[PYTHON] Comment augmenter le nombre d'images de jeux de données d'apprentissage automatique
Importance du remplissage d'image
Un bon ensemble de données de formation est nécessaire pour améliorer la précision de la classification, comme CNN pour l'apprentissage en profondeur. Afin d'assurer l'exactitude, il est nécessaire de concevoir les éléments suivants.
- Préparez un nombre suffisant d'images.
- Alignez le nombre d'images pour chaque tag
- Marqué plus précisément
- Même s'ils sont dans la même catégorie, s'ils semblent différents, séparez les balises en détail.
Pour cela, vous avez juste besoin d'un certain nombre de feuilles. Selon le type, le nombre de feuilles peut être biaisé, et il est difficile d'extraire et d'étiqueter le tout à la main.
Par conséquent, nous envisagerons d'augmenter le nombre d'images en traitant les images qui ont été marquées dans une certaine mesure. Voici quelques techniques. L'explication est basée sur l'opinion que Reni Takashiro devrait être utilisé comme échantillon pour le traitement d'image. Utiliser.
Méthode de gonflage
Implémenté dans OpenCV 3.0 Python. Voici une source que vous pouvez réellement utiliser pour le remplissage.
Réglage du contraste
Crée une image avec un contraste amélioré et réduit.
Pour accentuer, définissez 0 pour les pixels à faible luminosité en dessous d'un certain niveau et 255 pour les pixels à forte luminosité au-dessus d'un certain niveau, et ajustez ceux avec une luminosité intermédiaire.
Inversement, pour le réduire, ajustez la largeur de la luminosité pour qu'elle soit plus petite. Ce chiffre est facile à comprendre.
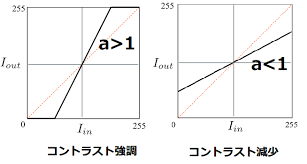
#Génération de table de recherche
min_table = 50
max_table = 205
diff_table = max_table - min_table
LUT_HC = np.arange(256, dtype = 'uint8' )
LUT_LC = np.arange(256, dtype = 'uint8' )
#Création de LUT à contraste élevé
for i in range(0, min_table):
LUT_HC[i] = 0
for i in range(min_table, max_table):
LUT_HC[i] = 255 * (i - min_table) / diff_table
for i in range(max_table, 255):
LUT_HC[i] = 255
#Créer une LUT à faible contraste
for i in range(256):
LUT_LC[i] = min_table + i * (diff_table) / 255
#conversion
src = cv2.imread("reni.jpg ", 1)
high_cont_img = cv2.LUT(src, LUT_HC)
low_cont_img = cv2.LUT(src, LUT_LC)
Contraste accentué

Contraste réduit

référence Conversion de la densité d'image avec la courbe des tons
Conversion gamma
Cette conversion est utilisée lors de l'affichage sur un écran et modifie la valeur de luminosité en fonction de la valeur de γ.
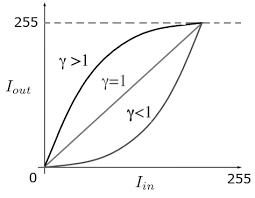
Remplacez ici la table de recherche de la source de réglage du contraste.
#Table de recherche de conversion gamma
gamma1 = 0.75
gamma2 = 1.5
for i in range(256):
LUT_G1[i] = 255 * pow(float(i) / 255, 1.0 / gamma1)
LUT_G2[i] = 255 * pow(float(i) / 255, 1.0 / gamma2)
Lorsque γ = 1,5

Lorsque γ = 0,75

référence Table de consultation (exemple de correction gamma)
Lissage
Lissez l'image. Ici, le filtre de moyennage est appliqué.
average_square = (10,10)
src = cv2.imread("reni.jpg ", 1)
blur_img = cv2.blur(src, average_square)
Filtre de moyenne 10x10

référence Filtre de lissage (moyenne mobile, gaussien)
Bruit basé sur la distribution gaussienne
Ajoutez du bruit à chaque pixel en ajoutant la valeur générée basée sur la distribution gaussienne.
Bruit gaussien avec σ = 15

src = cv2.imread("reni.jpg ", 1)
row,col,ch= src.shape
mean = 0
sigma = 15
gauss = np.random.normal(mean,sigma,(row,col,ch))
gauss = gauss.reshape(row,col,ch)
gauss_img = src + gauss
référence Conversion des informations d'image (données de luminosité)
Bruit sel et poivre
Ça s'appelle ça parce que c'est un bruit comme du sel et du poivre. Il est également appelé bruit impulsionnel.
src = cv2.imread("reni.jpg ", 1)
row,col,ch = src.shape
s_vs_p = 0.5
amount = 0.004
sp_img = src.copy()
#Mode sel
num_salt = np.ceil(amount * src.size * s_vs_p)
coords = [np.random.randint(0, i-1 , int(num_salt)) for i in src.shape]
sp_img[coords[:-1]] = (255,255,255)
#Mode poivre
num_pepper = np.ceil(amount* src.size * (1. - s_vs_p))
coords = [np.random.randint(0, i-1 , int(num_pepper)) for i in src.shape]
sp_img[coords[:-1]] = (0,0,0)
Bruit sur 0,4% de pixels

Inverser
Retourner à gauche et à droite et retourner de haut en bas.
src = cv2.imread("reni.jpg ", 1)
hflip_img = cv2.flip(src, 1)
vflip_img = cv2.flip(src, 0)
Échelle
Agrandit ou réduit une partie de l'image.
src = cv2.imread("reni.jpg ", 1)
hight = src.shape[0]
width = src.shape[1]
half_img = cv2.resize(src,(hight/2,width/2))
Recommended Posts