[PYTHON] I tried to judge Tsundere with Naive Bayes
Introduction
This is a demo.
input=>Hey what! ?? I'm surprised ...
category: tsundere
input=>I love you I love you so much.
category: not_tsundere
input=>...... Don't touch it casually, stupid.
category: tsundere
input=>person love! I like humans! I love you!
category: not_tsundere
Good ...
What i did
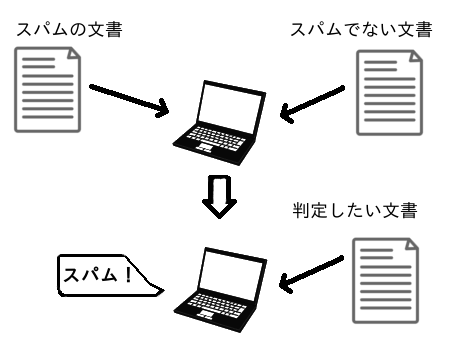
In the case of normal spam judgment
It trains the computer to learn spam and non-spam text, respectively, to determine if the newly entered text is spam.
 ...boring
...boring
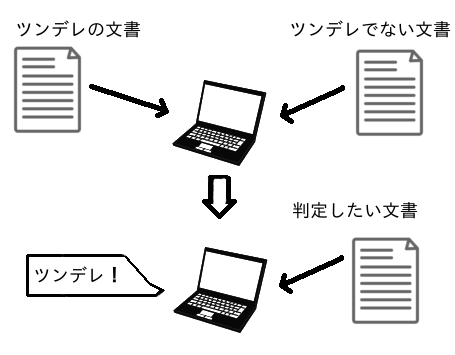
In the case of tsundere judgment
Trains the computer to learn tsundere text and non-tsundere text, respectively, to determine if the newly entered text is tsundere.
pleasant! !!
Data preparation
Of course, learning data is required for learning. I have to somehow prepare a text full of tsundere. This time I used twitter to collect the data. We get tweets from accounts like "Tsundere bot" and use them as learning data.
code
The code can be found on GitHub. See the README for details on how to use it. I used the code of Naive Bayes from katryo's article.
It requires python-twitter (which can be installed with pip) to work. You also need to issue the key for the twitter application and the yahoo morphological analysis application ID. You can get each below.
https://dev.twitter.com/ https://e.developer.yahoo.co.jp/register
Please select "Client Side" when issuing the Yahoo application ID.
Paste each issued ID into settings.cfg and enter the appropriate accounts `true_accounts``` and ` You can use it by setting it to false_accounts```.
Since 200 tweets are acquired for each account and learned, the more accounts you specify, the longer it will take to learn. Determine the number of accounts to specify appropriately by looking at the trade-off between time and accuracy.
Finally
You can make your own learning device by learning different data. In addition to the tsundere judgment, it may be interesting to try the yandere judgment and the handsome judgment.
Recommended Posts