Exercice pratique d'analyse de données avec Python ~ 2016 New Coder Survey Edition ~
introduction
Entraînez-vous à travailler avec des données à l'aide de bibliothèques telles que python et numpy, pandas, seaborn. Les données utilisent les données de kaggle. Cette fois, nous utiliserons les données de 2016 New Coder Survey. Le contenu des données est le suivant. En termes simples, ce sont des données sur qui apprend à coder.
Free Code Camp is an open source community where you learn to code and build projects for nonprofits.
CodeNewbie.org is the most supportive community of people learning to code.
Together, we surveyed more than 15,000 people who are actively learning to code. We reached them through the twitter accounts and email lists of various organizations that help people learn to code.
Our goal was to understand these people's motivations in learning to code, how they're learning to code, their demographics, and their socioeconomic background.
De plus, comme prémisse, il est exécuté sur un notebook ipython. La version est pyenv: anaconda3-2.4.0 (Python 3.5.2 :: Anaconda 2.4.0) est.
Si vous connaissez ce domaine, nous vous serions reconnaissants si vous pouviez jeter un coup d'œil chaleureux au contenu et nous donner quelques conseils si vous remarquez quelque chose. Je vous serais reconnaissant si vous pouviez commenter quelque chose comme "Je ferais ce genre d'analyse si j'utilisais ces données"! (Ce sera utile si vous pouvez utiliser la base de code!)
Import de bibliothèque
Je chargerai ceux que je pense utiliser.
import numpy as np
from numpy.random import randn
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Lire les données
J'ai téléchargé les données de 2016 New Coder Survey et les ai placées dans le même dossier avec le nom "code_survey.csv".
survey_df = pd.read_csv('corder_survey.csv')
Aperçu des données
shape
survey_df.shape
(15620, 113)
Je vois. Il y a pas mal d'articles. Le nombre de lignes est de 15620 (le nombre de personnes ciblées pour les données) et le nombre de colonnes (éléments de réponse) est de 113.
info Vous pouvez également utiliser les informations.
survey_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 15620 entries, 0 to 15619
Columns: 113 entries, Age to StudentDebtOwe
dtypes: float64(85), object(28)
memory usage: 13.5+ MB
describe
survey_df.describe()
Vous pouvez voir des informations telles que «compte», «moyenne», «std», «min», «25%», «50%», «75%» et «max» dans chaque colonne. Les données sont omises car il y a trop de données.
Vérification de la colonne
for col in survey_df.columns:
print(col)
Maintenant, j'ai affiché les 113 éléments. Puisqu'il s'agit d'une pratique, je vais choisir les colonnes à utiliser en premier.
Gender:sexe
HasChildren:Avec ou sans enfants
EmploymentStatus:Formulaire d'emploi actuel
Age:âge
Income:le revenu
HoursLearning:Temps d'étude
SchoolMajor:Majeur
Aperçu de chaque article
Gender
countplot
Commençons par les données de genre. Faisons un histogramme. le graphique de comptage Seaborn est utile.
sns.countplot('Gender', data=survey_df)

Au Japon, il semble que les hommes et les femmes sont divisés, mais il y a de la diversité et cela semble être à l'étranger.
Au fait, pour un histogramme simple, il y a «plt.hist» dans matplotlib. (Il y a aussi «plt.bar» qui fait un graphique à barres, mais «plt.hist» est facile quand on crée un histogramme à partir de la distribution de fréquence des données.
dataset = randn(100)
plt.hist(dataset)
(Randn générera des nombres aléatoires selon la distribution normale)

Il existe également diverses options.
# normed:Normalisation, alpha:Transparence, color:Couleur, bins:Nombre de bacs
plt.hist(dataset, normed=True, alpha=0.8, color='indianred', bins=15)
HasChildren
De même, essayez de dessiner avec ou sans enfants en utilisant count plot.
sns.countplot('HasChildren', data=survey_df)
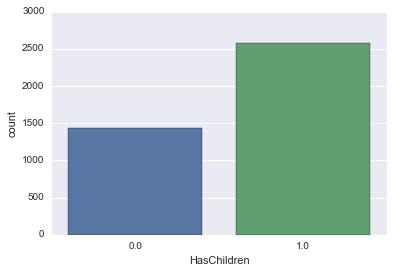
Si c'est 0 ou 1, c'est difficile à comprendre, alors disons "Non" sans enfants et "Oui" avec les enfants.
survey_df['HasChildren'].loc[survey_df['HasChildren'] == 0] = 'No'
survey_df['HasChildren'].loc[survey_df['HasChildren'] == 1] = 'Yes'
Vous pouvez maintenant convertir.
df.map
La conversion à l'aide de la carte semble être bonne.
survey_df['HasChildren'] = survey_df['HasChildren'].map({0: 'No', 1: 'Yes'})
sns.countplot('HasChildren', data=survey_df)
sns.countplot('HasChildren', data=survey_df)

C'est un peu plus facile à comprendre!
EmploymentStatus
J'exprimerai également le formulaire d'emploi actuel avec count plot.
sns.countplot('EmploymentStatus', data=survey_df)

C'est un peu compliqué et difficile à comprendre. ..
Alors changeons d'axe.
countplot Changement d'axe
sns.countplot(y='EmploymentStatus', data=survey_df)
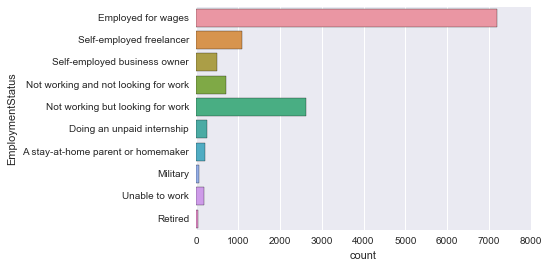
Facile à voir!
Age
Encore une fois, essayez d'utiliser count plot.
sns.countplot('Age', data=survey_df)

C'est coloré et beau, mais c'est difficile à voir sous forme de graphique.
Alors lissons le graphique.
kde plot
Utilisez l'estimation de la densité du noyau (kde: graphe de densité du noyau). La méthode elle-même est simple.
sns.kdeplot(survey_df['Age'])

Il y a beaucoup de gens dans la vingtaine et la trentaine. Est-ce exactement ce que vous attendez? Cependant, l'ourlet s'élargit même si vous vieillissez dans une certaine mesure.
Estimation de la densité du noyau
Considérons maintenant une petite estimation de la densité du noyau. (Si vous regardez Wikipédia et d'autres sites, vous pouvez voir une explication appropriée.) [Estimation de la densité du noyau](https://ja.wikipedia.org/wiki/%E3%82%AB%E3%83%BC%E3%83%8D%E3%83%AB%E5%AF%86%E5 % BA% A6% E6% 8E% A8% E5% AE% 9A)
dataset = randn(30)
plt.hist(dataset, alpha=0.5)
sns.rugplot(dataset)
Le tracé du tapis montre chaque point d'échantillonnage avec une barre.

Ceci est une image de la création d'une fonction de noyau (qui est facile à comprendre si vous considérez une distribution normale comme exemple) pour chaque point d'échantillonnage de ce graphique et de les additionner.
sns.kdeplot(dataset)
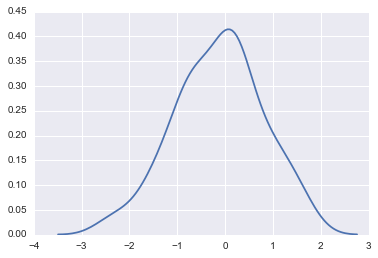
Lors de l'estimation de la densité du noyau
- Fonction noyau: comment répartir l'influence de chaque point d'échantillonnage --Bandwidth: largeur de diffusion des fonctions du noyau
Vous devez décider de deux choses.
Fonction noyau
Vous pouvez également utiliser diverses fonctions du noyau. La valeur par défaut est gau (distribution gaussienne, distribution normale).
kernel_options = ["gau", "biw", "cos", "epa", "tri", "triw"]
for kernel in kernel_options:
sns.kdeplot(dataset, kernel=kernel, label=kernel)

Bande passante
La largeur de bande peut également être modifiée.
for bw in np.arange(0.5, 2, 0.25):
sns.kdeplot(dataset, bw=bw, label=bw)

Jusqu'à présent, l'explication de l'estimation de la densité du noyau sera séparée une fois, puis elle sera poursuivie.
Income
Encore une fois, utilisez kdeplot.
sns.kdeplot(survey_df['Income'])

L'unité est en dollars, donc c'est un revenu annuel.
Examinons de plus près les données.
describe
survey_df['Income'].describe()
RuntimeWarning: Invalid value encountered in median
count 7329.000000
mean 44930.010506
std 35582.783216
min 6000.000000
25% NaN
50% NaN
75% NaN
max 200000.000000
Name: Income, dtype: float64
Il semble que le problème que le quadrant devienne NaN ait déjà été résolu au moment de la rédaction de l'article, mais il semble attendre la fusion. Attendez la mise à jour de la version sans vous en soucier. describe() returns RuntimeWarning: Invalid value encountered in median RuntimeWarning #13146
boxplot
Je voudrais créer un boxplot (boxplot).
sns.boxplot(survey['Income'])

À partir de la ligne verticale sur la gauche, les moustaches de boîte minimum, le premier quadrant (Q1), la valeur médiane, le troisième quadrant (Q3) et les moustaches de boîte maximum sont affichés. Si IQR = Q3-Q1 et s'écarte de (valeur minimale --IQR1.5) ~ (valeur maximale + IQR1.5), il est représenté par un point noir comme une valeur différente des moustaches de la boîte.
Il est également possible d'exprimer sans valeurs aberrantes.
sns.boxplot(survey['Income'], whips=np.inf)

violinplot
Il existe également un diagramme de Vaviolin qui donne des informations sur la boîte à moustaches sur kde.
sns.violinplot(survey_df['Income'])

La distribution est plus simple à comprendre!
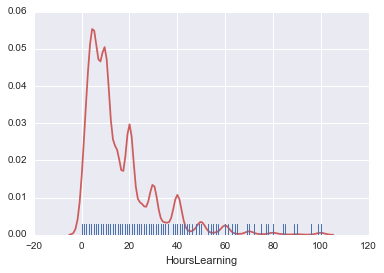
HoursLearning
Jetons un œil au temps d'étude. Commençons par faire un tracé kde.
sns.kdeplot(survey_df['HoursLearning'])

C'est la quantité d'apprentissage par semaine en termes de temps. Les extrêmes sont également perceptibles, mais cela se produit avec de bons chiffres. Normalement, je réponds au questionnaire avec un bon nombre, alors cela se produit.
J'ai aussi une parcelle de violon.
sns.violinplot(survey_df['HoursLearning'])

Il reflète les caractéristiques du graphique kde.
Il existe également un «distplot» qui peut générer à la fois «countplot» et «kdeplot» ensemble. «nan» est supprimé et utilisé.
hours_learning = survey_df['HoursLearning']
hours_learning = hours_learning.dropna()
sns.distplot(hours_learning)
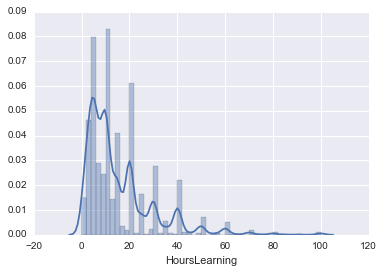
Vous pouvez transformer l'histogramme en un graphique de décalage et ajouter des options. Pratique!
sns.distplot(hours_learning, rug=True, hist=False, kde_kws={'color':'indianred'})
SchoolMajor
S'il s'agit d'une valeur continue, kdeplot sera utile, mais comme il s'agit d'une catégorisation, utilisez countplot.
sns.countplot(y='SchoolMajor' , data=survey_df)
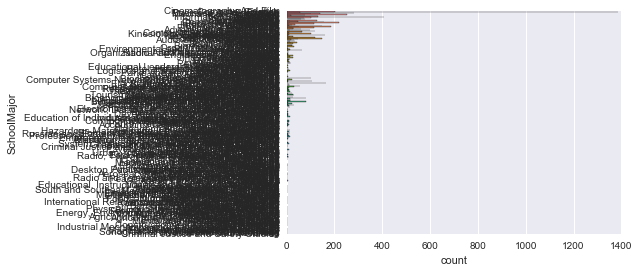
C'est difficile à voir. .. Il y a trop de catégories. Je veux voir le top 10 environ.
collections.Counter
from collections import Counter
major_count = Counter(survey_df['SchoolMajor'])
major_count.most_common(10)
Comptez en utilisant la bibliothèque standard collections.
De plus, en définissant most_common (10), vous pouvez obtenir le top 10 d'entre eux.
[(nan, 7170),
('Computer Science', 1387),
('Information Technology', 408),
('Business Administration', 284),
('Economics', 252),
('Electrical Engineering', 220),
('English', 204),
('Psychology', 187),
('Electrical and Electronics Engineering', 164),
('Software Engineering', 159)]
Affichons-le sur le graphique.
X = []
Y = []
major_count_top10 = major_count.most_common(10)
for record in major_count_top10:
X.append(record[0])
Y.append(record[1])
# [nan, 'Computer Science', 'Information Technology', 'Business Administration', 'Economics', 'Electrical Engineering', 'English', 'Psychology', 'Electrical and Electronics Engineering', 'Software Engineering']
# [7170, 1387, 408, 284, 252, 220, 204, 187, 164, 159]
plt.barh(np.arange(10), Y)
plt.yticks(np.arange(10), X)
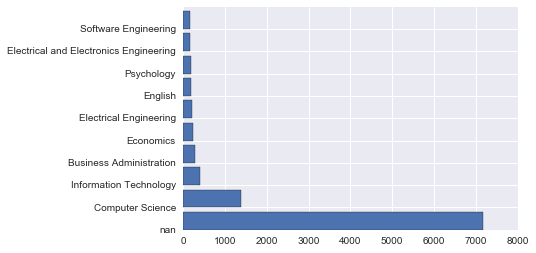
Je l'ai mentionné ici. Graphique à barres - Introduction à matplotlib
Vous pouvez utiliser plt.barh pour changer l'axe de plt.bar. Je l'ai également étiqueté avec «yticks».
Eh bien, je ne veux pas afficher nan, et je veux le trier dans l'ordre inverse.
X = []
Y = []
major_count_top10 = major_count.most_common(10)
major_count_top10.reverse()
for record in major_count_top10:
# record[0] == record[0]Il y a un supplément ci-dessous
if record[0] == record[0]:
X.append(record[0])
Y.append(record[1])
# ['Software Engineering', 'Electrical and Electronics Engineering', 'Psychology', 'English', 'Electrical Engineering', 'Economics', 'Business Administration', 'Information Technology', 'Computer Science']
# [159, 164, 187, 204, 220, 252, 284, 408, 1387]
plt.barh(np.arange(9), Y)
plt.yticks(np.arange(9), X)

Le graphique auquel je pensais a été créé!
[Ajout] about if record [0] == record [0]:
Ici, nous avons implémenté cela car «False» n'est renvoyé que lors de la comparaison de «NaN». (Voir aussi l'URL ci-dessous)
Cependant, il est difficile de comprendre La méthode d'implémentation introduite par @shiracamus est plus facile à comprendre. J'utiliserai cela à l'avenir également.
if record[0] == record[0]:
Changé la pièce comme suit.
if pd.notnull(record[0]):
Association de données
Sexe et enfants
Premièrement, le genre n'est réservé aux hommes et aux femmes que par souci de simplicité.
male_female_df = survey_df.where((survey_df['Gender'] == 'male') + (survey_df['Gender'] == 'female') )
Vous pouvez compter par couche en utilisant hue of count plot.
countplot(hue)
sns.countplot('Gender', data=male_female_df, hue='HasChildren')
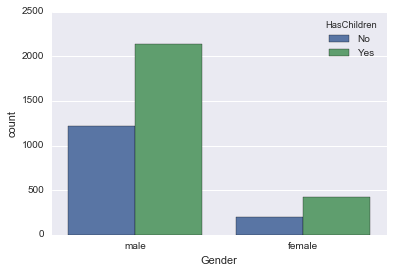
Il semble que les hommes et les femmes aient la même proportion d'enfants.
Sexe et âge
Les graphiques autres que "count plot" peuvent également être représentés par des couches. Utilisez FacetGrid.
sns.FacetGrid
fig = sns.FacetGrid(male_female_df, hue='Gender', aspect=4)
fig.map(sns.kdeplot, 'Age', shade=True)
oldest = male_female_df['Age'].max()
fig.set(xlim=(0, oldest))
fig.add_legend()

Les hommes sont un peu plus jeunes, n'est-ce pas?
EmploiStatut et sexe
Puisqu'il y a plusieurs statuts d'emploi, je voudrais n'utiliser que les quelques premiers.
# male_female_df est une enquête_df Genre réduit aux hommes et aux femmes
#Obtenez le top 5 des statuts d'emploi
from collections import Counter
employ_count = Counter(male_female_df['EmploymentStatus'])
employ_count_top = employ_count.most_common(5)
print(employ_count_top)
employ_list =[]
for record in employ_count_top:
if record[0] == record[0]:
employ_list.append(record[0])
def top_employ(status):
return status in employ_list
#appliquer en utilisant appliquer_Récupérer uniquement les lignes d'éléments de la liste
new_survey_df = male_female_df.loc[male_female_df['EmploymentStatus'].apply(top_employ)]
sns.countplot(y='EmploymentStatus', data=new_survey_df)

Maintenant, il n'y a que les 3 premiers éléments.
Regardons la stratification du genre en utilisant la teinte count plot.
sns.countplot(y='EmploymentStatus', data=employ_df, hue='Gender')
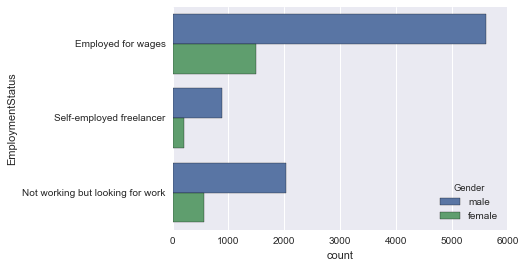
EmploiStatut et aEnfants
Tout d'abord, convertissez HasChildren en Non-> 0, Oui-> 1.
new_survey_df['HasChildren'] = new_survey_df['HasChildren'].map({'No': 0, 'Yes': 1})
Utilisez ici le factor plot. Voyons comment le statut d'emploi est lié à la présence ou à l'absence d'enfants.
factorplot
sns.factorplot('EmploymentStatus', 'HasChildren', data=new_survey_df, aspect=2)

«Emloyed pour les salaires» est un peu élevé. C'est convaincant.
Vous pouvez également voir les graphiques des facteurs par couche, alors voyons s'il y a une différence entre les hommes et les femmes.
sns.factorplot('EmploymentStatus', 'HasChildren', data=new_survey_df, aspect=2, hue='Gender')

C'est assez intéressant. En fait, c'était complètement différent pour les hommes et les femmes. Il semble que diverses choses peuvent être envisagées à la lumière de la situation de l'emploi.
Âge et enfants
lmplot
J'aimerais voir la relation avec une droite de régression. Utilisez lmplot pour la ligne de régression.
sns.lmplot('Age', 'HasChildren', data=new_survey_df)

Au fait, lmplot peut également être vu par couche, alors j'aimerais l'essayer.
Commencez par stratifier par «Statut d’emploi».
sns.lmplot('Age', 'HasChildren', data=new_survey_df, hue='EmploymentStatus')
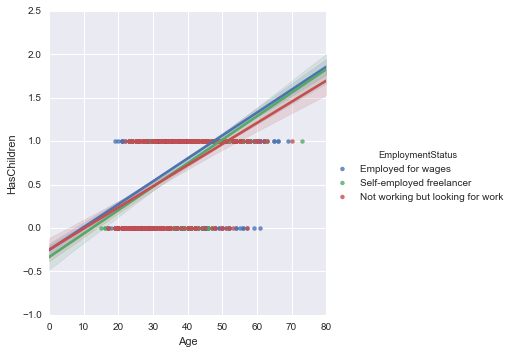
En général, la valeur de «Employé contre rémunération» est un peu élevée, mais comme vous l'avez vu dans la section précédente, il semble que ce sera un peu plus clair si vous la divisez par sexe.
À propos, même le «genre» est superposé.
sns.lmplot('Age', 'HasChildren', data=new_survey_df, hue='Gender')

Afficher plusieurs graphiques côte à côte
Vous pouvez également afficher plusieurs graphiques côte à côte. J'ai dessiné deux graphiques en utilisant des «sous-graphiques».
fig, (axis1, axis2) = plt.subplots(1, 2, sharey=True)
sns.regplot('HasChildren', 'Age', data=new_survey_df, ax=axis1)
sns.violinplot(y='Age', x='HasChildren', data=new_survey_df, ax=axis2)

regplot est une version de bas niveau de lmplot, qui est la même chose pour faire des régressions simples.
J'ai utilisé regplots parce que les fonctions qui peuvent être utilisées avec sous-tracés semblent être limitées à celles qui renvoient un objet matplotlib Axes, et lmplot ne pouvait pas être utilisé.
Explication détaillée Plotting with seaborn using the matplotlib object-oriented interface C'était facile à comprendre.
Il semble que la fonction «au niveau de l'axe» mentionnée dans cet article puisse être utilisée. (regplot, boxplot, kdeplot, and many others)
D'un autre côté, la fonction "au niveau de la figure" est également introduite, et il y a aussi "lmplot" dedans. (lmplot, factorplot, jointplot and one or two others)
C'est presque «Axis» et en partie comme «Figure».
Il semble donc que «FacetGrid» soit bon pour les chiffres. Plotting on data-aware grids
Vous pouvez également organiser plusieurs graphiques avec FacetGrid.
J'ai essayé d'afficher la distribution de l'âge côte à côte par EmploymentStatus.
fig = sns.FacetGrid(new_survey_df, col='EmploymentStatus', aspect=1.5)
fig.map(sns.distplot, 'Age')
oldest = new_survey_df['Age'].max()
fig.set(xlim=(0, oldest))
fig.add_legend()

en conclusion
Organisez ce qui sort
- df.shape
- df.info()
- df.describe()
- df.read_csv
- sns.countplot
- plt.hist
- plt.bar
- sns.kdeplot
- df.loc
- df.map
- sns.rugplot
- sns.boxplot
- sns.violinplot
- sns.distplot
- collections.Counter
- collections.Counter.most_common
- plt.barh
- pd.where
- sns.countplot(hue)
- sns.FacetGrid
- df.apply
- sns.lmplot
- sns.lmplot(hue)
- plt.subplots
Référencé dans l'utilisation de python
Mieux écrire que je voulais savoir depuis que j'ai commencé Python Processus de sélection des données des pandas Python plus en détail <Partie 2>
référence
[20 000 personnes dans le monde] Science des données Python pratique Il s'agit d'un cours vidéo recommandé qui est facile à comprendre avec des explications détaillées. Le fait est que même si vous posez une question, la réponse vous sera renvoyée le lendemain.
[Introduction à l'analyse des données par Python-Traitement des données à l'aide de NumPy et pandas](https://www.amazon.co.jp/Python%E3%81%AB%E3%82%88%E3%82%8B%E3 % 83% 87% E3% 83% BC% E3% 82% BF% E5% 88% 86% E6% 9E% 90% E5% 85% A5% E9% 96% 80-% E2% 80% 95NumPy% E3% 80% 81pandas% E3% 82% 92% E4% BD% BF% E3% 81% A3% E3% 81% 9F% E3% 83% 87% E3% 83% BC% E3% 82% BF% E5% 87% A6% E7% 90% 86-Wes-McKinney / dp / 4873116554) Livre d'analyse des données d'O'Reilly. C'est bien organisé.
Start Python Club La communauté Python. Je ne suis pas spécialisé dans l'analyse de données, mais je suis actif dans une large gamme de Python, donc si vous utilisez Python, je pense que c'est amusant d'y aller.
Recommended Posts