[Python] Bestimmen Sie den Typ der Iris mit SVM
Versuchen wir ein Klassifizierungsproblem beim maschinellen Lernen unter Verwendung von Irisdaten, das häufig in Vorlesungen für Anfänger verwendet wird.
Zu verwendende Daten
irei Daten. (Iris bedeutet "Ayame" Blume.) Daten zu drei Irisarten, Setosa Versicolor Virginica. Insgesamt 150 Datensätze.
Datensatzinhalt
Sepal Länge: Länge des Stückes
Sepal Breite: Breite des Stückes
Blütenblattlänge: Blütenblattlänge
Blütenblattbreite: Blütenblattbreite
Name: Ayame-Sortendaten (Iris-Setosa, Iris-Vesicolor, Iris-Virginica)

Modell zu übernehmen
SVM (Support Vector Machine). SVM eignet sich für das Klassifizierungsproblem des überwachten Lernens. Ein Modell, das auch Spam-Diskriminatoren erzeugen kann. Da es sich um ein überwachtes Lernen handelt, sind Merkmalsdaten und objektive Variablen erforderlich.
Gesamtdurchfluss
- Vorbereitung der Daten
- Daten visualisieren
- Lernen und bewerten Sie das Modell
Trainieren
1) Vorbereitung der Daten
Importieren und bestätigen Sie nach dem Importieren der erforderlichen Bibliotheken zunächst die Daten.
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_style("whitegrid")
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split, cross_validate
df = pd.read_csv("iris.csv")
df.head()
SepalLength SepalWidth PetalLength PetalWidth Name
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
Teilen Sie in Trainingsdaten und Testdaten.
X = df[["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
y = df["Name"]
X_train, X_test, y_train, y_test = train_test_split(X, y)
X_train.shape, X_test.shape
((112, 4), (38, 4)) #Überprüfen Sie die Anzahl der Matrizen nach der Division
Erstellen Sie einen Datenrahmen für alle Trainingsdaten und Testdaten.
data_train = pd.DataFrame(X_train)
data_train["Name"] = y_train
2) Daten visualisieren
Welche Beziehung besteht in den Verifizierungsdaten tatsächlich zwischen der Art der Iris und der Menge des erworbenen Überschusses? Zeichnen Sie und prüfen Sie, ob es für jeden Typ Unterschiede in den Funktionen gibt.
sns.pairplot(data_train, hue='Name', palette="husl")
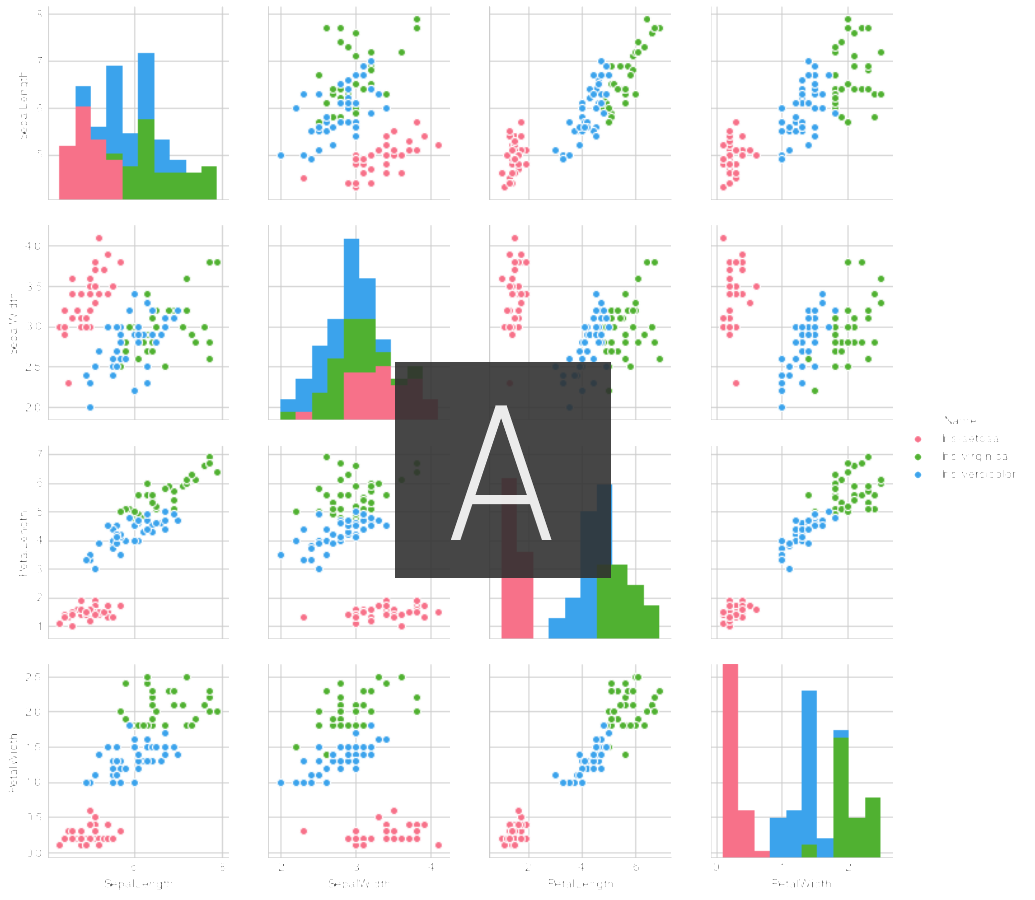
Sicherlich scheint es je nach Art der Iris einen deutlichen Unterschied zwischen den einzelnen Merkmalen zu geben.
3) Lernen und bewerten Sie das Modell
Lassen Sie uns die Verifizierungsdaten tatsächlich in SVM ablegen und ein Modell erstellen.
X_train = data_train[["SepalLength", "SepalWidth","PetalLength"]].values
y_train = data_train["Name"].values
from sklearn import svm,metrics
clf = svm.SVC()
clf.fit(X_train,y_train)
Geben Sie Testdaten in das erstellte Modell ein.
pre = clf.predict(X_test)
Bewerten Sie das Modell.
ac_score = metrics.accuracy_score(y_test,pre)
print("Richtige Antwortrate=", ac_score)
Richtige Antwortrate= 0.9736842105263158
Es wurde bestätigt, dass die Testdaten und die vom Modell erhaltenen Ergebnisse zu 97% konsistent waren.
Recommended Posts