[PYTHON] Comparaison d'exemples d'implémentation de k-means de scikit-learn et pyclustering
introduction
La norme de facto pour la mise en œuvre de l'apprentissage automatique en Python est scikit-learn, mais le pyclustering est une option car certaines des parties qui démangent du clustering sont hors de portée.
Cependant, le pyclustering est un peu difficile à utiliser par rapport à scicit-learn, donc pour vous rappeler comment l'utiliser, nous résumerons les exemples d'implémentation les plus basiques dans k-means.
Exemple d'exécution de K-means
Des données d'utilisation
Définition des données
from sklearn.datasets import make_blobs
X, _ = make_blobs(n_features=2, centers=5, random_state=1)
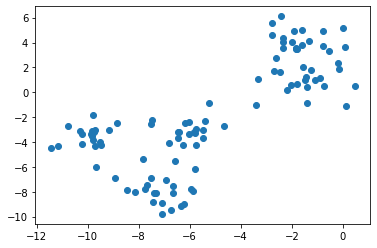
Nuage de points
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1])
scikit-learn
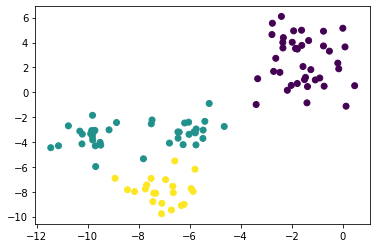
La mise en œuvre de k-means en utilisant scikit-learn est la suivante.
La méthode de définition de la valeur initiale dans scikit-learn peut être définie avec l'option ʻinit`, et ha par défaut. C'est k-means ++.
scikit-k en apprendre-means
from sklearn.cluster import KMeans
sk_km = KMeans(n_clusters=3).fit(X)
plt.scatter(X[:, 0], X[:, 1], c=sk_km.labels_)
pyclustering
La mise en œuvre de k-means utilisant le pyclustering est la suivante.
Contrairement à scikit-learn, il est nécessaire de spécifier séparément le paramètre de valeur initiale et l'apprentissage du cluster suivant. Plus tard, si vous utilisez la fonction de visualisation fournie ici, les informations seront un peu plus riches.
from pyclustering.cluster import kmeans
from pyclustering.cluster.center_initializer import kmeans_plusplus_initializer
initial_centers = kmeans_plusplus_initializer(X, 3).initialize() # k-means++Réglage de la valeur initiale avec
pc_km = kmeans.kmeans(X, initial_centers) #définition de la classe kmeans
pc_km.process() #Exécution de l'apprentissage
_ = kmeans.kmeans_visualizer.show_clusters(X, pc_km.get_clusters(), pc_km.get_centers(), initial_centers=initial_centers) #Visualisation
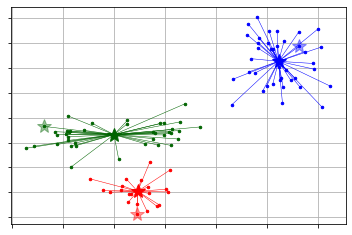
Les clusters obtenus par pyclustering peuvent être référencés avec les méthodes predict et get_clusters.
predire renvoie une étiquette pour les données d'entrée, similaire à scicit-learn.
get_clusters renvoie l'index des données utilisées pour l'entraînement par cluster. Cela ne convient pas à la manipulation de pandas, etc., il doit donc être traité séparément. (Plus facile à utiliser prédire)
Obtention du numéro de cluster à l'aide de Predict(1)
labels = pc_km.predict(X)
get_Obtention du numéro de cluster à l'aide de clusters
import numpy as np
clusters = pc_km.get_clusters()
labels = np.zeros((np.concatenate([np.array(x) for x in clusters]).size, ))
for i, label_index in enumerate(clusters):
labels[label_index] = i
Déterminer le nombre de clusters
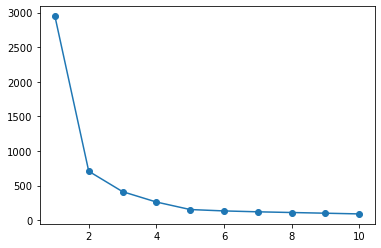
scikit-learn
La méthode du coude dans scikit-learn est affichée.
L'analyse de silhouette est également possible, mais elle sera omise car l'implémentation sera compliquée comme le pyclustering.
Dans les deux cas, le nombre de clusters ne peut pas être déterminé automatiquement et doit être déterminé après confirmation par l'analyste.
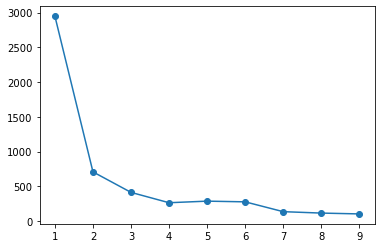
Méthode du coude
sse = list()
for i in range(1, 11):
km = KMeans(n_clusters=i).fit(X)
sse.append(km.inertia_)
plt.plot(range(1, 11), sse, 'o-')
pyclustering
Dans le cas du pyclustering, la méthode du coude détermine même le nombre de clusters. Quant au nombre de clusters, il semble que le nombre de clusters dans lesquels la somme des erreurs quadratiques dans le cluster est fortement réduite dans la plage de recherche soit adopté.
Méthode du coude
from pyclustering.cluster.elbow import elbow
kmin, kmax = 1, 10 #Plage de valeurs à rechercher
elb = elbow(X, kmin=kmin, kmax=kmax) #La plage de recherche est kmin~kmax-Notez jusqu'à 1
elb.process()
elb.get_amount() #Vous pouvez voir le nombre de clusters
plt.plot(range(kmin, kmax), elb.get_wce())
Étant donné que le pyclustering prend en charge x-means et g-means, vous pouvez également l'utiliser.
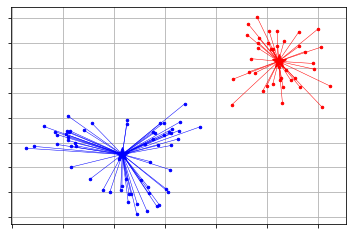
x-means
from pyclustering.cluster import xmeans
from pyclustering.cluster.kmeans import kmeans_visualizer
initial_centers = xmeans.kmeans_plusplus_initializer(X, 2).initialize() # k=Rechercher avec 2 ou plus
xm = xmeans.xmeans(X, initial_centers=initial_centers, )
xm.process()
_ = kmeans_visualizer.show_clusters(X, xm.get_clusters(), xm.get_centers())
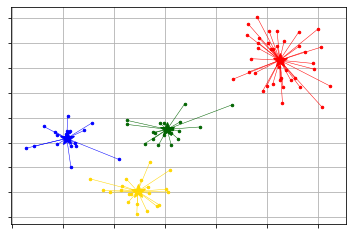
g-means
from pyclustering.cluster import gmeans
from pyclustering.cluster.kmeans import kmeans_visualizer
initial_centers = gmeans.kmeans_plusplus_initializer(X, 2).initialize()
gm = gmeans.gmeans(X, initial_centers=initial_centers, )
gm.process()
_ = kmeans_visualizer.show_clusters(X, gm.get_clusters(), gm.get_centers())
Avantages du pyclustering par rapport à scikit-learn
Scikit-learn est le meilleur choix pour les seuils bas, mais le pyclustering est supérieur si vous souhaitez affiner l'algorithme de clustering.
De nombreux algorithmes prenant en charge le pyclustering sont pris en charge en premier lieu, et le contenu de traitement peut être défini en détail. Par exemple, la définition de distance peut être modifiée de la distance euclidienne à la distance de Manhattan ou à l'index de distance défini par l'utilisateur.
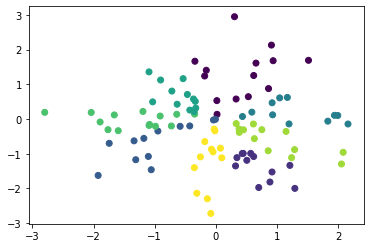
Ce qui suit est un exemple de réalisation de phosphore d'amas à la distance cosinus.
- Spherecluster est plus facile si vous le faites simplement à la distance cosinus.
Distance cosinus k-means
import numpy as np
from pyclustering.cluster import kmeans
from pyclustering.cluster.center_initializer import kmeans_plusplus_initializer
from pyclustering.utils.metric import distance_metric, type_metric
X = np.random.normal(size=(100, 2))
def cosine_distance(x1, x2):
if len(x1.shape) == 1:
return 1 - np.dot(x1, x2) / (np.linalg.norm(x1) * np.linalg.norm(x2))
else:
return 1 - np.sum(np.multiply(x1, x2), axis=1) / (np.linalg.norm(x1, axis=1) * np.linalg.norm(x2, axis=1))
initial_centers = kmeans_plusplus_initializer(X, 8).initialize()
pc_km = kmeans.kmeans(X, initial_centers, metric=distance_metric(type_metric.USER_DEFINED, func=cosine_distance))
pc_km.process()
plt.scatter(X[:, 0], X[:, 1], c=pc_km.predict(X))
référence
- Enveloppez une partie de xmeans de pyclustering comme sklearn
- Comment trouver le nombre optimal de clusters pour k-means
- Selecting the number of clusters with silhouette analysis on KMeans clustering — scikit-learn 0.22.2 documentation
- pyclustering.cluster.elbow.elbow Class Reference
- Clustering G-means qui détermine automatiquement le nombre de clusters
Recommended Posts