[PYTHON] Pandas User Guide "merge, join and concatenate" (Japanese translation of official documentation)
This article is a machine translation of the official Pandas documentation User Guide --Merge, join, and concatenate. It is a modification of the unnatural sentences of the club.
If you have any mistranslations, alternative translations, questions, etc., please use the comments section or edit request.
merge, join and concatenate
pandas provides different types of set operations and features for indexing and relational algebra in join / merge operations to easily join Series or DataFrames.
Object concatenate
concat () Function (exists in the main pandas namespace) Does all the tedious work of performing concatenation operations along an axis, while performing arbitrary set operations (union or intersection) on the indexes of other axes (if any). Note that we say "if there is" because the Series has only one axis of connection. Before we dive into the details of Concat and what it can do, here's a simple example.
Before we dive into the details of concat and what it can do, here's a simple example.
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
...:
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...: 'B': ['B4', 'B5', 'B6', 'B7'],
...: 'C': ['C4', 'C5', 'C6', 'C7'],
...: 'D': ['D4', 'D5', 'D6', 'D7']},
...: index=[4, 5, 6, 7])
...:
In [3]: df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
...: 'B': ['B8', 'B9', 'B10', 'B11'],
...: 'C': ['C8', 'C9', 'C10', 'C11'],
...: 'D': ['D8', 'D9', 'D10', 'D11']},
...: index=[8, 9, 10, 11])
...:
In [4]: frames = [df1, df2, df3]
In [5]: result = pd.concat(frames)
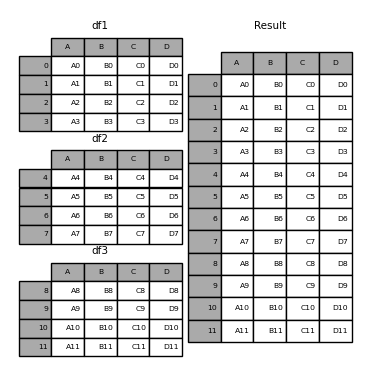
Like the sibling function of ndarrays, numpy.concatenate, pandas.concat takes a list or dictionary of similar objects, along with some configurable "what to do with other axes" processing. Concatenate.
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True)
--ʻObjs: Sequence or mapping of Series or DataFrame objects. If a dictionary is passed, the sorted keys will be used as * keys * arguments. If not, the value is selected (see below). None Objects are implicitly excluded. If all are None, ValueError will occur. --ʻAxis: {0, 1,…}, default is 0. Specify the axes to connect.
--join: {‘inner’, ‘outer’}, default is ‘outer’. How to handle indexes on other axes. The outer is the union, and the inner is the intersection.
--ʻIgnore_index: Boolean value, default is False. If True, the index value on the concatenated axis is not used. The resulting axes are labeled 0,…, n -1. This is useful when you want to concatenate objects that do not have meaningful index information on the concatenation axis. Note that the index values on the other axes will continue to be considered in the join. --keys: Sequence, default is None. Builds a hierarchical index using the passed key as the outermost level. If multiple levels are passed, tuples must be included. --levels: List of sequences, default is None. The specific level (unique value) used to build the MultiIndex. If None, it is inferred from keys. --names: List, default is None. The name of the level of the resulting hierarchical index. -- verify_integrity: Boolean value, default is False. Check if the new connecting axis contains duplicates. This can be very expensive compared to the actual data concatenation. --copy`: Boolean, default is True. If False, the data will not be copied unnecessarily.
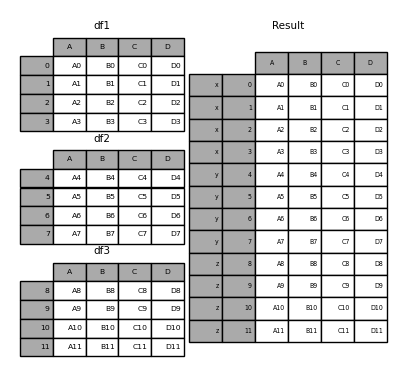
Without some explanation, most of these arguments may not make sense. Let's look at the above example again. Suppose you want to associate a particular key with each part of a DataFrame before joining. You can do this using the keys argument.
In [6]: result = pd.concat(frames, keys=['x', 'y', 'z'])
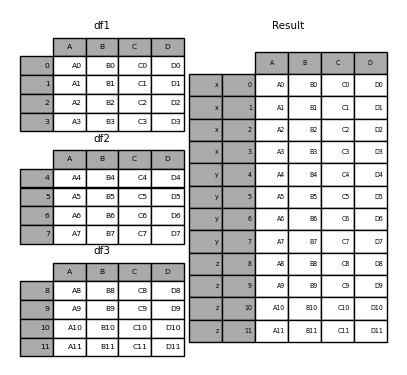
As you can see (if you read the rest of the docs), the resulting object index has a Hierarchical Index (https://qiita.com/nkay/items/63afdd4e96f21efbf62b#hierarchical). There is an index multi-index). This means that you can select each chunk by key.
In [7]: result.loc['y']
Out[7]:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
It's not hard to see how useful this is. See below for more information on this feature.
: ballot_box_with_check: ** Note **
concat ()(and therefore ʻappend ()`) is the data Note that making a complete copy of and constantly reusing this function will significantly reduce performance. If you need to use the operation on multiple datasets, use list comprehensions.
frames = [ process_your_file(f) for f in files ]
result = pd.concat(frames)
Set operations on other axes
When combining multiple DataFrames, you can choose how to handle other axes (other than the axes that are connected). This can be done in two ways:
--If you want to join all (sum, union), set join ='outer'. This is the default option as it results in zero information loss.
--If you want to take a common part (intersection), set join ='inner'.
Here is an example of each of these methods: First, the behavior when the default join ='outer' is
In [8]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
...: 'D': ['D2', 'D3', 'D6', 'D7'],
...: 'F': ['F2', 'F3', 'F6', 'F7']},
...: index=[2, 3, 6, 7])
...:
In [9]: result = pd.concat([df1, df4], axis=1, sort=False)
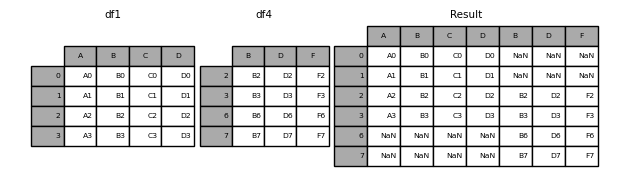
: warning: ** Warning ** _ Changed in version 0.23.0 _
join ='outer'sorts other axes (columns in this case) by default. Future versions of pandas will not sort by default. Here we specifiedsort = Falseand selected the new behavior.
Doing the same with join ='inner'
In [10]: result = pd.concat([df1, df4], axis=1, join='inner')

Finally, suppose you want to reuse the * exact index * of the original DataFrame.
In [11]: result = pd.concat([df1, df4], axis=1).reindex(df1.index)
Similarly, you can create an index before joining.
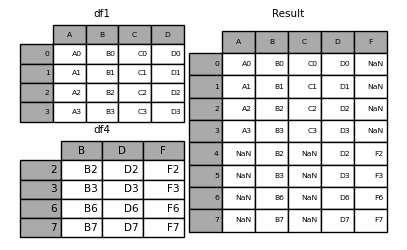
In [12]: pd.concat([df1, df4.reindex(df1.index)], axis=1)
Out[12]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3

Concatenation using ʻappend`
[ʻAppend ()] of Series and DataFrame (https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.append.html#pandas.DataFrame.append) Instance methods are a convenient shortcut to [concat ()](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.concat.html#pandas.concat). In reality, these methods preceded concat. They join along ʻaxis = 0, ie index.
In [13]: result = df1.append(df2)

For DataFrame, the rows are always separate (even if they have the same value), but the columns are not.
In [14]: result = df1.append(df4, sort=False)

ʻAppend` can also receive and combine multiple objects.
In [15]: result = df1.append([df2, df3])

: ballot_box_with_check: ** Note ** The list type ʻappend ()
method adds an element to the original list and returns None, but this pandas [ʻappend ()](https://pandas.pydata.org/pandas-docs) /stable/reference/api/pandas.DataFrame.append.html#pandas.DataFrame.append) returns a copy ofdf1** unchanged ** anddf2concatenated.
Ignore the index of the concatenated axis
For DataFrame objects that don't have meaningful indexes, you may want to ignore duplicate indexes when joining them. To do this, use the ʻignore_index` argument.
In [16]: result = pd.concat([df1, df4], ignore_index=True, sort=False)
This argument also applies to DataFrame.append () valid.
In [17]: result = df1.append(df4, ignore_index=True, sort=False)

Combining data with different numbers of dimensions
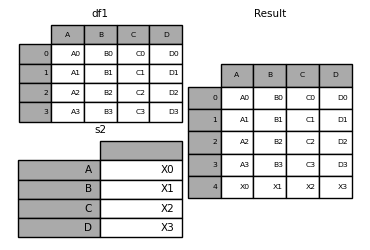
You can also combine Series and DataFrame objects. Series is converted to DataFrame with its name (name) as the column name.
In [18]: s1 = pd.Series(['X0', 'X1', 'X2', 'X3'], name='X')
In [19]: result = pd.concat([df1, s1], axis=1)
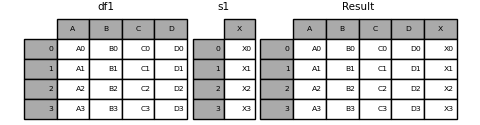
: ballot_box_with_check: ** Note ** Since I combined
SerieswithDataFrame, [DataFrame.assign ()](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.assign.html I was able to get the same result as # pandas.DataFrame.assign). Useconcatto concatenate any number of pandas objects (DataFrameorSeries).
If an unnamed Series is passed, a serial number will be added to the column name.
In [20]: s2 = pd.Series(['_0', '_1', '_2', '_3'])
In [21]: result = pd.concat([df1, s2, s2, s2], axis=1)
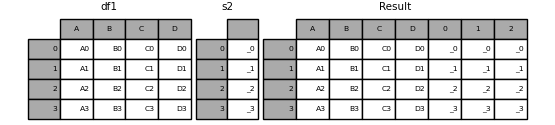
Passing ʻignore_index = True` removes all name references.
In [22]: result = pd.concat([df1, s1], axis=1, ignore_index=True)
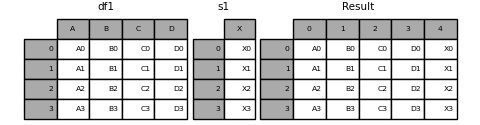
Further join using group key
The keys argument is often used to overwrite new column names when creating a new DataFrame from an existing Series. The default behavior is that if the original Series has a name, the resulting DataFrame inherits it.
In [23]: s3 = pd.Series([0, 1, 2, 3], name='foo')
In [24]: s4 = pd.Series([0, 1, 2, 3])
In [25]: s5 = pd.Series([0, 1, 4, 5])
In [26]: pd.concat([s3, s4, s5], axis=1)
Out[26]:
foo 0 1
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
You can overwrite an existing column name with a new one by using the keys argument.
In [27]: pd.concat([s3, s4, s5], axis=1, keys=['red', 'blue', 'yellow'])
Out[27]:
red blue yellow
0 0 0 0
1 1 1 1
2 2 2 4
3 3 3 5
Consider a variation of the first example given.
In [28]: result = pd.concat(frames, keys=['x', 'y', 'z'])

You can also pass the dictionary to concat. At this time, the dictionary key is used for the keys argument (unless no other key is specified).
In [29]: pieces = {'x': df1, 'y': df2, 'z': df3}
In [30]: result = pd.concat(pieces)
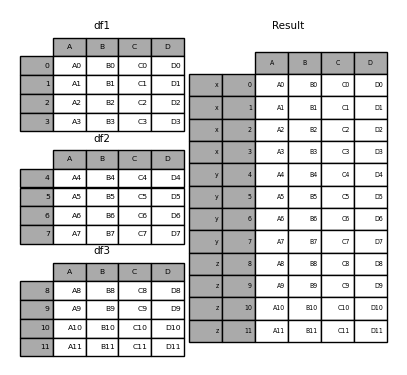
In [31]: result = pd.concat(pieces, keys=['z', 'y'])
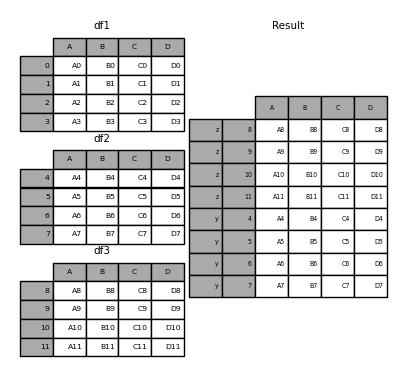
The MultiIndex created has a level consisting of the passed key and the index of the DataFrame piece.
In [32]: result.index.levels
Out[32]: FrozenList([['z', 'y'], [4, 5, 6, 7, 8, 9, 10, 11]])
If you want to specify other levels (and in some cases), you can specify them using the levels argument.
In [33]: result = pd.concat(pieces, keys=['x', 'y', 'z'],
....: levels=[['z', 'y', 'x', 'w']],
....: names=['group_key'])
....:
In [34]: result.index.levels
Out[34]: FrozenList([['z', 'y', 'x', 'w'], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]])
This is pretty esoteric, but it's actually needed for implementations such as GroupBy where the order of the categorical variables makes sense.
Append DataFrame row
It's not very efficient (because it always creates a new object), but you can add a line to the DataFrame by passing the Series or dictionary to the ʻappend. As mentioned at the beginning, this returns a new DataFrame`.
In [35]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
In [36]: result = df1.append(s2, ignore_index=True)
If you want this method to discard the original index of DataFrame, use ʻignore_index. If you want to keep the indexes, you need to build a properly indexed DataFrame` and append or concatenate those objects.
You can also pass a dictionary or a list of Series.
In [37]: dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4},
....: {'A': 5, 'B': 6, 'C': 7, 'Y': 8}]
....:
In [38]: result = df1.append(dicts, ignore_index=True, sort=False)

Database style DataFrame or named Series join / merge
Pandas has a full-featured ** high-performance ** in-memory join operation that is very similar to relational databases such as SQL. These methods are significantly better than other open source implementations (such as R's base :: merge.data.frame) (and in some cases even an order of magnitude better). The reason for this is careful algorithm design and the internal layout of the DataFrame data.
See also the cookbook (https://pandas.pydata.org/pandas-docs/stable/user_guide/cookbook.html#cookbook-selection) for more advanced operations.
If you're used to SQL but are new to pandas, compare with SQL (https://dev.pandas.io/docs/getting_started/comparison/comparison_with_sql.html#compare-with-sql-join) ) May be useful.
pandas provides a single function merge () as an entry point for all standard database join operations between DataFrame or named Series objects.
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
--left: DataFrame or named Series object.
--right: Another DataFrame or named Series object.
--ʻOn: The name of the column or row level to join. Must be present in both the left and right DataFrame or Series objects. If you do not specify this and left_index and right_indexareFalse, then the intersection of the DataFrame or Series columns is presumed to be the join key. --left_on: Left DataFrame or Series column or row level to use as a key. It can accept either column or row level names, or an array of length equal to the length (len) of a DataFrame or Series. --right_on: Left DataFrame or Series column or row level to use as a key. It can accept either column or row level names, or an array of length equal to the length (len) of a DataFrame or Series. --left_index: For True, use the left DataFrame or Series index (row label) as the join key. For DataFrames or Series with MultiIndex (hierarchy), the number of levels must match the number of join keys from the DataFrame or Series on the right. --right_index: The same specification as left_index for the DataFrame or Series on the right side. --how: One of 'left'・'right'・'outer'・'inner'. The default is'inner'. Details on each method are given below. --sort: Sorts the resulting DataFrame into a lexicographic expression with the join key. The default is True, and setting it to False will often significantly improve performance. --suffixes: A tuple of prefixes applied to duplicate columns. The default is ('x',' y'). --copy: (if the default True) Always copies data from the passed DataFrame or named Series object, even if you do not need to reindex. Copying cannot be avoided in many cases, but it can improve performance memory usage. Copying can rarely be avoided, but this option is still offered. --ʻIndicator: Adds a column named _merge to the output DataFrame with information about the source of each row. _merge is a Categorical type, left_only if the merge key exists only in the'left'DataFrame or Series, right_only if it exists only in the right DataFrame or Series, if it exists in both Takes the value of both.
--validate: String, default is None. If specified, check if the merge is of the specified type.
--“One_to_one” or “1: 1”: Checks if the merge key is unique for both the left and right datasets.
--“One_to_many” or “1: m”: Check if the merge key is unique in the dataset on the left.
--“Many_to_one” or “m: 1”: Checks if the merge key is unique in the right dataset.
--“Many_to_many” or “m: m”: Receives an argument, but is not confirmed.
_ From version 0.21.0 _
: ballot_box_with_check: ** Note ** Support for specifying row levels with the ʻon
,left_on, andright_onarguments was added in version 0.23.0. Support for merging namedSeries` objects was added in version 0.24.0.
The return type is the same as left. If left is a DataFrame or a named Series and right is a subclass of DataFrame, the return type will continue to be DataFrame.
merge is a function in the pandas namespace, but you can also use the DataFrame instance method merge (). The calling DataFrame is implicitly considered the object to the left of the join.
The associated join () method uses merge internally for index-on-index (default) and column-on-index joins. If you want to join by index only, you can use DataFrame.join to simplify the input.
Outline of merge method (relational algebra)
Experienced users of relational databases like SQL are familiar with the terminology used to describe join operations between two SQL table-like structures (DataFrame objects). There are some cases to consider that are very important to understand.
-** one-to-one ** Join: For example, when joining two DataFrame objects according to an index (including a unique value).
-** many-to-one ** Join: For example, when joining an index (unique) to one or more columns in different DataFrames.
-** many-to-many ** Join: When joining columns to columns.
When joining columns (like ** many-to-many ** joins), all indexes on the passed
DataFrameobject are ** discarded **.
** many-to-many ** It's worth the time to understand the result of the join. In SQL and standard relational algebra, if a key combination appears multiple times in both tables, the resulting table will contain a ** Cartesian product ** of the relevant data. The following is a very basic example using one unique key combination.
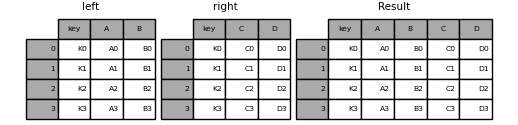
In [39]: left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [40]: right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [41]: result = pd.merge(left, right, on='key')
The following is a more complex example with multiple join keys. By default, how ='inner', so only the keys that are common to the left and right will appear in the result (intersection intersection).
In [42]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [43]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
....: 'key2': ['K0', 'K0', 'K0', 'K0'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [44]: result = pd.merge(left, right, on=['key1', 'key2'])

The how argument specifies how to determine which key is contained in the table resulting from merge. If the key combination ** does not exist in either the left or right table **, the value of the joined table will be NA. The following is a summary of the how option and its corresponding SQL name.
| merge method | The name of the SQL JOIN | motion |
|---|---|---|
left |
LEFT OUTER JOIN |
Use only the left key |
right |
RIGHT OUTER JOIN |
Use only the right key |
outer |
FULL OUTER JOIN |
Use the sum of both keys |
inner |
INNER JOIN |
Use the intersection of both keys |
In [45]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])
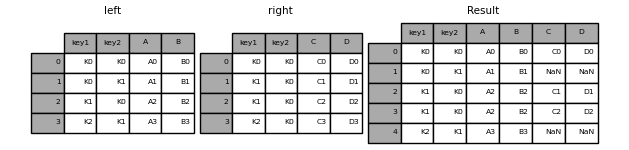
In [46]: result = pd.merge(left, right, how='right', on=['key1', 'key2'])

In [47]: result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
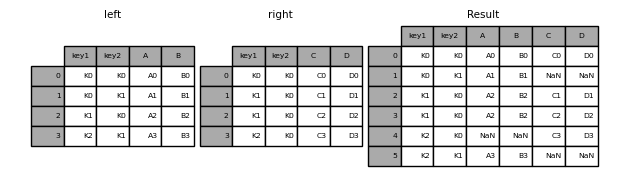
In [48]: result = pd.merge(left, right, how='inner', on=['key1', 'key2'])

The following example is for a DataFrame with duplicate join keys.
In [49]: left = pd.DataFrame({'A': [1, 2], 'B': [2, 2]})
In [50]: right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 2, 2]})
In [51]: result = pd.merge(left, right, on='B', how='outer')
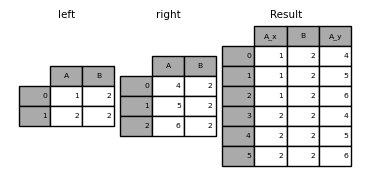
: warning: ** Warning ** Join / merge with duplicate keys may return a frame of row dimension multiplication, which can cause a memory overflow. Users must manage key duplication before joining a large DataFrame.
Check for duplicate keys
_ From version 0.21.0 _
The user can use the validate argument to automatically check for unexpected duplicates in the merge key. Key uniqueness is checked before the join operation, which will prevent memory overflows. Checking the uniqueness of the key is also a good way to make sure that the user data structure is as expected.
In the following example, the B value of the DataFrame on the right is duplicated. This is not a one-to-one merge specified by the validate argument, so an exception is raised.
In [52]: left = pd.DataFrame({'A' : [1,2], 'B' : [1, 2]})
In [53]: right = pd.DataFrame({'A' : [4,5,6], 'B': [2, 2, 2]})
In [53]: result = pd.merge(left, right, on='B', how='outer', validate="one_to_one")
...
MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
If you already know that the DataFrame on the right has duplicates and you want to make sure that the DataFrame on the left has no duplicates, you can use the validate ='one_to_many' argument instead. This does not raise an exception.
In [54]: pd.merge(left, right, on='B', how='outer', validate="one_to_many")
Out[54]:
A_x B A_y
0 1 1 NaN
1 2 2 4.0
2 2 2 5.0
3 2 2 6.0
merge indicator
merge () takes an ʻindicatorargument. IfTrue, a column of type _mergenamed_merge` with one of the following values will be added to the output object.
| Observation origin | _mergeThe value of the |
|---|---|
The join key isleftExists only in the frame |
left_only |
The join key isrightExists only in the frame |
right_only |
| Join key exists in both frames | both |
In [55]: df1 = pd.DataFrame({'col1': [0, 1], 'col_left': ['a', 'b']})
In [56]: df2 = pd.DataFrame({'col1': [1, 2, 2], 'col_right': [2, 2, 2]})
In [57]: pd.merge(df1, df2, on='col1', how='outer', indicator=True)
Out[57]:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
The ʻindicator` argument can also take a string. In this case, the indicator function uses the value of the passed string as the name of the indicator column.
In [58]: pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')
Out[58]:
col1 col_left col_right indicator_column
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
data type of merge
merge holds the data type of the merge key.
In [59]: left = pd.DataFrame({'key': [1], 'v1': [10]})
In [60]: left
Out[60]:
key v1
0 1 10
In [61]: right = pd.DataFrame({'key': [1, 2], 'v1': [20, 30]})
In [62]: right
Out[62]:
key v1
0 1 20
1 2 30
You can hold the join key.
In [63]: pd.merge(left, right, how='outer')
Out[63]:
key v1
0 1 10
1 1 20
2 2 30
In [64]: pd.merge(left, right, how='outer').dtypes
Out[64]:
key int64
v1 int64
dtype: object
Of course, if there are missing values, the resulting data type will be upcast.
In [65]: pd.merge(left, right, how='outer', on='key')
Out[65]:
key v1_x v1_y
0 1 10.0 20
1 2 NaN 30
In [66]: pd.merge(left, right, how='outer', on='key').dtypes
Out[66]:
key int64
v1_x float64
v1_y int64
dtype: object
merge retains the original category data type. See also the section on Categories (https://dev.pandas.io/docs/user_guide/categorical.html#categorical-merge).
Left frame.
In [67]: from pandas.api.types import CategoricalDtype
In [68]: X = pd.Series(np.random.choice(['foo', 'bar'], size=(10,)))
In [69]: X = X.astype(CategoricalDtype(categories=['foo', 'bar']))
In [70]: left = pd.DataFrame({'X': X,
....: 'Y': np.random.choice(['one', 'two', 'three'],
....: size=(10,))})
....:
In [71]: left
Out[71]:
X Y
0 bar one
1 foo one
2 foo three
3 bar three
4 foo one
5 bar one
6 bar three
7 bar three
8 bar three
9 foo three
In [72]: left.dtypes
Out[72]:
X category
Y object
dtype: object
Right frame.
In [73]: right = pd.DataFrame({'X': pd.Series(['foo', 'bar'],
....: dtype=CategoricalDtype(['foo', 'bar'])),
....: 'Z': [1, 2]})
....:
In [74]: right
Out[74]:
X Z
0 foo 1
1 bar 2
In [75]: right.dtypes
Out[75]:
X category
Z int64
dtype: object
The combined result.
In [76]: result = pd.merge(left, right, how='outer')
In [77]: result
Out[77]:
X Y Z
0 bar one 2
1 bar three 2
2 bar one 2
3 bar three 2
4 bar three 2
5 bar three 2
6 foo one 1
7 foo three 1
8 foo one 1
9 foo three 1
In [78]: result.dtypes
Out[78]:
X category
Y object
Z int64
dtype: object
: ballot_box_with_check: ** Note ** Category types must have the same category and order attributes and be * exactly * the same. Otherwise, the result will be overwritten with the data type of the category element.
: ballot_box_with_check: ** Note ** Joining the same
categorydata types can be very performant compared to merging ʻobject` data types.
Join according to the index
DataFrame.join () can have different indexes A handy method for joining two possible DataFrame columns into a single DataFrame. The following example is a very basic example.
In [79]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=['K0', 'K1', 'K2'])
....:
In [80]: right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
....: 'D': ['D0', 'D2', 'D3']},
....: index=['K0', 'K2', 'K3'])
....:
In [81]: result = left.join(right)
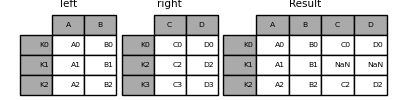
In [82]: result = left.join(right, how='outer')
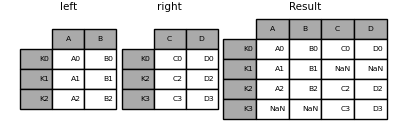
Similar to the above, using how ='inner',
In [83]: result = left.join(right, how='inner')
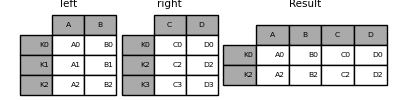
The alignment of the data here is based on the index (row label). To do the same thing with merge, pass an additional argument telling it to use the index.
In [84]: result = pd.merge(left, right, left_index=True, right_index=True, how='outer')

In [85]: result = pd.merge(left, right, left_index=True, right_index=True, how='inner')

Join key column to index
join () is an optional ʻonargument , Receives a column or multiple column names. The passedDataFrame will be joined along that column in the DataFrame`. The following two function calls are exactly equivalent.
left.join(right, on=key_or_keys)
pd.merge(left, right, left_on=key_or_keys, right_index=True,
how='left', sort=False)
Obviously, you can choose a more convenient format. For many-to-one joins (if one of the DataFrames is already indexed by the join key), it may be more convenient to use join. Here is a simple example.
In [86]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key': ['K0', 'K1', 'K0', 'K1']})
....:
In [87]: right = pd.DataFrame({'C': ['C0', 'C1'],
....: 'D': ['D0', 'D1']},
....: index=['K0', 'K1'])
....:
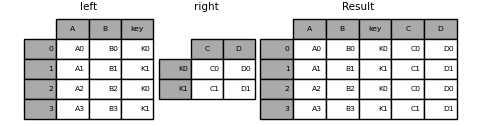
In [88]: result = left.join(right, on='key')
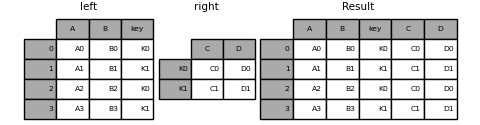
In [89]: result = pd.merge(left, right, left_on='key', right_index=True,
....: how='left', sort=False);
....:
To join with multiple keys, the passed DataFrame must have MultiIndex.
In [90]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1']})
....:
In [91]: index = pd.MultiIndex.from_tuples([('K0', 'K0'), ('K1', 'K0'),
....: ('K2', 'K0'), ('K2', 'K1')])
....:
In [92]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']},
....: index=index)
....:
This can be combined by passing two key column names.
In [93]: result = left.join(right, on=['key1', 'key2'])
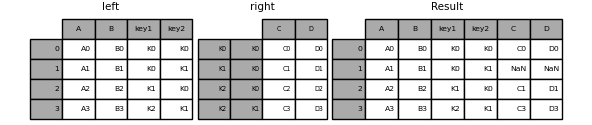
The default for DataFrame.join is to perform a left join (essentially a" VLOOKUP "operation for Excel users) that uses only the keys found in the calling DataFrame. Other join types, such as inner joins, are just as easy to perform.
In [94]: result = left.join(right, on=['key1', 'key2'], how='inner')
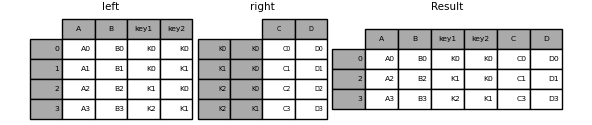
As above, this will remove the unmatched rows.
Joining a single index to multiple indexes
You can combine a single index DataFrame to a level of DataFrame with a MultiIndex. In the level name of a frame with MultiIndex, the level matches the index name of a single index frame.
In [95]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=pd.Index(['K0', 'K1', 'K2'], name='key'))
....:
In [96]: index = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
....: ('K2', 'Y2'), ('K2', 'Y3')],
....: names=['key', 'Y'])
....:
In [97]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']},
....: index=index)
....:
In [98]: result = left.join(right, how='inner')
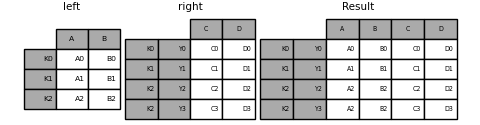
The following example is equivalent, but less redundant, more memory efficient and faster.
In [99]: result = pd.merge(left.reset_index(), right.reset_index(),
....: on=['key'], how='inner').set_index(['key','Y'])
....:

Combine two multi-indexes
This method can only be used if the right argument index is fully used in the join and is a subset of the left argument index, as in the following example.
In [100]: leftindex = pd.MultiIndex.from_product([list('abc'), list('xy'), [1, 2]],
.....: names=['abc', 'xy', 'num'])
.....:
In [101]: left = pd.DataFrame({'v1': range(12)}, index=leftindex)
In [102]: left
Out[102]:
v1
abc xy num
a x 1 0
2 1
y 1 2
2 3
b x 1 4
2 5
y 1 6
2 7
c x 1 8
2 9
y 1 10
2 11
In [103]: rightindex = pd.MultiIndex.from_product([list('abc'), list('xy')],
.....: names=['abc', 'xy'])
.....:
In [104]: right = pd.DataFrame({'v2': [100 * i for i in range(1, 7)]}, index=rightindex)
In [105]: right
Out[105]:
v2
abc xy
a x 100
y 200
b x 300
y 400
c x 500
y 600
In [106]: left.join(right, on=['abc', 'xy'], how='inner')
Out[106]:
v1 v2
abc xy num
a x 1 0 100
2 1 100
y 1 2 200
2 3 200
b x 1 4 300
2 5 300
y 1 6 400
2 7 400
c x 1 8 500
2 9 500
y 1 10 600
2 11 600
If that condition is not met, you can use the following code to perform a join of two multi-indexes.
In [107]: leftindex = pd.MultiIndex.from_tuples([('K0', 'X0'), ('K0', 'X1'),
.....: ('K1', 'X2')],
.....: names=['key', 'X'])
.....:
In [108]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=leftindex)
.....:
In [109]: rightindex = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
.....: ('K2', 'Y2'), ('K2', 'Y3')],
.....: names=['key', 'Y'])
.....:
In [110]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3']},
.....: index=rightindex)
.....:
In [111]: result = pd.merge(left.reset_index(), right.reset_index(),
.....: on=['key'], how='inner').set_index(['key', 'X', 'Y'])
.....:
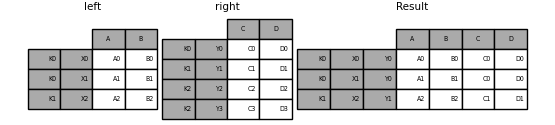
Merge with a combination of column and index level
_ From version 0.23 _
The string passed as the ʻon·left_on · right_onparameter can refer to either a column name or an index level name. This allows you to mergeDataFrame` instances with a combination of index levels and columns without resetting the index.
In [112]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [113]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
.....: 'B': ['B0', 'B1', 'B2', 'B3'],
.....: 'key2': ['K0', 'K1', 'K0', 'K1']},
.....: index=left_index)
.....:
In [114]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [115]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3'],
.....: 'key2': ['K0', 'K0', 'K0', 'K1']},
.....: index=right_index)
.....:
In [116]: result = left.merge(right, on=['key1', 'key2'])
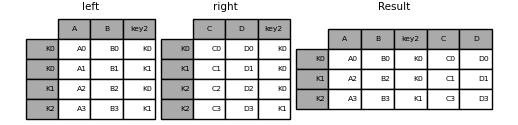
: ballot_box_with_check: ** Note ** If you merge a DataFrame with a string that matches the index level of both frames, the index level will be preserved as the index level of the resulting DataFrame.
: ballot_box_with_check: ** Note ** If you merge a DataFrame using only some levels of * MultiIndex *, the extra levels will be removed from the merge result. To keep these levels, use
reset_indexin their level name to move them to the column before performing the merge.
: ballot_box_with_check: ** Note ** If the string matches both the column name and the index level name, a warning is fired and the column takes precedence. This may cause ambiguous errors in future versions.
Columns with duplicate values
The merge suffixes argument takes a tuple of strings to add to the duplicate column name of the input DataFrame to clarify the resulting column.
In [117]: left = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'v': [1, 2, 3]})
In [118]: right = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'v': [4, 5, 6]})
In [119]: result = pd.merge(left, right, on='k')
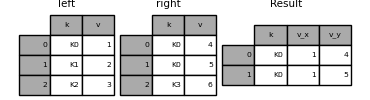
In [120]: result = pd.merge(left, right, on='k', suffixes=['_l', '_r'])
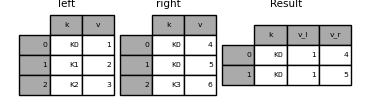
Works the same for DataFrame.join () There are lsuffix and rsuffix arguments to do.
In [121]: left = left.set_index('k')
In [122]: right = right.set_index('k')
In [123]: result = left.join(right, lsuffix='_l', rsuffix='_r')

Joining multiple DataFrames
Add a list or tuple of DataFrame to join () You can also pass them to join them by index.
In [124]: right2 = pd.DataFrame({'v': [7, 8, 9]}, index=['K1', 'K1', 'K2'])
In [125]: result = left.join([right, right2])
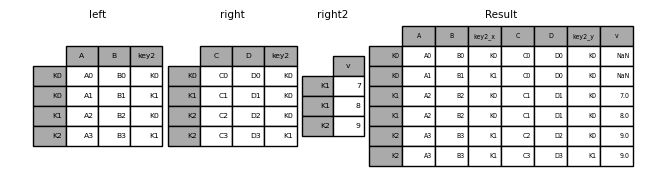
Combine values in a Series or DataFrame column
Another fairly common situation is to have two similarly indexed (or similarly indexed) Series or DataFrame objects that match the value of one object with the index of the other. You want to "patch" from the value. An example is shown below.
In [126]: df1 = pd.DataFrame([[np.nan, 3., 5.], [-4.6, np.nan, np.nan],
.....: [np.nan, 7., np.nan]])
.....:
In [127]: df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5., 1.6, 4]],
.....: index=[1, 2])
.....:
To do this, use the combine_first () method. I will.
In [128]: result = df1.combine_first(df2)
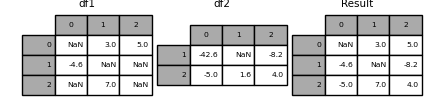
Note that this method gets the value from the right DataFrame only if the left DataFrame has no value. The related method ʻupdate () ` is non-NA. Change the value.
In [129]: df1.update(df2)

Join for time series data
Combine ordered data
merge_ordered () Time series and other ordering You can combine the data. It features an optional fill_method argument to fill and interpolate missing data.
In [130]: left = pd.DataFrame({'k': ['K0', 'K1', 'K1', 'K2'],
.....: 'lv': [1, 2, 3, 4],
.....: 's': ['a', 'b', 'c', 'd']})
.....:
In [131]: right = pd.DataFrame({'k': ['K1', 'K2', 'K4'],
.....: 'rv': [1, 2, 3]})
.....:
In [132]: pd.merge_ordered(left, right, fill_method='ffill', left_by='s')
Out[132]:
k lv s rv
0 K0 1.0 a NaN
1 K1 1.0 a 1.0
2 K2 1.0 a 2.0
3 K4 1.0 a 3.0
4 K1 2.0 b 1.0
5 K2 2.0 b 2.0
6 K4 2.0 b 3.0
7 K1 3.0 c 1.0
8 K2 3.0 c 2.0
9 K4 3.0 c 3.0
10 K1 NaN d 1.0
11 K2 4.0 d 2.0
12 K4 4.0 d 3.0
asof merge
merge_asof () is similar to an ordered left merge , Match with the closest key instead of the equal sign key. For each row of left DataFrame, select the last row of right DataFrame where the ʻon` key is less than the left key. Both DataFrames must be sorted by key.
Optionally, asof merge can perform group-by-group merges. This is an approximate match for the ʻonkey, plus an exact match for theby` key.
For example, if you have trades and quotes, merge them.
In [133]: trades = pd.DataFrame({
.....: 'time': pd.to_datetime(['20160525 13:30:00.023',
.....: '20160525 13:30:00.038',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.048']),
.....: 'ticker': ['MSFT', 'MSFT',
.....: 'GOOG', 'GOOG', 'AAPL'],
.....: 'price': [51.95, 51.95,
.....: 720.77, 720.92, 98.00],
.....: 'quantity': [75, 155,
.....: 100, 100, 100]},
.....: columns=['time', 'ticker', 'price', 'quantity'])
.....:
In [134]: quotes = pd.DataFrame({
.....: 'time': pd.to_datetime(['20160525 13:30:00.023',
.....: '20160525 13:30:00.023',
.....: '20160525 13:30:00.030',
.....: '20160525 13:30:00.041',
.....: '20160525 13:30:00.048',
.....: '20160525 13:30:00.049',
.....: '20160525 13:30:00.072',
.....: '20160525 13:30:00.075']),
.....: 'ticker': ['GOOG', 'MSFT', 'MSFT',
.....: 'MSFT', 'GOOG', 'AAPL', 'GOOG',
.....: 'MSFT'],
.....: 'bid': [720.50, 51.95, 51.97, 51.99,
.....: 720.50, 97.99, 720.50, 52.01],
.....: 'ask': [720.93, 51.96, 51.98, 52.00,
.....: 720.93, 98.01, 720.88, 52.03]},
.....: columns=['time', 'ticker', 'bid', 'ask'])
.....:
In [135]: trades
Out[135]:
time ticker price quantity
0 2016-05-25 13:30:00.023 MSFT 51.95 75
1 2016-05-25 13:30:00.038 MSFT 51.95 155
2 2016-05-25 13:30:00.048 GOOG 720.77 100
3 2016-05-25 13:30:00.048 GOOG 720.92 100
4 2016-05-25 13:30:00.048 AAPL 98.00 100
In [136]: quotes
Out[136]:
time ticker bid ask
0 2016-05-25 13:30:00.023 GOOG 720.50 720.93
1 2016-05-25 13:30:00.023 MSFT 51.95 51.96
2 2016-05-25 13:30:00.030 MSFT 51.97 51.98
3 2016-05-25 13:30:00.041 MSFT 51.99 52.00
4 2016-05-25 13:30:00.048 GOOG 720.50 720.93
5 2016-05-25 13:30:00.049 AAPL 97.99 98.01
6 2016-05-25 13:30:00.072 GOOG 720.50 720.88
7 2016-05-25 13:30:00.075 MSFT 52.01 52.03
As default, the quotes asof is applied.
In [137]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker')
.....:
Out[137]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
Keep the time between quote time and trade time within 2ms.
In [138]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker',
.....: tolerance=pd.Timedelta('2ms'))
.....:
Out[138]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 NaN NaN
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
Keep the time between quote and trade times within 10ms and exclude exact on-time matches. Exclude exact matches (of quotes), but note that previous quotes * propagate * up to that point.
In [139]: pd.merge_asof(trades, quotes,
.....: on='time',
.....: by='ticker',
.....: tolerance=pd.Timedelta('10ms'),
.....: allow_exact_matches=False)
.....:
Out[139]:
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 NaN NaN
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 NaN NaN
3 2016-05-25 13:30:00.048 GOOG 720.92 100 NaN NaN
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
Recommended Posts