Die Kraft der Pandas: Python

Pandas Basics### Pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language. It is already well on its way toward this goal.
Pandas is a high-level data manipulation tool developed by Wes McKinney. It is built on the Numpy package and its key data structure is called the DataFrame. DataFrames allow you to store and manipulate tabular data in rows of observations and columns of variables.

pandas is well suited for many different kinds of data: -Tabellendaten mit heterogen typisierten Spalten, wie in einer SQL-Tabelle oder einer Excel-Tabelle -Bestellte und ungeordnete (nicht unbedingt festfrequente) Zeitreihendaten. ・ Beliebige Matrixdaten (homogen oder heterogen) mit Zeilen- und Spaltenbeschriftungen ・ Jede andere Form von Beobachtungs- / statistischen Datensätzen. Die Daten müssen tatsächlich überhaupt nicht gekennzeichnet werden, um in eine Pandas-Datenstruktur eingefügt zu werden
Here are just a few of the things that pandas does well: ・ Einfache Behandlung fehlender Daten (dargestellt als NaN) sowohl in Gleitkommadaten als auch in Nicht-Gleitkommadaten -Size-Mutabilität: Spalten können in DataFrame- und höherdimensionale Objekte eingefügt und daraus gelöscht werden -Automatische und explizite Datenausrichtung: Objekte können explizit an einer Reihe von Beschriftungen ausgerichtet werden, oder der Benutzer kann die Beschriftungen einfach ignorieren und Serien, DataFrame usw. die Daten bei Berechnungen automatisch für Sie ausrichten lassen ・ Leistungsstarke, flexible Gruppierung nach Funktionen zum Ausführen von Split-Apply-Combine-Vorgängen für Datensätze zum Aggregieren und Transformieren von Daten ・ Machen Sie es einfach, unregelmäßige, unterschiedlich indizierte Daten in anderen Python- und NumPy-Datenstrukturen in DataFrame-Objekte zu konvertieren ・ Intelligentes etikettenbasiertes Slicing, ausgefallene Indizierung und Teilmenge großer Datenmengen ・ Intuitives Zusammenführen und Zusammenfügen von Datensätzen ・ Flexibles Umformen und Schwenken von Datensätzen ・ Hierarchische Beschriftung von Achsen (mehrere Beschriftungen pro Tick möglich) ・ Robuste E / A-Tools zum Laden von Daten aus Einfachdateien (CSV und getrennt), Excel-Dateien, Datenbanken und zum Speichern / Laden von Daten aus dem ultraschnellen HDF5-Format -Zeitserienspezifische Funktionen: Generierung und Frequenzkonvertierung von Datumsbereichen, Statistiken zu beweglichen Fenstern, Datumsverschiebung und Verzögerung.
To load the pandas package and start working with it, import the package.
In [1]: import pandas as pd
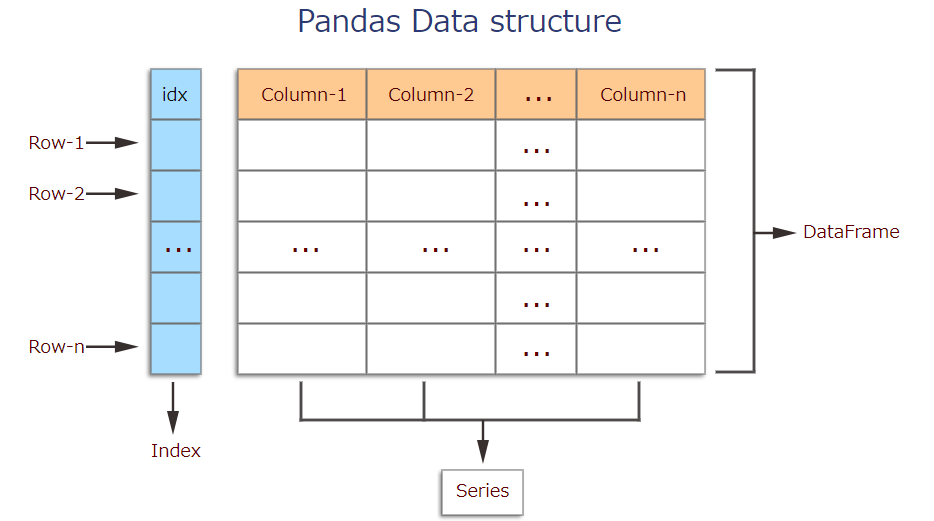
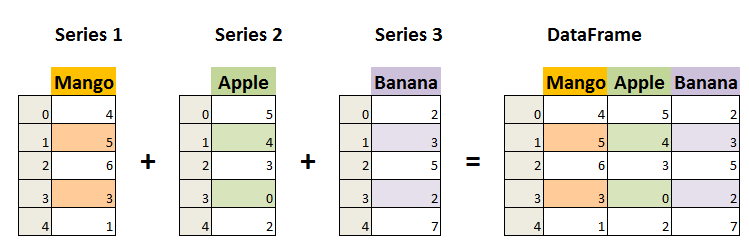
■Creating data The two primary data structures of pandas, Series (1-dimensional) and DataFrame (2-dimensional).Each column in a DataFrame is a Series.
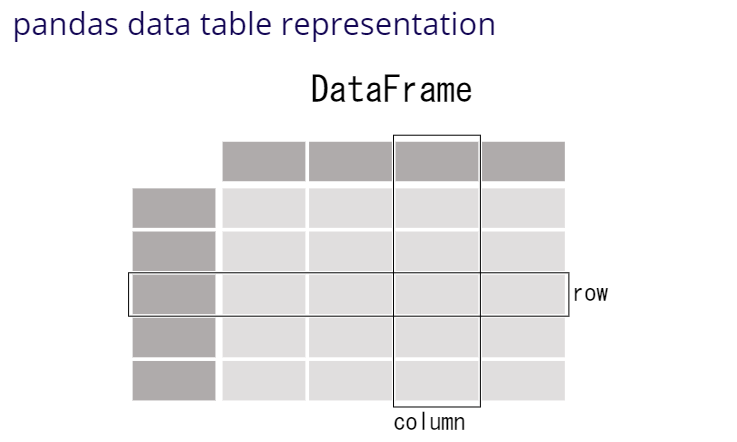
** ・ DataFrame ** A DataFrame is a table. It contains an array of individual entries, each of which has a certain value. Each entry corresponds to a row (or record) and a column. For example, consider the following simple DataFrame:
In [2]: pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})
Out [2]:
| Yes | No | |
|---|---|---|
| 0 | 50 | 131 |
| 1 | 21 | 2 |
DataFrame entries are not limited to integers. For instance, here's a DataFrame whose values are strings:
In [3]: pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']})
Out [3]:
| Bob | Sue | |
|---|---|---|
| 0 | I liked it. | Pretty good. |
| 1 | It was awful. | Bland. |
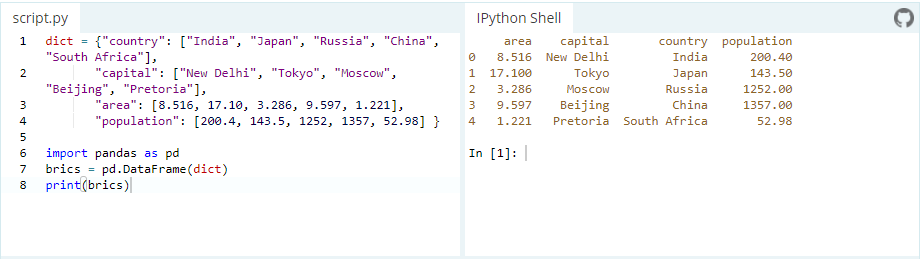
There are several ways to create a DataFrame. One way is to use a dictionary. For example:
** · Serie ** A Series, by contrast, is a sequence of data values. If a DataFrame is a table, a Series is a list. And in fact you can create one with nothing more than a list:
In [4]: pd.Series([1, 2, 3, 4, 5])
Out [4]:
0 1
1 2
2 3
3 4
4 5
dtype: int64
■Reading data files
Another way to create a DataFrame is by importing a csv file using Pandas.
Data can be stored in any of a number of different forms and formats. By far the most basic of these is the humble CSV file. Now, the csv cars.csv is stored and can be imported using pd.read_csv:
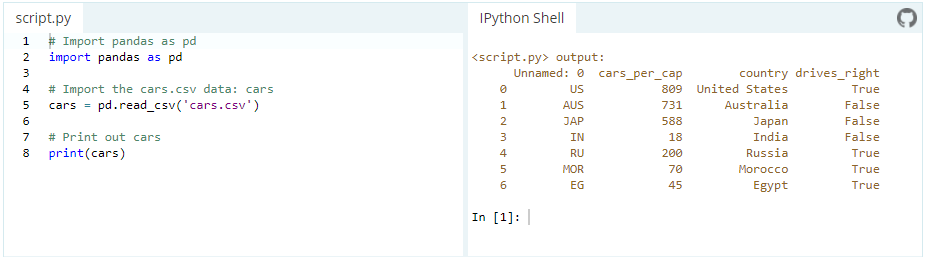
or we can examine the contents of the resultant DataFrame using the head() command, which grabs the first five rows:
In [5]: pd.head()
■ Other Useful Tricks ** ・ Holen Sie sich das aktuelle Arbeitsverzeichnis **
In [6]: import os
In [7]: os.getcwd()
** ・ Überprüfen Sie, wie viele Zeilen und Spalten in den Daten vorhanden sind ** (o/p -> no. of rows, no. of columns)
In [8]: pd.shape
Out [8]: (2200, 15)
** ・ Benennen Sie die Spalten um **
In [9]: pd_new = pd.rename(colums = {'Amount.Requested': 'Amount.Requested_NEW'})
In [10]: pd_new.head()
** ・ Schreiben Sie einen Datenrahmen in CSV oder Excel **
df.to_csv("filename.csv", index = False)
df.to_excel("filename.xlsx", index = False)
There are two ways to handle the situation where we do not want the index to be stored in csv file.
- you can use index=False while saving your dataframe to csv file.
df.to_csv("file_name.csv", index=False)
2 . Or you can save your dataframe as it is with an index, and while reading you just drop the column unnamed 0 containing your previous index.
df.to_csv("file_name.csv")
df_new = pd.read_csv("file_name.csv").drop(['unnamed 0'],axis=1)
here is the cheat-sheet for pandas. https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
Enjoy the Power of Pandas and I hope you found it helpful. Thank you for spending the time to read this article. See you in next topic. :grinning: :grinning:
Recommended Posts