Utilisons les données ouvertes de "Mamebus" en Python
La Division de la planification urbaine et des politiques de transport de la ville de Kusatsu convertit le bus communautaire de la ville de Kusatsu «Mame Bus» en données ouvertes. http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.html
Ici, je traiterai les données de ce "Mame Bus". Le but est de télécharger automatiquement toutes les données et de construire correctement la base de données pour rendre les données du bus disponibles sur le Web. À ce stade, les données Excel doivent être analysées non seulement sous Windows mais également sous Linux.
Cela permet d'utiliser automatiquement les dernières données sur de nombreux serveurs de location, etc. (dans certaines modifications) sans intervention humaine.
** démo ** http://needtec.sakura.ne.jp/bus_data/kusatu.html

Github https://github.com/mima3/bus_data
Utilisez la commande suivante pour télécharger les données et créer la base de données.
python import.py application.ini
Si les données sont mises à jour, vous pouvez toujours obtenir les dernières avec cette commande. C'est une bonne idée de l'exécuter régulièrement avec cron.
Description des données
Chaque ligne comprend les trois configurations suivantes.
| Nom | format | La description |
|---|---|---|
| calendrier | Excel | Ce sont les données qui décrivent l'heure d'arrivée de chaque gare routière. L'heure d'arrivée peut varier selon les jours de la semaine, les samedis et les jours |
| Arrêtez | csv | Arrêtezの名前、読み、座標が格納されたCSVデータです。 Il peut y avoir plusieurs données, dans le sens horaire et antihoraire, sur le même itinéraire. |
| le plan de route | shape | le plan de routeの形状を表したshapeファイルです。この測地系は「平面直角2000(Série 6)Veuillez noter que. Il peut y avoir plusieurs données, dans le sens horaire et antihoraire, sur le même itinéraire. |
Il y a quelques points à garder à l'esprit lorsque vous travaillez avec des données.
Il y a plusieurs arrêts de bus avec le même nom d'arrêt de bus.
Il y a plusieurs arrêts de bus avec le même nom.
Par exemple, jetez un œil à M04_stops_ccw.csv. Il y a deux lignes à la sortie Nomura Athletic Park. La sortie Nomura Athletic Park au 135.954709,35.023382 et la sortie Nomura Athletic Park au 135.954445,35.023323.
Les bus dans la même position s'arrêtent plusieurs fois sur le même itinéraire
Même si le bus s'arrête au même endroit, il peut s'arrêter plusieurs fois sur le même trajet.
Par exemple, jetez un œil à M04_stops_ccw.csv. La sortie ouest de la gare de Kusatsu s'arrête aux 1er et 37e arrêts.
L'ordre d'arrêt est répertorié dans la deuxième ligne du CSV.
Fluctuation de la notation CSV et Excel
Le nom de l'arrêt de bus peut différer entre Excel et CSV. Certains ont des noms différents, comme des sauts de ligne et pas seulement des différences de demi-largeur et de pleine largeur.
| csv | excel |
|---|---|
| Devant l'école primaire de Yamada | École primaire Yamada |
| Kinogawa Higashi | Kikawa Higashi |
| Nishi Shibukawa 1-chome | Nishi Shibukawa 1-chome |
| Nomura 8-chome | Nomura 8-chome |
| Devant le Shindo Junior High School | Lycée Shindo |
Manière incohérente d'exprimer les jours dans l'horaire
Normalement, la disposition des données dans Excel est la même, mais elle est différente pour chaque classeur.
Jetez un œil à M01_stop_times.xlsx.

Dans ce classeur, la présence ou l'absence de "●" détermine s'il s'agit d'un samedi ou d'un jour de semaine. Mais regardons un autre M03_stop_times.xlsx.
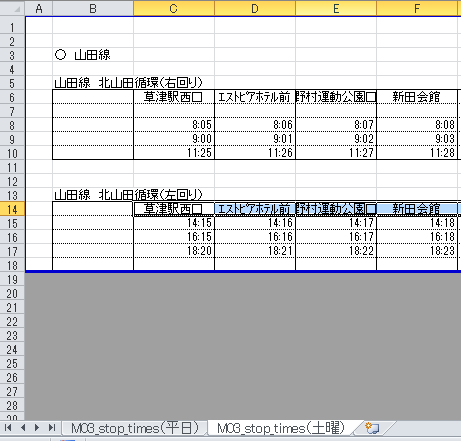
Ici, les jours sont répartis pour chaque feuille.
| Nom du livre | Comment déterminer le jour |
|---|---|
| M01_stop_times.xlsx | Jugement par ● |
| M02_stop_times.xlsx | Jugement par ● |
| M03_stop_times.xlsx | Feuille fractionnée |
| M04_stop_times.xlsx | Feuille fractionnée |
| M05_stop_times.xlsx | Aucune mention du jour |
Comme vous pouvez le deviner, il est préférable de considérer que la position de départ des données est différente pour chaque livre.
Ligne vierge entre le nom et l'heure de l'arrêt de bus
Puisque l'heure est entrée à partir de la ligne suivante du nom de l'arrêt de bus, vous pouvez effectuer une recherche à partir de là et juger que l'horaire est terminé si toutes les lignes sont vides.
Cependant, cela ne peut pas. Jetons un coup d'œil à la ligne Yamada (circulation Kinogawa: sens antihoraire) de M04_stop_times.xlsx. La ligne après le nom de l'arrêt de bus est complètement vide et les données commencent à partir de la ligne suivante.
Placement des données non évolutif
Dans le cas de la feuille suivante, même si le nombre de bus augmente, la quantité de données change simplement, il n'y a donc pas de changement dans le processus d'analyse d'Excel.
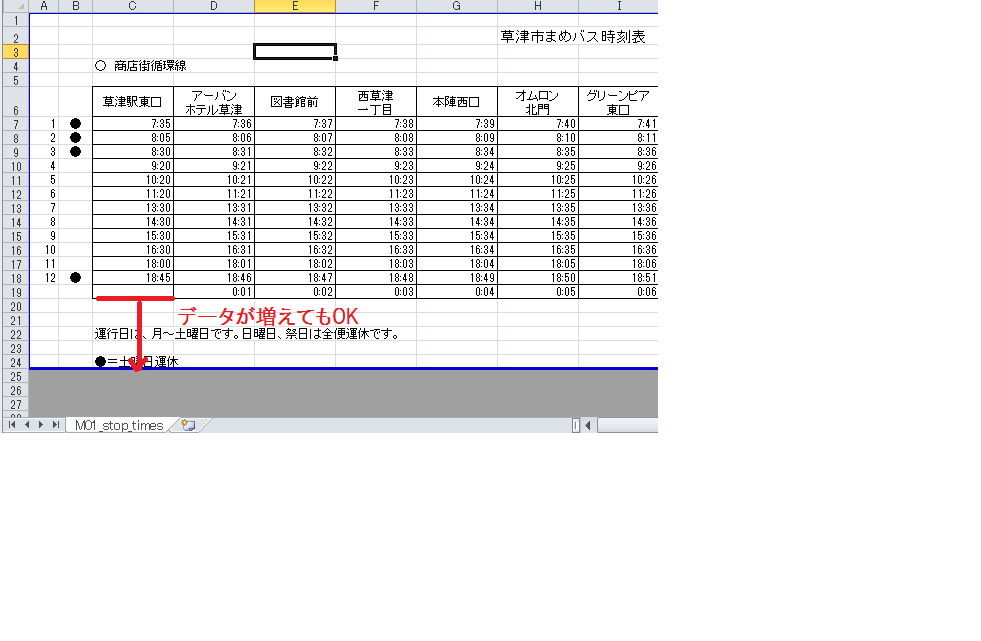
Mais considérez la ligne suivante.

Dans cet exemple, à mesure que la quantité de données augmente, la position de départ des données en bas se déplace également, il est donc nécessaire de modifier le traitement.
Exemples gérés par Python
Gérer les fichiers Excel
Pour travailler avec Excel en Python, utilisez xlrd. https://github.com/python-excel/xlrd
Certains exemples utilisant cette bibliothèque sortiront lorsque vous google, mais en gros, il est préférable de le créer en se référant à l'exemple de code officiel.
https://github.com/python-excel/xlrd/blob/master/scripts/runxlrd.py
Par exemple, les exemples d'implémentation suivants sont courants.
from xlrd import open_workbook
wb = open_workbook('test_err.xlsx')
for sh in wb.sheets():
for row in range(sh.nrows):
values = []
for col in range(sh.ncols):
v = sh.cell(row,col).value
if not isinstance(v, basestring):
v = str(v)
v = v + ':' + str(sh.cell(row,col).ctype)
values.append(v)
print ','.join(values)
Le code ci-dessus fonctionne très bien avec les extensions XLS et xlsx sans fusion de cellules. Toutefois, une erreur se produit si vous utilisez une feuille qui a les fusions de cellules suivantes.
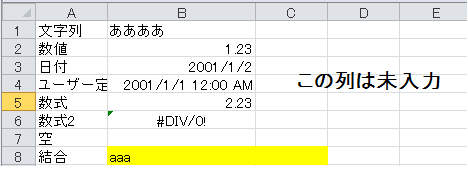
** contenu de l'erreur **
Traceback (most recent call last):
File "test2.py", line 7, in <module>
v = sh.cell(row,col).value
File "C:\Python27\lib\site-packages\xlrd-0.9.3-py2.7.egg\xlrd\sheet.py", line
399, in cell
self._cell_types[rowx][colx],
IndexError: array index out of range
Apparemment, le nombre de colonnes est différent pour chaque ligne et j'ai besoin d'obtenir le nombre de colonnes pour chaque ligne. Vous pouvez éviter ce problème en obtenant le nombre de colonnes pour chaque ligne avec row_len comme indiqué ci-dessous.
from xlrd import open_workbook
wb = open_workbook('test_err.xlsx')
for sh in wb.sheets():
for row in range(sh.nrows):
values = []
for col in range(sh.row_len(row)):
v = sh.cell(row,col).value
if not isinstance(v, basestring):
v = str(v)
v = v + ':' + str(sh.cell(row,col).ctype)
values.append(v)
print ','.join(values)
De plus, la méthode d'affichage de la date est également implémentée dans runxlrd.py, vous devriez donc la lire une fois pour le moment.
Comment capturer des données
Comme mentionné précédemment, il existe des sections qui mettent Excel dans l'ambiance, il est donc nécessaire de gérer chacune avec souplesse. Par conséquent, j'ai enregistré la méthode d'importation des données dans le fichier de paramètres JSON et j'ai essayé d'importer les données en les regardant.
https://github.com/mima3/bus_data/blob/master/data/kusatu.json
Branche de traitement après téléchargement
Cette fois, les données compressées et les données non compressées sont mélangées. Par conséquent, le traitement après le téléchargement est décrit en téléchargeant le fichier de configuration.
data/kusatu.json
"download" : {
"http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.files/M01_stop_times.xlsx" : "save_local",
"http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.files/M01_stops_ccw.csv" : "save_local",
"http://www.city.kusatsu.shiga.jp/kurashi/kotsudorokasen/mamebus/opendata.files/M01_shapes.zip" : "expand_zip",
save_local enregistre sur le disque local. expand_zip exécute le processus de décompression après l'enregistrement.
Voir ci-dessous pour le code réel. https://github.com/mima3/bus_data/blob/master/downloader.py
Correspond à la fluctuation de la notation CSV et EXCEL
Correspond aux fluctuations de la notation CSV et Excel.
Les règles de base sont les suivantes. ・ Convertissez le nom de la gare routière en fonction de la convert_rule du fichier de réglage ・ Supprimer les sauts de ligne ・ Changez la demi-largeur en pleine largeur.
** Convertir le nom de l'arrêt de bus **
data/kusatu.json
"convert_rule" : {
"Devant l'école primaire de Yamada": "École primaire Yamada",
"Kinogawa Higashi":"Kikawa Higashi",
"Nishi Shibukawa 1-chome": "Nishi Shibukawa 1-chome",
"Nomura 8-chome": "Nomura 8-chome",
"Devant le Shindo Junior High School": "Lycée Shindo"
},
bus_data_parser.py
def convert_bus_stop_name(rule, bus_stops):
for bus_stop in bus_stops:
if bus_stop['stopName'] in rule:
bus_stop['stopName'] = rule[bus_stop['stopName']
** Supprimez les sauts de ligne et créez une demi-largeur pleine largeur **
bus_data_parser.py
def get_bus_timetable(wbname, sheetname, stop_offset_row, stop_offset_col, stopdirection, timetable_offset_row, timetable_offset_col, chk_func):
xls = xlsReader(wbname, sheetname)
stop_name_list = []
if stopdirection == DataDirection.row:
busdirection = DataDirection.col
else:
busdirection = DataDirection.row
xls.set_offset(stop_offset_row, stop_offset_col)
while True:
v = xls.get_cell()
if not v:
break
v = zenhan.h2z(v)
v = v.replace('\n', '')
stop_name_list.append(v)
xls.next_cell(stopdirection)
Zenhan est utilisé pour la conversion demi-largeur et pleine largeur. https://pypi.python.org/pypi/zenhan
Description des règles d'importation pour les fichiers CSV, EXCEL, Shape
Spécifiez comment importer chaque fichier comme suit.
"import_rule" : [
{
"operation_company" : "Ville de Kusatsu",
"line_name" : "Ligne de circulation de la rue commerçante",
"shape" : "M01_shapes/M01.shp",
"srid" : 2448 ,
"timetables" : [
{
"route" : "Route1L",
"routeName" : "Ligne de circulation de la rue commerçante",
"bus_stops" : "M01_stops_ccw.csv",
"weekday_timetable" : {
"workbook" : "M01_stop_times.xlsx",
"sheetname" : "M01_stop_times",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3
},
"saturday_timetable" : {
"workbook" : "M01_stop_times.xlsx",
"sheetname" : "M01_stop_times",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3,
"check_func" : "check_shoutengai_saturday"
},
"holyday_timetable" : {
}
}
]
}, //Abréviation
{
"operation_company" : "Ville de Kusatsu",
"line_name" : "Ligne Yamada (circulation Kitayamada)",
"shape" : "M03_shapes/M03.shp",
"srid" : 2448 ,
"timetables" : [
{
"route" : "Route3R",
"routeName" : "Ligne de circulation Kitayamada dans le sens des aiguilles d'une montre",
"bus_stops" : "M03_stops_cw.csv",
"weekday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_horaires (en semaine)",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3
},
"saturday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_horaires (samedi)",
"stop_offset_row" : 6,
"stop_offset_col" : 3,
"timetable_offset_row" : 7,
"timetable_offset_col" : 3
},
"holyday_timetable" : {
}
},
{
"route" : "Route3L",
"routeName" : "Ligne de circulation Kitayamada dans le sens antihoraire",
"bus_stops" : "M03_stops_ccw.csv",
"weekday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_horaires (en semaine)",
"stop_offset_row" : 14,
"stop_offset_col" : 3,
"timetable_offset_row" : 15,
"timetable_offset_col" : 3
},
"saturday_timetable" : {
"workbook" : "M03_stop_times.xlsx",
"sheetname" : "M03_stop_horaires (samedi)",
"stop_offset_row" : 14,
"stop_offset_col" : 3,
"timetable_offset_row" : 15,
"timetable_offset_col" : 3
},
"holyday_timetable" : {
}
}
]
}, //Abréviation
Les fichiers "shape" et "srid" sont liés au fichier de forme. Décrivez le nom du fichier de forme dans la forme et le système géodésique dans srid.
"Bus_stops" est lié au fichier csv. Décrivez le nom du fichier CSV dans bus_stops.
Les fichiers Excel sont répertoriés les jours de la semaine, les samedis et les jours fériés. Nom du classeur dans le classeur Nom de la feuille dans le nom de la feuille stop_offset_row, la position de départ où le nom de l'arrêt de bus est écrit dans stop_offset_col, Décrivez la position de départ où l'heure est décrite dans schedule_offset_row et schedule_offset_col. check_func est un élément optionnel qui spécifie la fonction de rappel à exécuter chaque fois qu'une ligne d'horaire est lue.
Ici, la valeur d'une colonne spécifique est vérifiée comme indiqué ci-dessous, et si les données ne sont pas valides, False est renvoyé et la ligne est ignorée. Ceci est utilisé pour le jugement de samedi.
import.py
class BusParserCallBack(object):
def check_shoutengai_saturday(self, workbook, sheet, busrow, buscol, item):
if sheet.cell(busrow - 1, 2 - 1).value:
return True
else:
return False
Gestion des fichiers Shape
Pour Python, c'est une bonne idée d'utiliser pyshp. Veuillez vous référer à ce qui suit.
** Essayez d'importer dans la base de données en manipulant ShapeFile d'informations numériques sur les terres nationales avec Python ** http://qiita.com/mima_ita/items/e614a281807970427921
Conversion du système d'enquête
Le système géographique du fichier de forme de Mamebus est "Angle droit plan 2000 (système 6)" et le SRID est 2448. Cela doit être converti en un système de géographie mondiale. Cette conversion est assez ennuyeuse, mais elle peut être facilement gérée avec une base de données qui gère la géométrie telle que Spatia Lite.
Dans le cas de Spatialite, vous pouvez le renvoyer en exécutant le SQL suivant.
select AsText(Transform(GeomFromText('POINT(-4408.916645 -108767.765479)', 2448), 4326))
Le code python ressemble à ceci:
bus_db.py
for timetable in timetables:
database_proxy.get_conn().execute(
"""
INSERT INTO RouteTable
(metaData_id, operationCompany, lineName, route, routeName, geometry)
VALUES(?, ?,?,?,?,Transform(GeometryFromText(?, ?),?))
""",
(
meta_id,
operation_company,
line_name,
timetable['route'],
timetable['routeName'],
routedict[timetable['route']], src_srid, SRID
)
)
Résumé
De cette façon, si vous utilisez la bibliothèque Python, vous pouvez utiliser les données de "Mamebus" sans faire attention particulière.
Cependant, les données sont assez bizarres et ne sont pas structurées pour supposer une analyse automatique, vous aurez donc du mal à y arriver.
Si vous souhaitez faciliter la gestion des données avec une machine et améliorer le côté données, je pense que les points suivants sont nécessaires. ・ Cohérence des données entre différents fichiers tels que CSV et Excel ・ Unifiez le format car il est inévitable d'utiliser Excel ・ Tenez compte du moment où la quantité de données augmente.
Recommended Posts