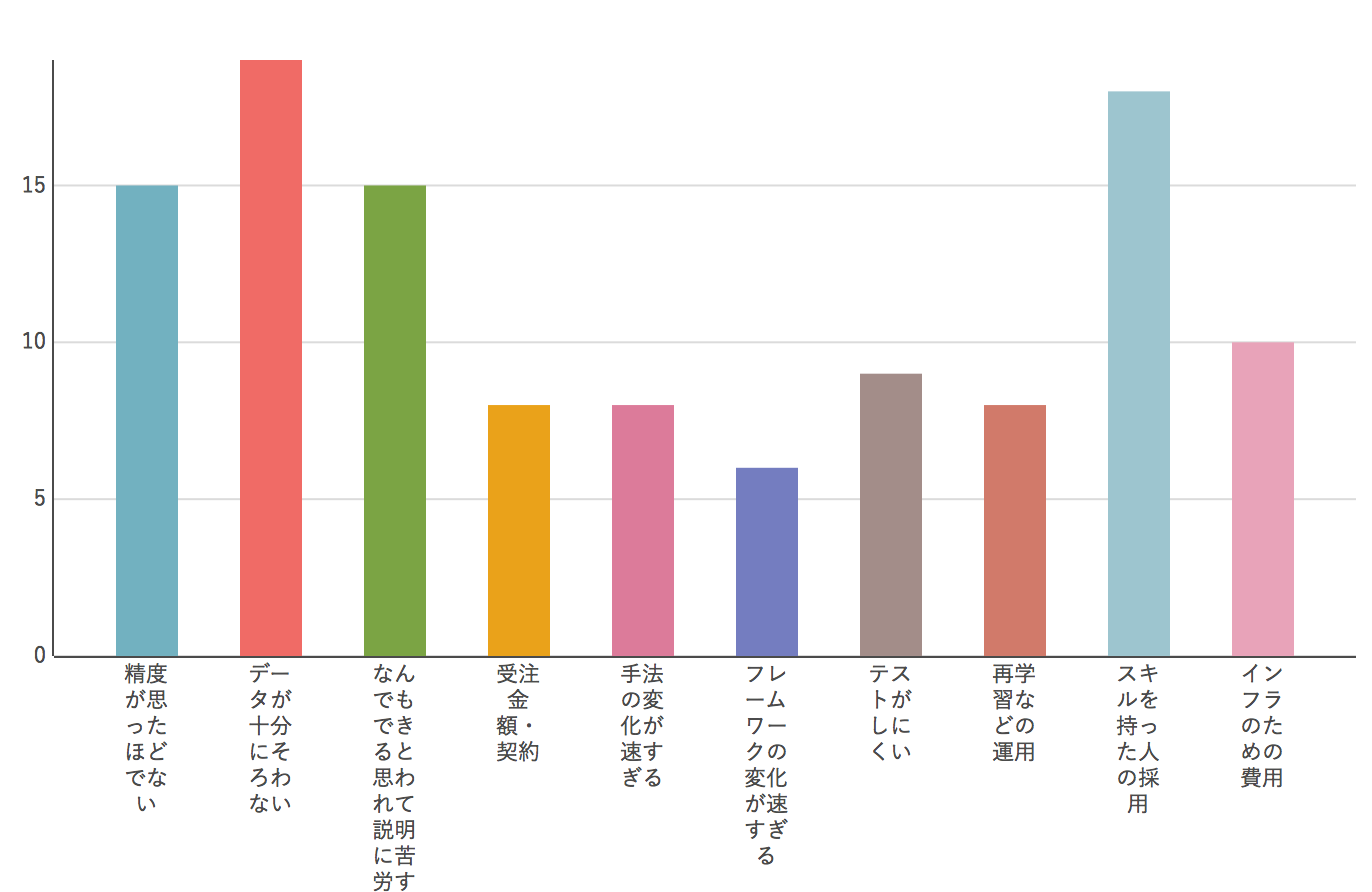
C'était une question pour savoir à quel point j'étais sympathique à mes préoccupations personnelles. Après tout, c'est un problème de «données» et de «ressources humaines». Cela semble être un casse-tête partout. Il semble qu'il y ait de nombreux problèmes tels que "la précision ne sort pas" qui est sorti comme finaliste, et "il semble que vous pouvez faire n'importe quoi et c'est difficile à expliquer". De nouveaux frameworks et méthodes d'apprentissage automatique apparaissent les uns après les autres dans ce domaine, mais en ce sens, il était surprenant que les changements de frameworks et de méthodes aient été trop rapides. En pratique, il y en a probablement quelques fixes, et il est peu probable que vous suiviez les autres (dans la plage d'observation personnelle, il semble que TensorFlow / Chainer soit presque solidifié dans le système DNN (domestique). seulement)).
De plus, comme il est difficile de garantir les résultats de l'apprentissage automatique, j'ai pensé qu'il pourrait y avoir des problèmes avec le montant de la commande et le contrat, mais cela n'a pas beaucoup augmenté ici. En premier lieu, il y a beaucoup de gens qui l'utilisent pour leurs propres services, donc il se peut que cela ne croisse pas beaucoup ici non plus.
Q7. Autres opinions
Je n'ai pas répondu à beaucoup de questions de forme libre, mais le problème de l'embauche et de la formation, et l'incohérence (bruit) contenue dans les données saisies par les humains ont été mentionnés comme des maux de tête. Était là. En outre, il y a une déclaration selon laquelle il y a aussi un problème concernant le modèle qui a produit des résultats en langage naturel, "Est-ce que ça marche en japonais?", Donc je pense que c'est certainement un point difficile.
Comment était-ce. Nous espérons que ce résultat vous aidera à imaginer plus concrètement «l'apprentissage automatique sur le terrain». Nous faisons cela! Si vous avez une telle voix, laissez un commentaire.
Recommended Posts