[PYTHON] I tried to move Faster R-CNN quickly with pytorch
Introduction
A memorandum because there were few articles running Faster R-CNN with a proper data set and I had a lot of trouble.
Since this is my first post, I think there are some things that cannot be reached, but if you have any mistakes, please point out.
Notes
- This article is for ** PSCAL VOC format datasets **. I converted the dataset called BDD100K to Pascal VOC format and trained, so the class label is that of BDD100K.
code
All code is posted on github. (If you copy and paste all the code below and match the class name to the dataset, it should work)
import
Crispy
import numpy as np
import pandas as pd
from PIL import Image
from glob import glob
import xml.etree.ElementTree as ET
import torch
import torchvision
from torchvision import transforms
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
dataloader.py
#Data location
xml_paths_train=glob("##########/*.xml")
xml_paths_val=glob("###########/*.xml")
image_dir_train="#############"
image_dir_val="##############"
The top two lines are the location of the xml file The two lines are the location of the image
Data reading
dataloader.py
class xml2list(object):
def __init__(self, classes):
self.classes = classes
def __call__(self, xml_path):
ret = []
xml = ET.parse(xml_path).getroot()
for size in xml.iter("size"):
width = float(size.find("width").text)
height = float(size.find("height").text)
for obj in xml.iter("object"):
difficult = int(obj.find("difficult").text)
if difficult == 1:
continue
bndbox = [width, height]
name = obj.find("name").text.lower().strip()
bbox = obj.find("bndbox")
pts = ["xmin", "ymin", "xmax", "ymax"]
for pt in pts:
cur_pixel = float(bbox.find(pt).text)
bndbox.append(cur_pixel)
label_idx = self.classes.index(name)
bndbox.append(label_idx)
ret += [bndbox]
return np.array(ret) # [width, height, xmin, ymin, xamx, ymax, label_idx]
Loading annotations
For classes, enter ** the class of data used **.
dataloader.py
#Loading of train annotation
xml_paths=xml_paths_train
classes = [###################################]
transform_anno = xml2list(classes)
df = pd.DataFrame(columns=["image_id", "width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
for path in xml_paths:
#image_id = path.split("/")[-1].split(".")[0]
image_id = path.split("\\")[-1].split(".")[0]
bboxs = transform_anno(path)
for bbox in bboxs:
tmp = pd.Series(bbox, index=["width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
tmp["image_id"] = image_id
df = df.append(tmp, ignore_index=True)
df = df.sort_values(by="image_id", ascending=True)
#Reading val annotation
xml_paths=xml_paths_val
classes = [#######################]
transform_anno = xml2list(classes)
df_val = pd.DataFrame(columns=["image_id", "width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
for path in xml_paths:
#image_id = path.split("/")[-1].split(".")[0]
image_id = path.split("\\")[-1].split(".")[0]
bboxs = transform_anno(path)
for bbox in bboxs:
tmp = pd.Series(bbox, index=["width", "height", "xmin", "ymin", "xmax", "ymax", "class"])
tmp["image_id"] = image_id
df_val = df_val.append(tmp, ignore_index=True)
df_val = df_val.sort_values(by="image_id", ascending=True)
Loading images
dataloader.py
#Loading images
#Dog needs background class (0),1 start label for cat
df["class"] = df["class"] + 1
class MyDataset(torch.utils.data.Dataset):
def __init__(self, df, image_dir):
super().__init__()
self.image_ids = df["image_id"].unique()
self.df = df
self.image_dir = image_dir
def __getitem__(self, index):
transform = transforms.Compose([
transforms.ToTensor()
])
#Loading input image
image_id = self.image_ids[index]
image = Image.open(f"{self.image_dir}/{image_id}.jpg ")
image = transform(image)
#Reading annotation data
records = self.df[self.df["image_id"] == image_id]
boxes = torch.tensor(records[["xmin", "ymin", "xmax", "ymax"]].values, dtype=torch.float32)
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
area = torch.as_tensor(area, dtype=torch.float32)
labels = torch.tensor(records["class"].values, dtype=torch.int64)
iscrowd = torch.zeros((records.shape[0], ), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"]= labels
target["image_id"] = torch.tensor([index])
target["area"] = area
target["iscrowd"] = iscrowd
return image, target, image_id
def __len__(self):
return self.image_ids.shape[0]
image_dir1=image_dir_train
dataset = MyDataset(df, image_dir1)
image_dir2=image_dir_val
dataset_val = MyDataset(df_val, image_dir2)
Creating a DataLoader
dataloader.py
#Data loading
torch.manual_seed(2020)
train=dataset
val=dataset_val
def collate_fn(batch):
return tuple(zip(*batch))
train_dataloader = torch.utils.data.DataLoader(train, batch_size=1, shuffle=True, collate_fn=collate_fn)
val_dataloader = torch.utils.data.DataLoader(val, batch_size=2, shuffle=False, collate_fn=collate_fn)
The batch_size is small because the GPU memory overflowed immediately when I turned it.
Model definition
** model1.py ** is recommended if you want to improve the accuracy even with a small number of learning sheets. I just want to play with the model to some extent! Please use ** model2.py **. (Model 2 has almost no commentary article, and I was worried about it forever because the source code of the torchvision tutorial is wrong.)
*** Caution num_classes will not work unless the number of classes you want to classify is +1. (+1 is because the background is also classified) **
model1 normally uses a trained model with resnet50 as the backbone
model1.py
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=False)####True
##Note: Number of classes + 1
num_classes = (len(classes)) + 1
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
model2 looks like this (there is a bug in the tutorial ...)
model2.py
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
backbone.out_channels = 1280
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
#When the tutorial is packed, an error is thrown here.([0]To['0']If you set it to)
'''
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=[0],
output_size=7,
sampling_ratio=2)
'''
#By default
roi_pooler =torchvision.ops.MultiScaleRoIAlign(
featmap_names=['0','1','2','3'],
output_size=7,
sampling_ratio=2)
# put the pieces together inside a FasterRCNN model
model = FasterRCNN(backbone,
num_classes=(len(classes)) + 1,###Caution
rpn_anchor_generator=anchor_generator)
#box_roi_pool=roi_pooler)
The FasterRCNN function has various arguments and you can play with the model quite a bit. For more information here
Learning
Automatic differentiation is wonderful
train.py
##Learning
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
num_epochs = 5
#GPU cache clear
import torch
torch.cuda.empty_cache()
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
##model.cuda()
model.train()#Move to learning mode
for epoch in range(num_epochs):
for i, batch in enumerate(train_dataloader):
images, targets, image_ids = batch#####batch is the image and targets of the mini-batch,image_Contains ids
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
##Image and target (ground) in learning mode-truth)
##The return value is dict[tensor]There is a loss in it. (Loss for both RPN and RCNN)
loss_dict= model(images, targets)
losses = sum(loss for loss in loss_dict.values())
loss_value = losses.item()
optimizer.zero_grad()
losses.backward()
optimizer.step()
if (i+1) % 20 == 0:
print(f"epoch #{epoch+1} Iteration #{i+1} loss: {loss_value}")
View results
Note: Enter the usage data label according to the entry example for the ctegory here.
test.py
#View results
def show(val_dataloader):
import matplotlib.pyplot as plt
from PIL import ImageDraw, ImageFont
from PIL import Image
#GPU cache clear
import torch
torch.cuda.empty_cache()
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
#device = torch.device('cpu')
model.to(device)
model.eval()#To inference mode
images, targets, image_ids = next(iter(val_dataloader))
images = list(img.to(device) for img in images)
#Returns a prediction when inferring
'''
- boxes (FloatTensor[N, 4]): the predicted boxes in [x1, y1, x2, y2] format, with values of x
between 0 and W and values of y between 0 and H
- labels (Int64Tensor[N]): the predicted labels for each image
- scores (Tensor[N]): the scores or each prediction
'''
outputs = model(images)
for i, image in enumerate(images):
image = image.permute(1, 2, 0).cpu().numpy()
image = Image.fromarray((image * 255).astype(np.uint8))
boxes = outputs[i]["boxes"].data.cpu().numpy()
scores = outputs[i]["scores"].data.cpu().numpy()
labels = outputs[i]["labels"].data.cpu().numpy()
category={0: 'background',##################}
#Category entry example
#category={0: 'background',1:'person', 2:'traffic light',3: 'train',4: 'traffic sign', 5:'rider', 6:'car', 7:'bike',8: 'motor', 9:'truck', 10:'bus'}
boxes = boxes[scores >= 0.5].astype(np.int32)
scores = scores[scores >= 0.5]
image_id = image_ids[i]
for i, box in enumerate(boxes):
draw = ImageDraw.Draw(image)
label = category[labels[i]]
draw.rectangle([(box[0], box[1]), (box[2], box[3])], outline="red", width=3)
#Label display
from PIL import Image, ImageDraw, ImageFont
#fnt = ImageFont.truetype('/content/mplus-1c-black.ttf', 20)
fnt = ImageFont.truetype("arial.ttf", 10)#40
text_w, text_h = fnt.getsize(label)
draw.rectangle([box[0], box[1], box[0]+text_w, box[1]+text_h], fill="red")
draw.text((box[0], box[1]), label, font=fnt, fill='white')
#For when you want to save an image
#image.save(f"resample_test{str(i)}.png ")
fig, ax = plt.subplots(1, 1)
ax.imshow(np.array(image))
plt.show()
show(val_dataloader)
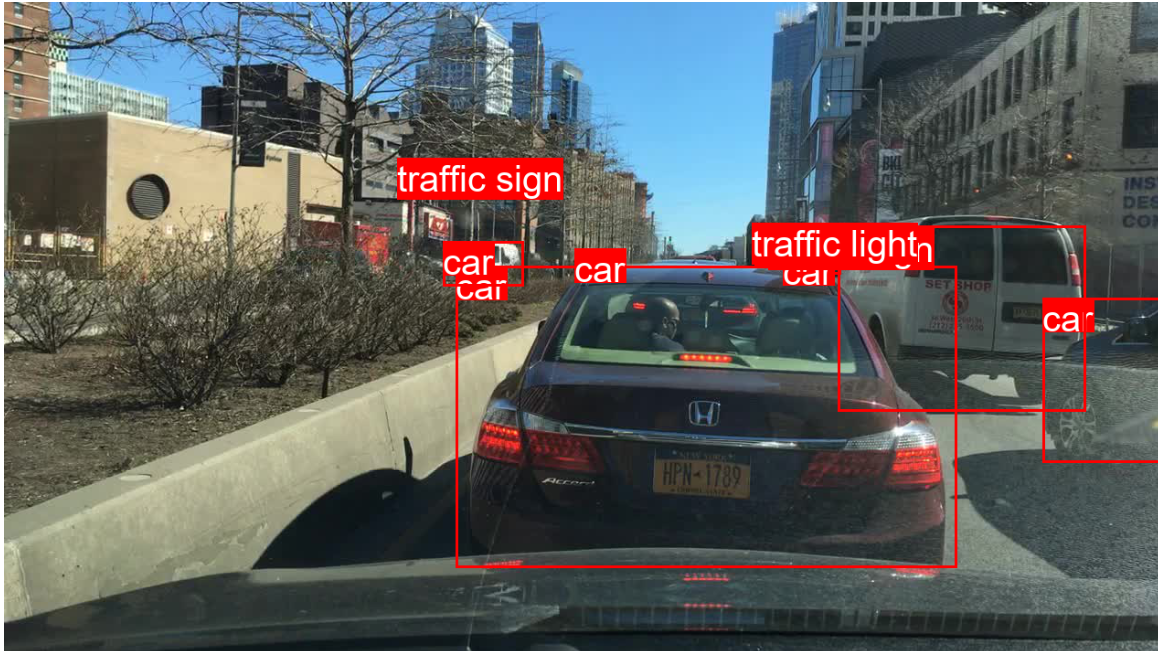
It should be displayed like this
Finally
――I wrote an article for the first time. It's almost like just pasting the source code, but I hope you can refer to it. ――I want to try a dissertation commentary
References
- http://maruo51.com/2020/06/06/faster-rcnn_dogcat/
--Click here for the torchvision tutorial [https://colab.research.google.com/github/pytorch/vision/blob/temp-tutorial/tutorials/torchvision_finetuning_instance_segmentation.ipynb#scrollTo=UYDb7PBw55b-)
Recommended Posts