Il s'agit d'une formation pour devenir un data scientist en utilisant Python.
Enfin, faisons les Pandas, l'un des trois trésors sacrés.
Pandas est le package d'analyse de données le plus puissant de Python.
C'est très pratique car vous pouvez faire tout ce que vous pouvez faire avec Excel. (Vous pouvez faire des choses qu'Excel ne peut pas faire)
Il va bien avec numpy et matplotlib et peut être utilisé de manière transparente.
Je pense qu'il est préférable d'utiliser le notebook IPython décrit ci-dessous pour exécuter des programmes Python à l'aide de Pandas.
** PREV ** → [Python] Road to the Serpent (5) Play with Matplotlib
** SUIVANT ** → Application de Pandas (dès que possible)
Il visualise magnifiquement les DataFrames et les graphiques comme celui-ci. incroyable.
Structure de données Pandas
Pandas a trois structures de données.
- Tableau unidimensionnel: Série
- Tableau à deux dimensions: DataFrame
- Tableau en trois dimensions: panneau
Générons-les à partir du tableau de Numpy.
Exemple de série (1D)
Python
import numpy as np
import pandas as pd
Python
# Series
a1 = np.arange(2)
idx = pd.Index(['A', 'B'], name = 'index')
series = pd.Series(a1, index=idx)
series
index
A 0
B 1
dtype: int64
Exemple de DataFrame (2D)
Python
# DataFrame
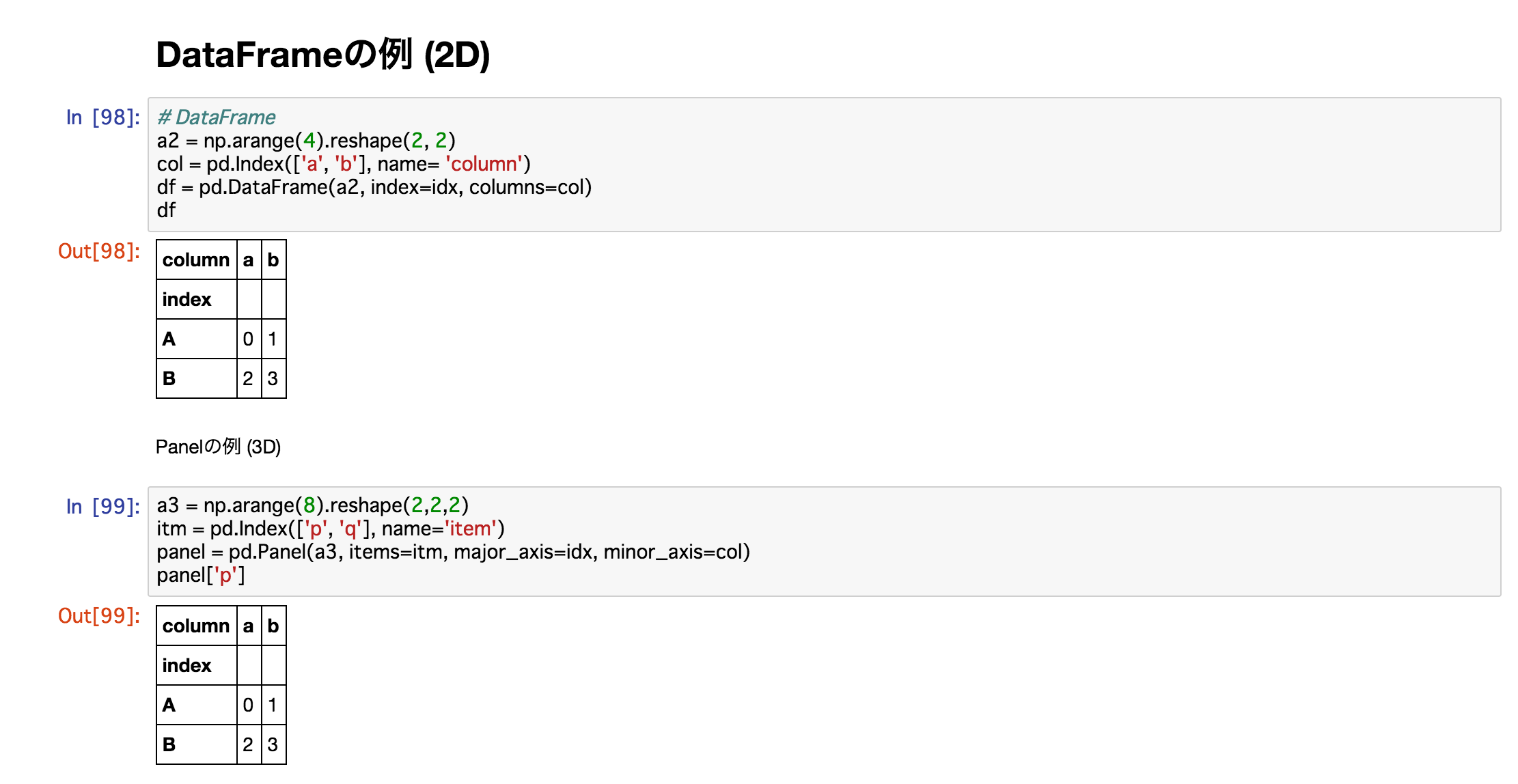
a2 = np.arange(4).reshape(2, 2)
col = pd.Index(['a', 'b'], name= 'column')
df = pd.DataFrame(a2, index=idx, columns=col)
df
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Exemple de panneau (3D)
Python
a3 = np.arange(8).reshape(2,2,2)
itm = pd.Index(['p', 'q'], name='item')
panel = pd.Panel(a3, items=itm, major_axis=idx, minor_axis=col)
panel['p']
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Python
panel['q']
| column |
a |
b |
| index |
|
|
| A |
4 |
5 |
| B |
6 |
7 |
Exemple de série à double index (effectivement 2D)
Python
a1=np.arange(4)
idx = pd.MultiIndex.from_product([['A','B'],['a','b']], names=('i','j'))
series2 = pd.Series(a1, index=idx)
series2
#De même si la multiplicité des axes est de 3 ou plus_le produit peut être utilisé.
# pd.MultiIndex.from_product([['A', 'B'],['a', 'b'],['1', '2']], names=('i', 'j', 'k'))
i j
A a 0
b 1
B a 2
b 3
dtype: int64
Exemple de DataFrame avec double index (effectivement 4D)
Python
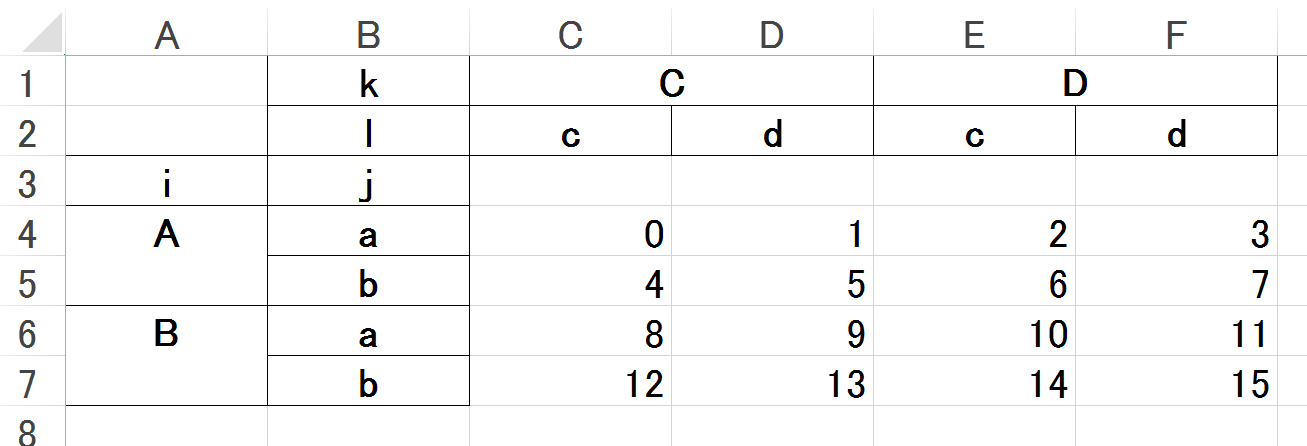
a2 = np.arange(16) .reshape(4,4)
idx = pd.MultiIndex.from_product( [['A','B'],['a','b']], names=('i','j'))
col = pd.MultiIndex.from_product( [['C','D'],['c','d']], names=('k','l'))
df = pd.DataFrame(a2, index=idx, columns=col)
df
|
k |
C |
D |
|
l |
c |
d |
c |
d |
| i |
j |
|
|
|
|
| A |
a |
0 |
1 |
2 |
3 |
| b |
4 |
5 |
6 |
7 |
| B |
a |
8 |
9 |
10 |
11 |
| b |
12 |
13 |
14 |
15 |
Bien que cette fois omis, Panel peut également avoir plusieurs index de la même manière.
Comment accéder aux données (indexation)
La grande différence entre Pandas et Numpy est que le concept d'index de Numpy est plus sophistiqué dans Pandas.
Comparons le tableau bidimensionnel précédent avec Numpy et Pandas DataFrame.
Python
a2 = np.arange(4).reshape(2, 2)
a2
array([[0, 1],
[2, 3]])
Python
idx = pd.Index(['A', 'B'], name='index')
col = pd.Index(['a', 'b'], name='column')
df = pd.DataFrame(a2, index=idx, columns=col)
df
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Les lignes sont étiquetées A et B et les colonnes sont étiquetées a et b, respectivement, que les Pandas peuvent utiliser comme index.
C'est ce qu'on appelle l '** index basé sur les étiquettes **.
Par contre, l'indice des entiers à partir de 0 utilisé dans Numpy est appelé ** index basé sur la position **.
Les deux sont disponibles dans Pandas.
Python
a2[1, 1]
3
Python
df.ix[1, 1]
3
Python
df.ix['B', 'b']
3
Puisque ** index basé sur l'étiquette ** est la clé de dict et ** index basé sur la position ** est l'index de la liste, on peut considérer que Pandas a à la fois des propriétés dict et list. Je peux le faire.
Ainsi, bien sûr, les tranches, l'indexation sophistiquée et l'indexation booléenne sont possibles ainsi que Numpy.
slice
Python
df = pd.DataFrame( np.arange(16).reshape(4, 4), index=list('ABCD'),columns=list('abcd'))
df
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
| D |
12 |
13 |
14 |
15 |
Python
#Première ligne et au-dessus,Moins de 3ème ligne
df.ix[1:3]
|
a |
b |
c |
d |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
Python
#Ligne A et plus,Ligne C et ci-dessous
# label-Pour un index basé, pas moins de
df.ix['A' : 'C']
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
fancy indexing
Python
#Spécifiez plusieurs lignes
df.ix[['A', 'B', 'D']]
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| B |
4 |
5 |
6 |
7 |
| D |
12 |
13 |
14 |
15 |
Python
#Spécifiez plusieurs colonnes
df[[ 'b', 'd']]
|
b |
d |
| A |
1 |
3 |
| B |
5 |
7 |
| C |
9 |
11 |
| D |
13 |
15 |
boolean indexing
Python
#Voir la ligne qui est vraie
df.ix[[True, False, True]]
|
a |
b |
c |
d |
| A |
0 |
1 |
2 |
3 |
| C |
8 |
9 |
10 |
11 |
Python
#Voir la colonne qui est True
df.ix[:,[True, False, True]]
|
a |
c |
| A |
0 |
2 |
| B |
4 |
6 |
| C |
8 |
10 |
| D |
12 |
14 |
Python
#Voir la ligne où deux fois la valeur a est supérieure à la valeur c
df.ix[df['a']*2 > df['c']]
|
a |
b |
c |
d |
| B |
4 |
5 |
6 |
7 |
| C |
8 |
9 |
10 |
11 |
| D |
12 |
13 |
14 |
15 |
Manipulation des axes et des index
Présentation de l'échange d'axes, du déplacement, du changement de nom d'index, du tri d'index, etc. qui sont importants pour l'utilisation de Pandas.
Permuter les axes
Python
a2 = np.arange(4) .reshape(2, 2)
idx = pd.Index(['A', 'B'], name='index')
col = pd.Index(['a', 'b'], name='column')
df = pd.DataFrame(a2, index=idx,columns=col)
df
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Python
#Axe 0(ligne)Et le premier axe(Colonne)Remplacer
df.swapaxes(0, 1)
| index |
A |
B |
| column |
|
|
| a |
0 |
2 |
| b |
1 |
3 |
Python
#Inversion pour 2D(T)Même si c'est pareil
df.T # transpose()Abréviation pour
| index |
A |
B |
| column |
|
|
| a |
0 |
2 |
| b |
1 |
3 |
Mouvement de l'axe (empiler / dépiler)
Python
#Colonne déplacée du côté de la ligne
df.stack()
index column
A a 0
b 1
B a 2
b 3
dtype: int64
Python
#La ligne se déplace vers le côté de la colonne
df.unstack()
column index
a A 0
B 2
b A 1
B 3
dtype: int64
Python
#stack()Et décompresser()Est-ce l'opération inverse, donc si vous répétez ces deux opérations, il reviendra à l'original
df.stack().unstack()
| column |
a |
b |
| index |
|
|
| A |
0 |
1 |
| B |
2 |
3 |
Lorsque la ligne se déplace vers le côté colonne, la colonne est représentée par un double index.
Si vous empilez () ou dépilez () un DataFrame (non multiplexé), la sortie sera Series pour les deux.
Permuter les axes
Python
a2 = np.arange(64).reshape(8,8)
idx = pd.MultiIndex.from_product( [['A','B'],['C','D'],['E','F']],names=list('ijk'))
col = pd.MultiIndex.from_product([['a','b'],['c','d'],['e','f']],names=list('xyz'))
df = pd.DataFrame(a2, index=idx,columns=col)
df
|
|
x |
a |
b |
|
|
y |
c |
d |
c |
d |
|
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
| i |
j |
k |
|
|
|
|
|
|
|
|
| A |
C |
E |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| F |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
| D |
E |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
| F |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
| B |
C |
E |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
| F |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
| D |
E |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
| F |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
Voici un exemple où chaque axe a 3 couches (3 couches), mais swapaxes () remplace toutes les couches entièrement.
Python
df.swapaxes(0,1)
|
|
i |
A |
B |
|
|
j |
C |
D |
C |
D |
|
|
k |
E |
F |
E |
F |
E |
F |
E |
F |
| x |
y |
z |
|
|
|
|
|
|
|
|
| a |
c |
e |
0 |
8 |
16 |
24 |
32 |
40 |
48 |
56 |
| f |
1 |
9 |
17 |
25 |
33 |
41 |
49 |
57 |
| d |
e |
2 |
10 |
18 |
26 |
34 |
42 |
50 |
58 |
| f |
3 |
11 |
19 |
27 |
35 |
43 |
51 |
59 |
| b |
c |
e |
4 |
12 |
20 |
28 |
36 |
44 |
52 |
60 |
| f |
5 |
13 |
21 |
29 |
37 |
45 |
53 |
61 |
| d |
e |
6 |
14 |
22 |
30 |
38 |
46 |
54 |
62 |
| f |
7 |
15 |
23 |
31 |
39 |
47 |
55 |
63 |
Permutation de plusieurs axes (swaplevel / reorder_levels)
Python
#Axe 0(ligne)De la 0ème couche(i)Et le deuxième niveau(z)Échanger
df.reorder_levels([2, 1, 0])
# swaplevel(0, 2)Ou swaplevel('i', 'z')Mais pareil
|
|
x |
a |
b |
|
|
y |
c |
d |
c |
d |
|
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
| k |
j |
i |
|
|
|
|
|
|
|
|
| E |
C |
A |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| F |
C |
A |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
| E |
D |
A |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
| F |
D |
A |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
| E |
C |
B |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
| F |
C |
B |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
| E |
D |
B |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
| F |
D |
B |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
Python
#1er axe(Colonne)De la 0ème couche(x)Et le premier niveau(y)Échanger
df.reorder_levels([1,0,2],axis=1)
# swaplevel(0, 1, axis=1)Ou swaplevel('i', 'j', axis=1)Mais pareil
|
|
y |
c |
d |
c |
d |
|
|
x |
a |
a |
b |
b |
|
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
| i |
j |
k |
|
|
|
|
|
|
|
|
| A |
C |
E |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| F |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
| D |
E |
16 |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
| F |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
31 |
| B |
C |
E |
32 |
33 |
34 |
35 |
36 |
37 |
38 |
39 |
| F |
40 |
41 |
42 |
43 |
44 |
45 |
46 |
47 |
| D |
E |
48 |
49 |
50 |
51 |
52 |
53 |
54 |
55 |
| F |
56 |
57 |
58 |
59 |
60 |
61 |
62 |
63 |
Mouvement multi-axes (empiler / dépiler)
stack () déplace l'axe de niveau inférieur de l'axe de colonne vers l'axe de niveau inférieur de l'axe de ligne.
Python
df.stack()
|
|
|
x |
a |
b |
|
|
|
y |
c |
d |
c |
d |
| i |
j |
k |
z |
|
|
|
|
| A |
C |
E |
e |
0 |
2 |
4 |
6 |
| f |
1 |
3 |
5 |
7 |
| F |
e |
8 |
10 |
12 |
14 |
| f |
9 |
11 |
13 |
15 |
| D |
E |
e |
16 |
18 |
20 |
22 |
| f |
17 |
19 |
21 |
23 |
| F |
e |
24 |
26 |
28 |
30 |
| f |
25 |
27 |
29 |
31 |
| B |
C |
E |
e |
32 |
34 |
36 |
38 |
| f |
33 |
35 |
37 |
39 |
| F |
e |
40 |
42 |
44 |
46 |
| f |
41 |
43 |
45 |
47 |
| D |
E |
e |
48 |
50 |
52 |
54 |
| f |
49 |
51 |
53 |
55 |
| F |
e |
56 |
58 |
60 |
62 |
| f |
57 |
59 |
61 |
63 |
unstack () déplace l'axe de niveau inférieur de l'axe de ligne vers l'axe de niveau inférieur de l'axe de colonne.
Python
df.unstack()
|
x |
a |
b |
|
y |
c |
d |
c |
d |
|
z |
e |
f |
e |
f |
e |
f |
e |
f |
|
k |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
E |
F |
| i |
j |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| A |
C |
0 |
8 |
1 |
9 |
2 |
10 |
3 |
11 |
4 |
12 |
5 |
13 |
6 |
14 |
7 |
15 |
| D |
16 |
24 |
17 |
25 |
18 |
26 |
19 |
27 |
20 |
28 |
21 |
29 |
22 |
30 |
23 |
31 |
| B |
C |
32 |
40 |
33 |
41 |
34 |
42 |
35 |
43 |
36 |
44 |
37 |
45 |
38 |
46 |
39 |
47 |
| D |
48 |
56 |
49 |
57 |
50 |
58 |
51 |
59 |
52 |
60 |
53 |
61 |
54 |
62 |
55 |
63 |
renommer l'index
Python
df = pd.DataFrame( [[90, 50], [60, 80]], index=['t', 'h'],columns=['m', 'e'])
df
Python
df.index.name='Nom'
df.columns.name='Matière'
df.rename(index=dict(t='Taro', h='Hanako'), columns=dict(m='Math', e='Anglais'))
| Sujets
| Mathématiques
| anglais
|
| Nom
| |
|
| Taro
| 90 |
50 |
| Hanako
| 60 |
80 |
Trier par index
Python
df = pd.DataFrame (np.arange(9).reshape(3,3), index=['B','A','C'], columns=['c','b','a'])
df
|
c |
b |
a |
| B |
0 |
1 |
2 |
| A |
3 |
4 |
5 |
| C |
6 |
7 |
8 |
Python
#Trier les lignes par index de ligne
df.sort_index(axis=0)
|
c |
b |
a |
| A |
3 |
4 |
5 |
| B |
0 |
1 |
2 |
| C |
6 |
7 |
8 |
Python
#Trier les colonnes par index de colonne
df.sort_index(axis=0).sort_index(axis=1)
|
a |
b |
c |
| A |
5 |
4 |
3 |
| B |
2 |
1 |
0 |
| C |
8 |
7 |
6 |
Conversion de données
Conversion de données en série
Python
series=pd.Series([2, 3], index=list('ab'))
series
a 2
b 3
dtype: int64
Python
#Mettre au carré chaque valeur de série
series ** 2
a 4
b 9
dtype: int64
Python
#Vous pouvez également passer des fonctions et des dictionnaires sur la carte
series.map(lambda x: x**2)
# series.map( {x:x**2 for x in range(3) })
a 4
b 9
dtype: int64
Conversion de données DataFrame
Python
df = pd.DataFrame( [[2, 3], [4, 5]], index=list('AB'),columns=list('ab'))
df
Python
#Similaire à la série
df ** 2
# df.map(lambda x: x**2)
Python
#une fonction(Series to scalar)Appliquer à chaque colonne
#Une dimension plus bas, le résultat est Série
df.apply(lambda c: c['A']*c['B'], axis=0)
a 8
b 15
dtype: int64
Python
#une fonction(Series to Series)Appliquer à chaque ligne
#Le résultat est un DataFrame
df.apply(lambda r: pd.Series(dict(a=r['a']+r['b'], b=r['a']*r['b'])), axis=1)
Concat et fusion
Pandas vous permet de concaténer et de combiner plusieurs séries et DataFrames.
Série concat (concat)
Même s'il existe des index en double, ils seront combinés tels quels.
Python
ser1=pd.Series([1,2], index=list('ab'))
ser2=pd.Series([3,4], index=list('bc'))
pd.concat([ser1, ser2])
a 1
b 2
b 3
c 4
dtype: int64
Python
#Lorsque vous rendez l'index unique, supprimez les doublons inex
dif_idx = ser2.index.difference(ser1.index)
pd.concat([ser1, ser2[list(dif_idx)]])
a 1
b 2
c 4
dtype: int64
DataFrame concat (concat)
Python
df1 = pd.DataFrame([[1, 2], [3, 4]], index=list('AB'),columns=list('ab'))
df2 = pd.DataFrame([[5, 6], [7, 8]], index=list('CD'),columns=list('ab'))
df3 = pd.DataFrame([[5, 6], [7, 8]], index=list('AB'),columns=list('cd'))
Python
df1
Python
df2
Python
df3
Python
#0ème axe(ligne)Empiler dans la direction
pd.concat([df1, df2], axis=0)
|
a |
b |
| A |
1 |
2 |
| B |
3 |
4 |
| C |
5 |
6 |
| D |
7 |
8 |
Python
#1er axe(Colonne)Empiler dans la direction
pd.concat([df1, df3], axis=1)
|
a |
b |
c |
d |
| A |
1 |
2 |
5 |
6 |
| B |
3 |
4 |
7 |
8 |
Fusion de DataFrame
Python
df1.index.name = df3.index.name = 'A'
df10 = df1.reset_index()
df30 = df3.reset_index()
Python
df10
Python
df30
Python
#Rejoignez la colonne A
pd.merge(df10, df30, on='A')
|
A |
a |
b |
c |
d |
| 0 |
A |
1 |
2 |
5 |
6 |
| 1 |
B |
3 |
4 |
7 |
8 |
On donne le nom de colonne à utiliser pour la jointure.
Plusieurs spécifications peuvent être spécifiées, auquel cas elles sont données sous forme de liste.
S'il est omis, le nom de colonne commun des deux DataFrames est adopté.
Dans l'exemple ci-dessus, le nom de colonne commun est uniquement A, il peut donc être omis.
Notez que la colonne d'index est ignorée dans la fusion.
Entrée et sortie de divers formats de fichiers
Les pandas peuvent entrer et sortir différents formats.
Python
a2 = np.arange(16) .reshape(4,4)
idx = pd.MultiIndex.from_product( [['A','B'],['a','b']], names=('i','j'))
col = pd.MultiIndex.from_product( [['C','D'],['c','d']], names=('k','l'))
df = pd.DataFrame(a2, index=idx, columns=col)
df
|
k |
C |
D |
|
l |
c |
d |
c |
d |
| i |
j |
|
|
|
|
| A |
a |
0 |
1 |
2 |
3 |
| b |
4 |
5 |
6 |
7 |
| B |
a |
8 |
9 |
10 |
11 |
| b |
12 |
13 |
14 |
15 |
Exporter le fichier
Python
#Sortie vers un fichier HTML
df.to_html('a2.html')

Python
#Sortie dans un fichier Excel(Nécessite openpyxl)
df.to_excel('a2.xlsx')
Lire le fichier
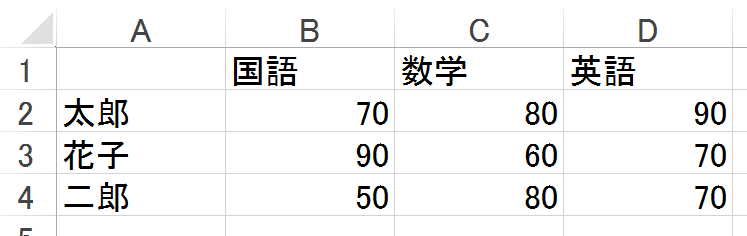
Python
xl = pd.ExcelFile('test.xlsx')
#Feuille de spécification
df = xl.parse('Sheet1')
df
|
japonais
| Mathématiques
| anglais
|
| Taro
| 70 |
80 |
90 |
| Hanako
| 90 |
60 |
70 |
| Jiro
| 50 |
80 |
70 |
Créer un graphique
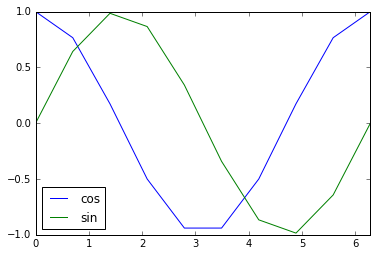
Pandas fonctionne très bien avec Matplotlib et facilite la création de graphiques à partir de DataFrames.
Python
%matplotlib inline
x = np.linspace(0, 2*np.pi, 10)
df = pd.DataFrame(dict(sin=np.sin(x), cos=np.cos(x)), index=x)
df
|
cos |
sin |
| 0.000000 |
1.000000 |
0.000000e+00 |
| 0.698132 |
0.766044 |
6.427876e-01 |
| 1.396263 |
0.173648 |
9.848078e-01 |
| 2.094395 |
-0.500000 |
8.660254e-01 |
| 2.792527 |
-0.939693 |
3.420201e-01 |
| 3.490659 |
-0.939693 |
-3.420201e-01 |
| 4.188790 |
-0.500000 |
-8.660254e-01 |
| 4.886922 |
0.173648 |
-9.848078e-01 |
| 5.585054 |
0.766044 |
-6.427876e-01 |
| 6.283185 |
1.000000 |
-2.449294e-16 |
Python
#Sortie graphique
df.plot()